

爬虫软件开发-零基础自学用python 3开发网络爬虫
文章目录 1.什么是爬虫? 2、爬虫数据到哪里去了? 1. Present 2. Analyze 3. 所需软件及环境 1. Pycharm2. Chrome开发者工具 3. XPath Helper 4. 其他工具 4. 浏览器请求总结 1. 什么是爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常被称为网络追赶者)是一种按照一定规则自动抓取万维网上信息的程序或脚本。 其他不太常用的名称包括 ant、autoindex、emulator 或 worm。 ——《百度百科》
爬虫是一种模拟客户端(浏览器)发送网络请求爬虫软件开发,获取响应,并按照规则提取数据的程序。
浏览器的工作原理就是获取请求并渲染响应,所以才能如此炫酷的呈现在用户面前。 其实如果直接把获取到的response显示出来,就是一堆冷代码。 不同的浏览器对同一段代码的解释不同,这就是为什么有些网页在手机上打开和在电脑上打开会有不同的效果。
所以,爬虫换成更容易理解的说法,就是伪装成浏览器,欺骗服务器响应的数据,并对其进行特殊处理,简单来说,就是让服务器认为你是浏览器,然后把数据给你。 ,结果你拿着数据违背常理出牌了。 您必须使用其他方法来提炼和简化数据并将其用于您自己。
~突然觉得爬虫流行的说话方式有点像马姓高手创作的武林巨作。 在短时间内大量连续访问同一站点的许多页面)。 “接收”响应爬虫软件开发,根据规则提取和转换,最后在必要时“发送”提取的数据(如发送到数据库等)。 “接收”-“转化”-“头发”一气呵成,“训练有素”~
最后不得不提一句,爬虫虽然爽,但是适可而止,小心出问题。作为一个刚刚接触爬虫技术的新手,博主找到了一篇关于爬取数据是否违法的好文章。 通俗易懂,分享给大家:爬虫是合法的还是非法的? 让我们互相鼓励

2、爬虫数据到哪里去了? 1. 呈现
一般是呈现在网页上,显示在APP上,或者保存在本地做其他用途。 一般来说,爬虫获取的数据总量是巨大的,使得用户能够非常快速地获取到大量的信息数据,大大节省了大量的人力物力。
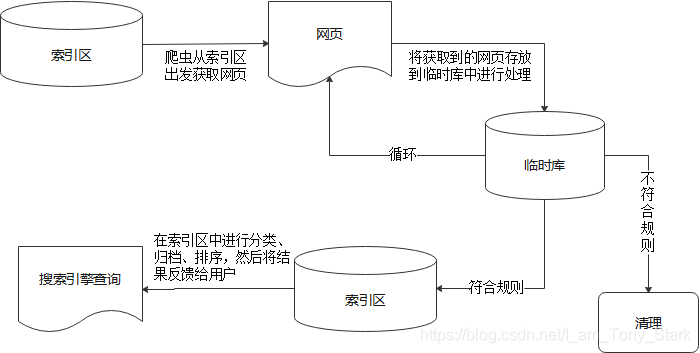
举个最简单的例子,百度是爬虫高手。 百度是目前中国最大的搜索引擎,拥有一套完整的抓取算法。 我们可以从下图详细了解百度蜘蛛抓取网页的整个过程和系统。
2. 进行分析
对收集到的数据进行统计、计算和分析。 今年流行的大数据分析师,顾名思义,他们的工作就是对大量数据进行数学建模和分析,从而得出更有用的结论。 而几千万的数据显然不是人工录入的,需要依赖爬虫。 比如这里是一个python爬虫数据分析可视化金融实战系统。
(不是我写的,我也希望自己有一天也能有这种技能)
三、所需软件及环境 1.Pycharm
由 JetBrains 团队开发的用于开发 python 应用程序的 IDE
-截至2020年11月27日,个人测试有效-
下载
破解
汉化
当然Java或者其他编程语言理论上都可以实现爬虫,但是博主就是喜欢Python语言的简单方便,所以本篇及后续文章都会使用Python语言作为爬虫开发语言。 由于篇幅原因,本文将不再介绍Python的基本语法和通用算法和数据结构。
2. Chrome 开发者工具
Google Chrome 内置的一套 Web 开发和调试工具,可用于网站的迭代、调试和分析。
百度搜索Chrome,下载吧
因为很多国产浏览器内核都是基于Chrome内核的,所以国产浏览器也有这个功能。 不过,说到网页分析,谷歌的Chrome绝对是一把利剑,开发者工具的便捷性完胜“*狗浏览器”或“口口浏览器”等国产浏览器(没有引战的意思)技能确实不如别人,我们不得不承认,努力学习,努力突破才是正道。)
 上一篇
上一篇 








