

开源分布式内存数据库-四大开源分布式存储
IndexR:最快的开源大数据存储格式
IndexR 项目包括存储格式、实时存储模块、管理工具和用于连接其他系统(如 Hive 和 Drill)的插件。 其中,IndexR的存储格式是目前最快的开源大数据格式,查询速度最快,扫描速度是Parquet的2到4倍。 加入索引后,查询速度一般提高十倍以上。 适用于大数据的各种场景,包括各种离线和在线统计分析,快速过滤查询。
它最初是作为分析数据库开发的,用于对互联网广告业务产生的海量数据进行实时在线分析。 目前有十几台通用配置的服务器支撑着顺飞科技,其中包括多个业务线,每天近千亿的数据量。 实时入库和在线多维分析系统。
IndexR自开源以来,得到了国内外众多团队的认可,从研究测试到最终部署到生产环境,包括广告、电商、AI等领域的大型互联网公司和创业团队,等等,还有政府、咨询、物流等非常庞大的数据集,对数据质量要求极高的行业。
开源地址:shunfei/indexr
建筑学

IndexR可以与Hadoop生态系统中的各种系统进行协作。 下面是一个典型系统的示意图。
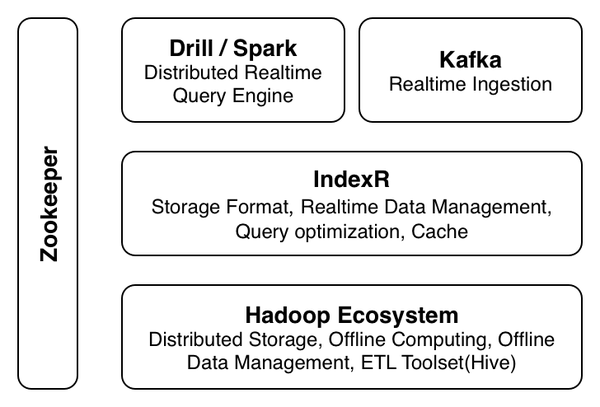
IndexR的特点
在进行具体查询时,IndexR先进行粗糙集索引过滤,然后对剩余的数据集进行倒排索引过滤。 然后将命中包直接加载到内存中,对其进行高效详细的查询。 这种方式解决了分布式架构和海量数据场景下索引难的问题,避免了随机读的问题。 无论是大规模扫描还是小量数据查询开源分布式内存数据库,效率都非常高。
两种存储模式,适用不同场景

支持流式导入,实时分析
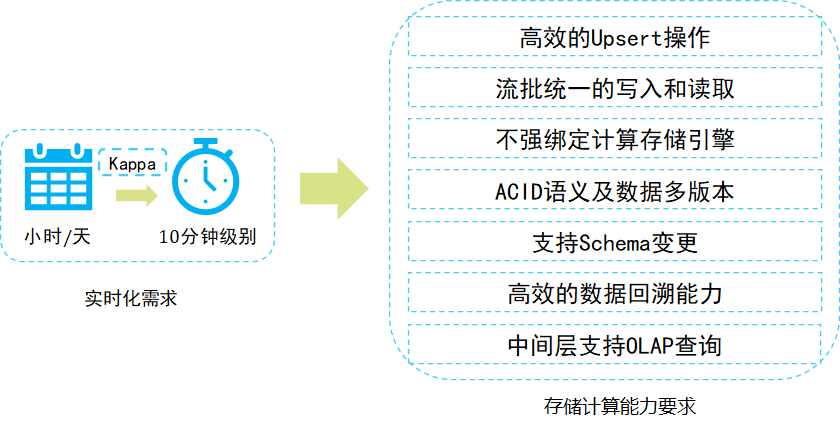
目前的Hadoop生态对于实时数据分析还是比较困难的。 比如Storm和Spark Streaming,这类属于数据的预计算,不能满足业务频繁变化时的需求,或者需要对原始数据进行启发式分析(Ad-hoc)。 Druid、Kudu等系统虽然支持实时写入,但是它们是自成体系的。 在我们的实际应用中,会遇到部署、集成甚至性能方面的问题。
IndexR支持实时数据写入,比如从Kafka导入,数据到达系统后可以立即进行分析。 它与 Hadoop 生态系统的无缝集成使其在业务设计上非常灵活。 目前IndexR中单个表节点的存储速度超过每秒3万条数据,存储速度随节点数量呈线性增长。 每个表使用单独的线程,互不影响。 针对OLAP类型的多维分析场景,IndexR还支持实时和离线预聚合,让分析速度飞起来!
超级快
IndexR采用深度优化的编码方式,极大地加快了数据分析速度,甚至可以媲美一些内存数据库。 其数据组织形式是根据向量化执行的特点定制的,所有数据都存储在堆外内存中,组织方式优化为一个字节,最大限度地减少了JVM的GC和虚函数开销。
IndexR是一种基于Hadoop的数据格式,即文件存储在HDFS中,这样可以很方便的利用HDFS本身的高可用特性来保证数据的安全性,也可以方便的使用所有的分析工具在Hadoop 生态系统。 我们在基于HDFS的文件读取上做了很多优化工作,尽可能将计算分布到距离数据最近的本地节点。 基本消除了HDFS层的开销,和直接读取本地数据没什么区别。
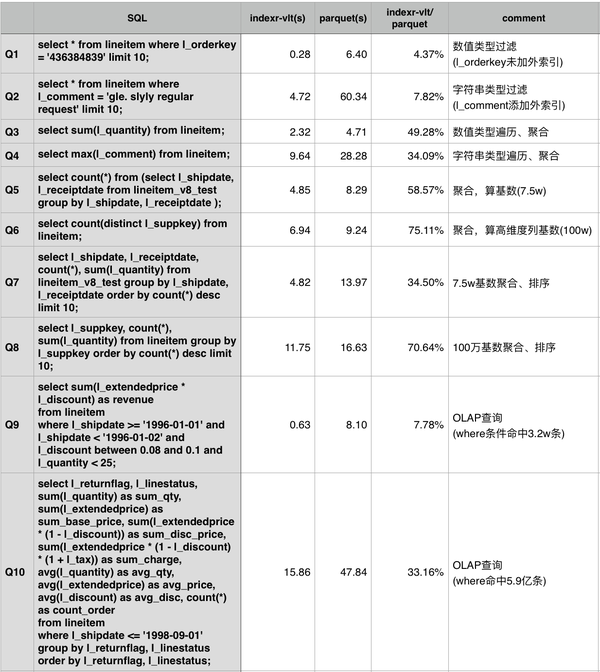
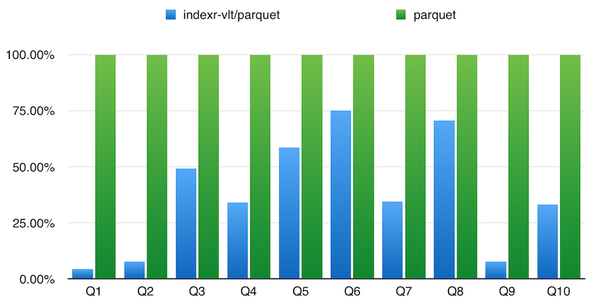
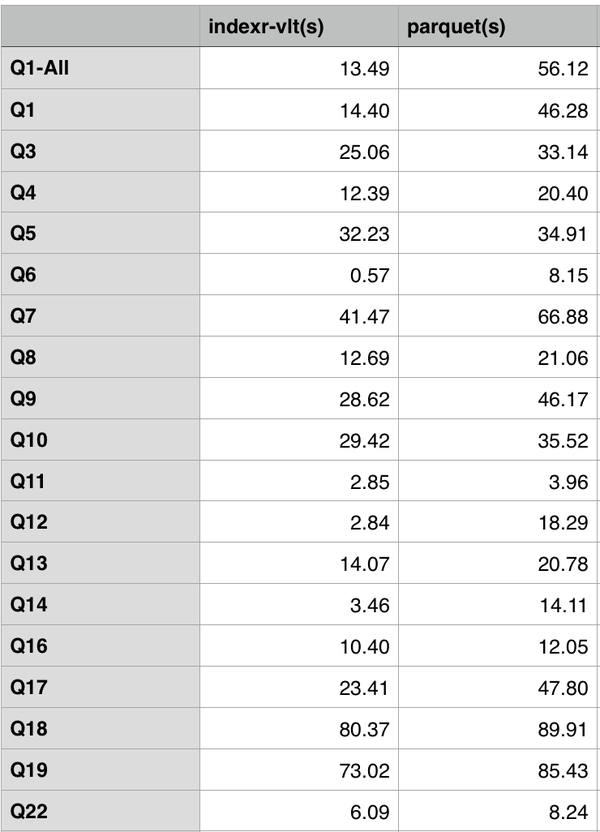
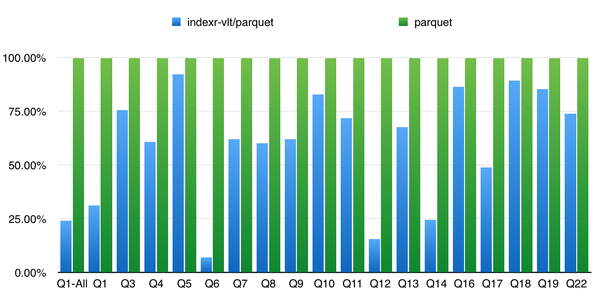
下面是使用 TPC-H 数据集在同一个 Drill 集群上 IndexR 和 Parquet 格式的性能比较。
最大表lineitem的数据总量为6亿,5个节点,节点配置为[Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz] x 2,RAM 64G(实际使用约12G ), 硬盘 SATA 7200RPM。
直方图:
直方图:
省内资源

IndexR 的数据结构经过精心设计,绝不会浪费任何内存空间。 为了避免Java中对象和抽象的开销开源分布式内存数据库,IndexR的代码大量使用了Code C In Java(可笑)的编程风格,通过内存结构而不是接口来解耦。 紧凑的内存结构减少了寻址开销,非常有利于JVM运行时优化。 其结果是 IndexR 在节省内存的同时保证了高性能和有效的索引,这类似于 Parquet 格式查询时的内存占用。 CarbonData 不需要配置大堆内存。 但为什么不直接使用 C 或 C++ 呢? 因为目前最适合Hadoop生态的开发语言是基于JVM的语言,可以和其他系统无缝集成,在工具链支持方面也是最全面的。
通过与Hadoop生态的深度融合,IndexR非常适合在海量数据场景下构建数据仓库。
典型使用场景
IndexR自开源以来,通过不同的团队实践积累了很多用例。 下面介绍一下我们了解到的IndexR在不同公司的几种常见使用方法。
IndexR的未来发展方向
IndexR项目由顺飞科技开源并快速推进,目前已发布0.5.0版本。 IndexR立志成为Hadoop生态中快速分析查询的标准存储格式。 希望能得到业界更多的关注和使用,社会各界更积极的参与。
 上一篇
上一篇 








