

卷积神经网络java-bp神经网络的卷积过程

LeNet-5 模型
在CNN的应用中,文本识别系统中使用的LeNet-5模型是一个非常经典的模型。 LeNet-5模型由Yann LeCun教授于1998年提出,是第一个成功大规模应用于手写数字识别问题的卷积神经网络。 MNIST数据集中的正确率可以高达99.2%。
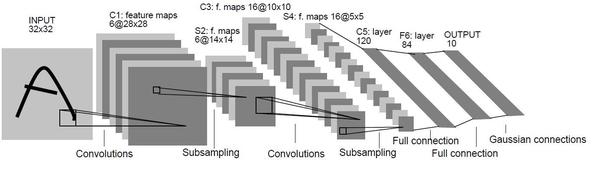
下面详细介绍LeNet-5模型的工作原理。
LeNet-5模型一共7层,每一层包含很多参数,这些参数是卷积神经网络中的参数。 虽然层数只有7层,在如今庞大的神经网络中已经很少了,但是它包括了卷积层、池化层和全连接层。 可以说,麻雀虽小,五脏俱全。 为了方便起见,我们将卷积层称为C层,将下采样层称为下采样层。
首先,输入层输入原始图像,将原始图像处理成32×32像素的值。 然后,后续隐藏层在卷积和子采样之间交替。 C1 层是一个包含六个特征图的卷积层。 每个图都是 28x28 个神经元。 卷积核可以是 5x5 的十字形。 这些 28×28 的神经元共享卷积核的权重参数。 通过卷积运算,增强了原始信号的特征,同时也降低了噪声。 当卷积核不同时,提取的图像中的特征不同; C2层是一个池化层。 上面已经介绍了池化层的作用。 它对局部像素值取平均 来实现子采样。
池化层包含六个特征图,每个图的像素值为14x14。 这样的池化层非常重要,可以保证在一定程度上提取网络的特征,同时计算量也大大减少,减少了网络结构。 过度拟合的风险。 由于卷积层和池化层交替出现,隐藏层的第三层又是一个卷积层,第二个卷积层由16个特征图组成,每个特征图用于加权求和计算。 卷积核为 10x10。 第四个隐藏层,也就是第二个池化层,也包含了16个feature maps,每个feature maps使用的卷积核是5x5。 第五隐藏层采用5x5的卷积核进行运算,包含120个神经元,也是该网络的最后一层卷积运算。
之后的第六层是全连接层,包含 84 个特征图。 在全连接层中,对输入进行点积后,加上偏置,再通过激活函数传递给输出层的神经元。 最后一层,也就是第七层,为了得到输出向量,设置了十个神经元进行分类,相当于输出一个包含十个元素的一维数组,向量中的十个元素为0到9.
AlexNet模型介绍AlexNet
在2012年Imagenet图像识别大赛中,Alext提出的Alexnet网络模型一鸣惊人,点燃了神经网络应用的热潮,获得了2012年图像识别大赛的冠军,也让卷积神经网络成为了真正的图像处理领域. 核心算法。 上面介绍的LeNet-5出现在上个世纪。 虽然是经典,但受各种复杂现实场景的限制,只能在部分领域应用。 但随着SVM等手工设计特征的快速发展,LeNet-5并未形成较大的应用现状。 随着ReLU和dropout的提出,以及GPU带来的算力突破和互联网时代大数据的爆发,卷积神经网络带来了历史性的突破,AlexNet的提出让深度学习走上了前沿。人工智能。
图像预处理
AlexNet的训练数据使用ImageNet子集中的ILSVRC2010数据集,包含1000个类别,总共120万张训练图片卷积神经网络java,5万张验证集,15万张测试集。 在网络训练之前,我们需要对数据集图像进行预处理。 首先,我们需要将所有不同分辨率的图片转换成256x256的图片。 变换方法是将图片的短边缩放为256个像素值,然后截取长边中间的256个像素值 得到256x256大小的图像。 除了对图片尺寸进行预处理外,还需要对图片进行减去均值处理。 一般图像由RGB三基色组成,根据RGB的三个分量取均值,这样可以更突出图片的特征,也更方便后续的计算。
另外,为了保证训练的效果,我们还需要对训练数据进行更严格的处理。 在256x256尺寸的图片中,截取227x227尺寸的图片,然后对图片做镜像,将原始数据增加了(256-224) x (256-224) x2 = 2048倍。 最后对RGB空间进行PCA,然后对主成分进行(0,0.1)的高斯扰动,错误率降低1%。 对于测试数据,提取图像4个角的大小为224224的图像,中心大小为224224的图像,以及它们的镜像翻转图像,这样可以得到10张图像,我们可以使用softmax来predict,对所有的预测进行平均,作为最终的分类结果。
ReLU 激活函数
我们之前提到,常用的非线性激活函数是sigmoid,它可以确定输入在0到1之间的所有连续实数值 。但这带来了一个问题。 当负数的绝对值很大时,输出为0; 如果是一个绝对值非常大的正数,则输出为1。这会导致饱和现象。 在饱和现象下,神经元的梯度会变得极小,这必然会增加网络的学习难度。 另外,sigmoid的输出值不是0作为均值,因为这会导致前一层输出的非零均值信号直接输入到后一层的神经元。 所以AlexNet模型提出了ReLU函数,公式:f(x)=max(0,x)f(x)=max(0,x)。
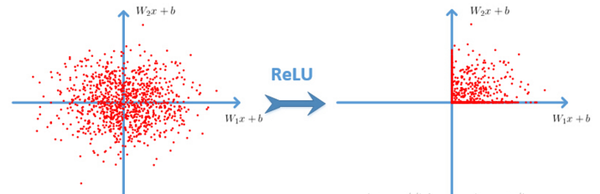
使用ReLU代替Sigmoid,发现使用ReLU得到的SGD的收敛速度比sigmoid快很多,这也成为了AlexNet模型的优势之一。
辍学
AlexNet 模型提出了一种有效的模型组合方法。 与单个模型相比,只需要两倍的时间,这种方法称为Dropout。 在整个神经网络中,随机选择一半的神经元,将它们的输出变为0。这样,网络关闭了一些神经元,减少了过拟合。 同时,训练的迭代次数也增加了。 当时一块GTX580 GPU只有3GB显存,无法进行大规模计算。 但是随着硬件水平的发展,当时的GPU已经可以实现并行计算。 并行计算后,两个GPU可以相互通信传输数据。 该方法充分利用了GPU资源,因此模型设计采用两块GPU进行并行计算。 运行效率大大提高。
模型分析
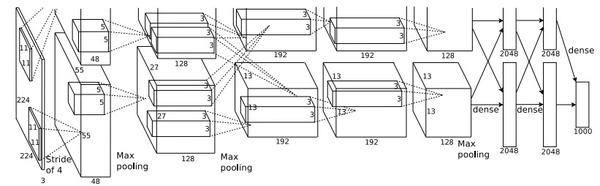
AlexNet模型一共8层,其中前5层为卷积层,前2个卷积层和第5个卷积层有池化层,其他卷积层没有。 接下来的三层是全连接层,大约有65万个神经元,需要训练的参数大约有6000万个。
经过图像预处理,进入第一个卷积层C1后,原图变成了55x55的像素大小,此时一共有96个通道。 为了方便GPU计算,模型分为上下两部分,48作为通道数更适合GPU并行计算。 在上面的模型中,48层直接变成了一个面,这使得模型看起来更像一个大小为55x55x48的立方体。 在后面的第二个卷积层C2中,卷积核的大小为5x5x48,所以又进行了一次卷积操作。 在C1和C2卷积层的卷积运算之后,会有一个池化层,大大降低了特征提取后特征图的像素值,便于运算,使特征更加明显。 第三个卷积层 C3 更加特殊。 第三个卷积层合并通道,将前面两个通道的数据再次合并,这是一个连接操作。 第三层之后,由于串行连接,通道数变为256。全卷积的卷积核大小变为13×13×25613×13×256。 一个4096个这样大小的卷积核分别对输入图像进行4096次全卷积运算,最后的结果是一个总共有4096个数的列向量。 这是最后的输出,但是AlexNet最后分成了1000个类,所以通过第八层,也就是全连接的第三层,得到了1000个类的输出。
Alexnet 网络中的每一层都扮演着不同的角色。 ReLU 和多个 CPU 用于提高训练速度。 Overlapping pool pooling用于提高准确率,不易过拟合。 局部归一化响应用于提高准确性。 数据增益和丢失用于减少过度拟合。
VGG网
在ILSVRC-2014中,牛津大学视觉几何组提出的VGGNet模型在定位任务中排名第一,在分类任务中排名第一]。 如今在计算机视觉领域,卷积神经网络的良好效果受到开发者的青睐,而前面提到的AlexNet模型效果更佳,因此广大从业者和学习者都试图对其进行改进以获得更好的效果。 后来很多人验证,AlexNet模型中所谓的locally normalized response浪费了计算资源,但并没有大幅提升性能。 VGG的本质是AlexNet结构的增强版,在卷积神经网络的设计上强调了深度。 将卷积层的深度增加到19层,在当年的ImageNet比赛中获得了定位问题的第一名。 整个网络已经向人们证明了我们可以用一个小的卷积核来达到很好的效果,前提是我们需要加深网络的层数,这也说明了我们想要提升整个神经网络的模型效果. 一个有效的方法是加深它的深度。 虽然计算量会大大增加,但是整体的复杂度也会增加,可以更好的解决复杂的问题。 虽然VGG网络已经诞生好几年了,但是在很多其他网络的效果都不是很好的时候,VGG有时可以充分发挥自己的优势,让人有意想不到的收获。
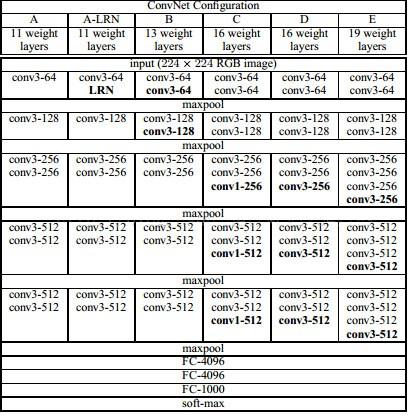
与 AlexNet 网络非常相似,VGG 一共有五个卷积层,每个卷积层后面跟着一个池化层。 当时在ImageNet比赛中,作者尝试了六种网络结构。 这六种结构大致相同,只是层数不同,从11层到19层之多。 网络结构的输入是大小为224*224的RGB图像,最后输出分类结果。 当然,在进入网络的时候,图片是需要进行预处理的。
与AlexNet网络相比,VGG网络在网络的深度和宽度上都有一定的扩展,具体的卷积操作与AlexNet网络类似。 我们主要说明 VGG 网络所做的改进。 第一,因为很多研究者发现归一化层的效果不是很好,而且占用了很多计算资源,所以作者取消了VGG网络中的归一化层; 其次,VGG网络使用了更小的3x3卷积核,两个连续的3x3卷积核相当于一个5x5的感受野,以此类推,三个3x3连续的卷积核相当于一个7x7的感受野。 这样的改变使得参数量变小,节省了计算资源,为后面更深的网络留下了资源。 第三点,VGG网络中的池化层特征池化核改为2x2,而AlexNet网络中的池化核为3x3。 这三项改进无疑减少了整个参数的计算量,使我们能够在有限的计算平台上为更深层次的网络获取更多的资源。 由于层数较多,卷积核相对较小,整个网络的特征提取效果非常好。 事实上,由于VGG的层数较多,计算量还是相当大的,卷积层数多成为其最显着的特点。 另外,VGG网络的扩展性能比较突出,结构比较简单,所以迁移性能比较好,迁移到其他数据集时泛化性能好。 直到现在,VGG 网络经常被用来提出特征。 所以当现在很多新模型不能很好地工作时,使用 VGG 可能会解决这些问题。

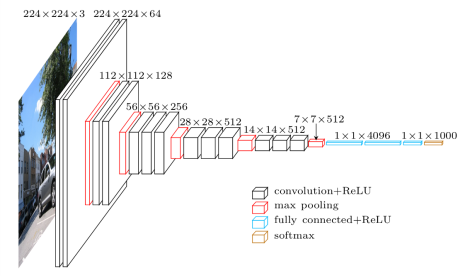
谷歌网
Google 在 2014 年 ImageNet 挑战赛(ILSVRC14)中凭借 GoogleNet 再次获得第一名。 这通过增加神经网络的深度和宽度来获得更好的结果,同时在此过程中保持计算资源不变。 该网络表明,增加深度、宽度和训练数据是现有深度学习取得更好结果的主要途径。 但是增加size可能会出现过拟合的问题,因为depth和width的加深必然会带来过多的参数。 此外,增加网络规模也带来了过多侵占计算资源的缺点。 为了在保证充分利用计算资源的前提下提升整个模型的性能,作者采用了Inception模型,如下图所示。 可以看出,这个有点像金字塔的模型卷积神经网络java,使用了宽度大小不同的并行卷积核。 ,增加卷积核的输出宽度。 因为使用了更大规模的卷积核来增加参数。 使用1*1的卷积核是为了尽量减少参数的数量。
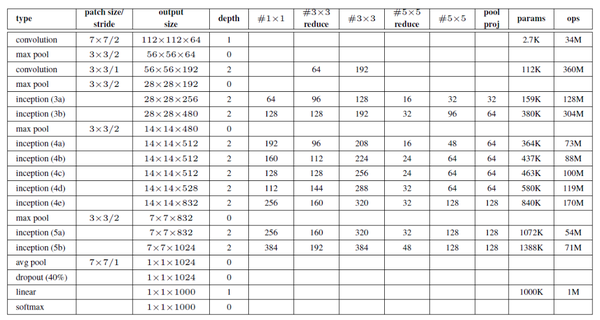
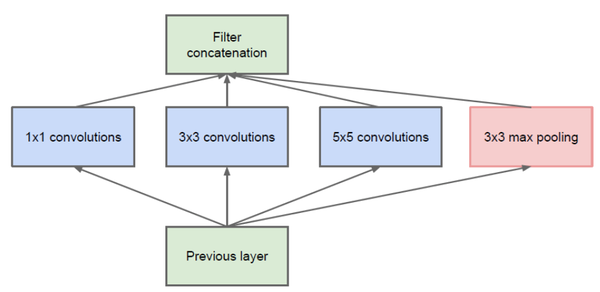
启动模块
上表是网络分析图,第一行是卷积层,输入224×224×3,卷积核7x7,步长2,padding 3,输出维度112× 112×64。 7x7卷积用了7×1,再用1×7,所以有(7+7)×64×3=2688个参数。 第二个行为是池化层,卷积核为3×33×3,滑动步长为2,padding为1,输出维度:56×56×64,计算方式:1/2×(112+ 2×1− 3+1)=56。 第三行和第四行与第一行和第二行类似。 第五行,Inception模块分为4个分支,输入为上层生成的28×28×192。 结果:Part 1,1×1卷积层,输出大小为28×28×64; Part 2,第一个1×1卷积层,输出大小为28×28×96,作为3×3卷积层的输入,输出大小为28×28×128; 第三部分,第一个1×1的卷积层,输出大小为28×28×32,作为一个3×3卷积层的输入,输出大小为28×28×32; 第三部分的3×3池化层,输出大小为28×28×32。 第5行的Inception模块会将上述结果的输出并联起来,从而增加网络宽度。
ResNet
在2015年的ImageNet比赛中,MSRA何凯明团队的ResidualNetworks力压群雄,获得了ImageNet多个领域比赛的第一名,而这篇关于ResNet Deep Residual Learning for Image Recognition的论文也获得了CVPR2016的best paper当之无愧姓名。
上面介绍的VGG和GoogleNet都是通过增加卷积神经网络的深度来达到更好的效果,让人明白网络的深度和广度决定了训练的效果。 但同时,随着宽度和深度的加深,效果其实会逐渐变差。 也就是说,模型的层级加深了,错误率增加了。 模型深度加深,学习能力增强,换来一定的错误率。 但是深度神经网络模型牺牲了大量的计算资源,学习能力应该不会比浅层神经网络高。 这种现象主要是由于随着神经网络层数的增加,梯度消失现象越来越明显。 所以为了解决这个问题,作者提出了一种深度残差网络结构Residual:

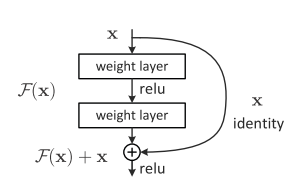
上图是残差网络的基本结构。 可以看出实际上是加入了恒等映射,将原来的变换函数H(x)转化为F(x)+x。 在示意图中可以清楚地看到整个网络的变化,让网络不再是简单的堆叠结构,解决了网络层数增加带来的梯度不太明显的问题。 所以这个时候,网络可以做得很深。 到目前为止,网络的层数可以达到几千层,可以保证很好的效果。 而且这种简单的叠加并没有给网络增加额外的参数和计算,也提高了网络训练的效果和效率。
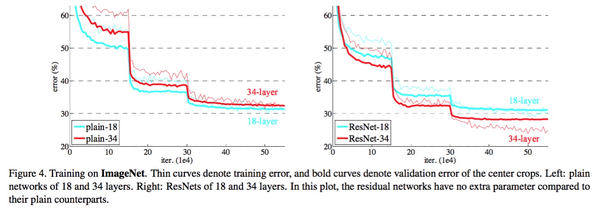
在比赛中,为了证明自己的观点是正确的,作者设计了几个变量控制的实验。 首先,作者构建了两个分别为18层和34层的普通网络,然后作者设计了两个分别为18层和34层的残差网络。 然后对这四种模型进行控制变量实验,观察数据量的变化。 下图是实验结果。 在实验中,在普通网络上观察到明显的退化现象。 实验结果也表明,在残差网络上,34层的效果明显好于18层,这足以证明残差网络的性能随着层数的增加而提高。 不仅如此,残差网络在更深层结构中的收敛性能也得到了显着提升,整个实验取得了巨大的成功。
此外,作者还对shortcut方法进行了实验。 如果残差网络模块的输入和输出维度不一致,想要统一维度,就必须增加较小维度的维度。 增维最好的效果就是用0填充。但是实验数据表明,三者之间的差距很小,所以线性投影并不是特别必要。 使用 0 填充维度还可以确保模型的复杂度保持在较低水平。
随着实验的深入,作者提出了更深的残差模块。 该模型减少了每一层的参数量,为更深层的模型留出了资源。 在保证低复杂度的情况下,模型没有明显的梯度消失,所以目前的模型最多可以达到1202层,错误率仍然保持很低。 但是如此多的层数也带来了过拟合的现象,不过很多研究者还在改进中。 毕竟此时的ResNet相比其他模型在性能上是遥遥领先的。
残差网络的本质是捷径。 从某种角度看,也可以理解为多条路径组成的网络。 如下所示:
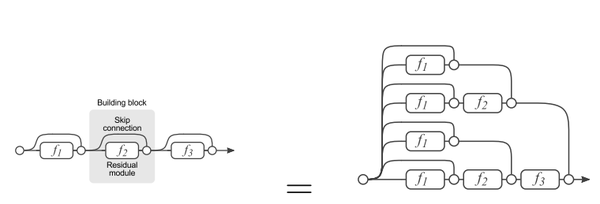
ResNet可以很深,但是从上图我们可以了解到,当网络很深,也就是层数很多的时候,数据传输的路径其实是比较固定的。 我们似乎也可以理解为多人投票系统,大部分梯度分布在论文中所谓的有效路径上。
密集网络
在Resnet模型之后,有人试图改进ResNet模型,于是ResNeXt模型诞生了。
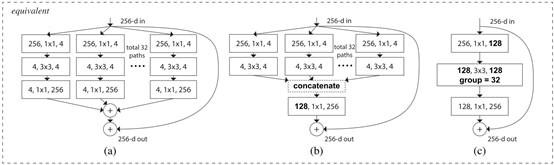
这是上面介绍的ResNet模型结合了GoogleNet中inception模块的思想,比Resnet更有效。 随后,诞生了DenseNet模型,直接将所有模块连接起来,整个模型更加简单粗暴。 密集连接成为其主要特征。

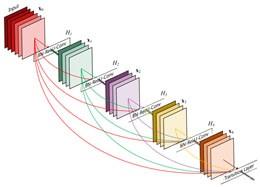
我们将 DenseNet 与 ResNet 进行比较:
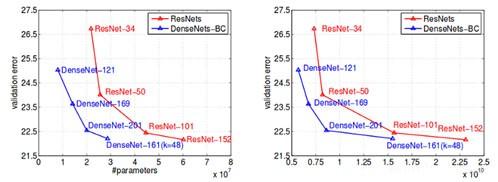
从上图可以看出,与ResNet相比,DenseNet的参数明显更少,结果更好,但是DenseNet需要消耗更多的内存。
总结
以上介绍了卷积神经网络发展史上比较著名的一些模型。 这些款式都非常经典,各有千秋。 现在随着计算能力的不断提升,各种新型网络训练的效率和效果也在逐步提升。 从收敛速度来看,VGG>Inception>DenseNet>ResNet,从泛化能力来看,Inception>DenseNet=ResNet>VGG,从计算量来看,Inception
 上一篇
上一篇 








