

人工智能并行算法-并行禁忌算法
目前,人工智能领域已成为最受关注的热点之一。人工智能领域是通过对计算机的研究与开发,使得其具备类似于人类智能的,对环境的输入做出有意义的判断反应的研究应用领域。决定人工智能质量的因素往往是计算能力以及数据量的大小,而实现人工智能的方式则是机器学习,让机器通过训练和学习逐渐逼近我们希望其实现的效果。随着处理器能力以及数据量的飞速增长,机器学习的方式也在发生革命性的变化,深度学习的概念被引入。深度学习由于其多层次形态,从而增强了其非线性程度,可以带来更强的拟合能力。此外,其类似于仿生学的逐层自动提取特征的过程,保证了所提取特征的质量与丰富性,使得其性能相较于传统的机器学习算法有了质的提升。

随着模型算法的发展,模型所能实现的性能逐步提升, 而模型本身的深度和复杂度也大大增加。以大规模图像识别竞赛(ILSVRC)为例,2012年多伦多大学的Alex Krizhecsky 随同其倒是Geoffrey Hinton 发布的 AlexNet 以83.0%的Top5分类准确率夺得冠军,相较于之前传统模型的最佳性能提升了百分之十几。AlexNet 本身是一个具有5层卷积层和3层全连接层的卷积神经网络,包含有6100万个权重参数和7.24亿次乘加运算。2017年为止,最复杂的网络模型层数已超过1000层,权重参数及乘加运算次数都比AlexNet提升了几个数量级,而所能实现的识别准确率也已经超越人眼。

对于最近打败众多人类围棋高手的阿尔法围棋(AlphaGo),在其打败李在石的第一版分布式实现版本中,其复杂的决策算法模型需要1300多个CPU和280个GPU来提供算力的支撑。由此可见,面对日益复杂的人工智能算法,要满足严格的功耗与实时性需求,需要有强大的处理器作为支持;因此对处理器芯片的精细化设计,成为提升芯片计算功能,满足应用需求的必要条件。
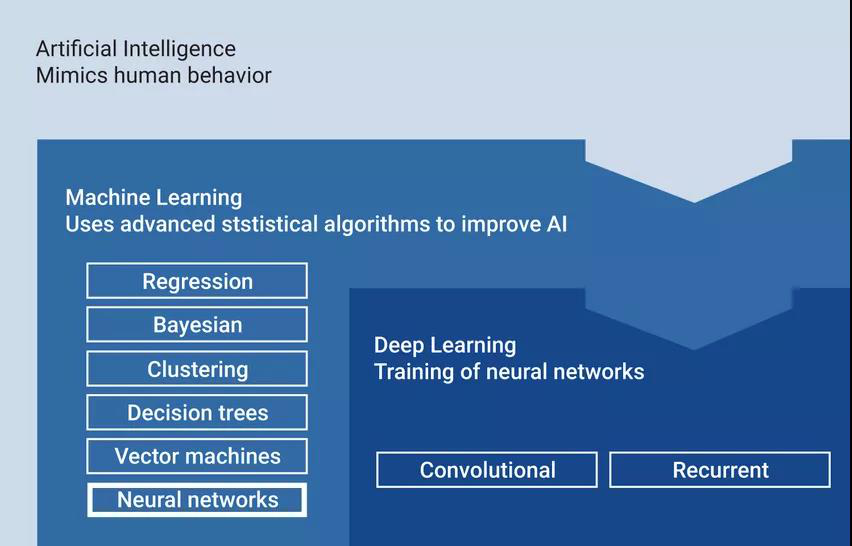
通常来讲,无论是对于人工智能的模型训练还是前向推断应用过程,处理器芯片的计算速度都是需要首先考虑的指标;而在某些诸如嵌入式移动端的低功耗场景中,对于硬件计算的功耗也需要加以严格的控制。传统的CPU由于其串行执行的方式,在应对数据与计算密集型的人工智能算法时显得捉襟见肘。因此人工智能并行算法,增加处理器计算的并行度成为性能提升的一个主要方向。英伟达提出了通用计算GPU(GPGPU)的概念,将具有大量可并行计算流处理器的GPU运用到人工智能算法的研发过程中, 并提供了成熟而稳定的诸如CUDA和cuDNN的软件环境支持。由于GPU强大的计算能力,在关注模型准确度和以数据中心及服务器环境为主的模型训练场景中,GPU得到了广泛的应用。但同时我们也注意到,常见的GPU板卡功耗高达200-300W,这使得其在需要低功耗场景中的应用受到局限。因此,针对应用场景和算法类型,对芯片内部结构进行定制化的设计,从而提升芯片整体的能效比,成为人工智能芯片发展的另一主流方向。

通常而言,对于某一类型的人工智能算法人工智能并行算法,其往往具备可划分的特性,并且划分的子算法块具有一定的相似性。以图像应用中常见的卷积神经网络为例,运算最密集的卷积层就可以抽象为滑窗类型的乘加操作,而滑窗的大小及步幅,计算通道数的大小等均可以被抽象为可配置的参数。在硬件结构的设计过程中,往往会针对算法划分及抽象的方式,在计算通路和存储结构上进行定制化,可配置的设计。大部分研究者会采用FPGA芯片实现的方式,快速地迭代开发出加速硬件结构。多家研究机构已纷纷在顶级学术会议上发布了基于FPGA的加速结构设计,而业界企业也都开始将常见的算法模型通过FPGA加速器实现的形式部署到应用端,并且实现了较好的性能和较低的功耗。下一步,我们也可以将计算及存储核心部分进行电路固化,以专用集成电路(ASIC)的方式实现,以达到更高的能效比。目前已知的优秀ASIC芯片设计,已能在实现数百GOPS(每秒十亿次运算数)级别计算能力的情况下将功耗控制在毫瓦级别。ASIC在具备广泛应用市场的前提下,具有高能效比,量产成本低的诸多优势,但其一次性的工程费用及较大的开发成本,在快速的算法演进过程中往往会具有一定风险。因此,针对不同的研发及市场需求,应该选取不同的平台予以实现。

近年来,针对硬件实现的算法优化也在不断发展,包括数据量化,模型稀疏化等多项技术都取得了进展;而这些技术都有助于降低人工智能芯片的片上计算资源及存储带宽限制,以更低的硬件代价实现更高的吞吐速率。而数据位宽变化以及模型稀疏带来的不规则性,则对硬件结构的实现提出了挑战。未来的人工智能芯片设计,将更趋向于软硬件协同设计的模式,从软硬件两个方向分别进行限制条件的考量以及优化路径的选取,从而实现更优化,更通用的解决方案。
 上一篇
上一篇 








