

汉字制作广告语音合成软件-汉语语音合成技术之语言分析部分的流程图
一,语音合成技术原理
语音合成(text to speech),简称TTS。将文字转化为语音的一种技术,类似于人类的嘴巴,通过不同的音色说出想表达的内容。
在语音合成技术中,主要分为语言分析部分和声学系统部分,也称为前端部分和后端部分,语言分析部分主要是根据输入的文字信息进行分析,生成对应的语言学规格书,想好该怎么读;声学系统部分主要是根据语音分析部分提供的语音学规格书,生成对应的音频,实现发声的功能。
1.语言分析部分
语言分析部分的流程图具体如下,可以简单的描述出语言分析部分主要的工作。
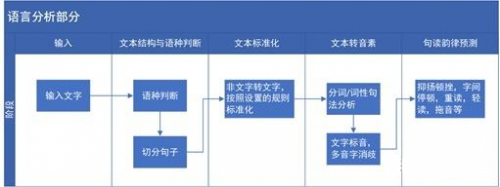
文本结构与语种判断:当需要合成的文本输入后,先要判断是什么语种,例如中文,英文,藏语,维语等,再根据对应语种的语法规则,把整段文字切分为单个的句子,并将切分好的句子传到后面的处理模块。
文本标准化:在输入需要合成的文本中,有阿拉伯数字或字母,需要转化为文字。根据设置好的规则,使合成文本标准化。例如, “请问您是尾号为8967的机主吗?” “8967”为阿拉伯数字,需要转化为汉字“八九六七”,这样便于进行文字标音等后续的工作;再如,对于数字的读法,刚才的“8967“为什么没有转化为”八千九百六十七“呢?因为在文本标准化的规则中,设定了”尾号为+数字“的格式规则,这种情况下数字按照这种方式播报。这就是文本标准化中设置的规则。
文本转音素:在汉语的语音合成中,基本上是以拼音对文字标注的,所以我们需要把文字转化为相对应的拼音,但是有些字是多音字,怎么区分当前是哪个读音,就需要通过分词,词性句法分析,判断当前是哪个读音,并且是几声的音调。
例如,“南京市长 江大桥”为“nan2jing1shi4zhang3jiang1da4qiao2”或者“南京市 长江大桥”“nan2jing1shi4chang2jiang1da4qiao3”。
句读韵律预测:人类在语言表达的时候总是附带着语气与感情,TTS合成的音频是为了模仿真实的人声,所以需要对文本进行韵律预测,什么地方需要停顿,停顿多久,哪个字或者词语需要重读,哪个词需要轻读等,实现声音的高低曲折,抑扬顿挫。
2.声学系统部分
声学系统部分目前主要有三种技术实现方式,分别为:波形拼接,参数合成以及端到端的语音合成技术。

1)波形拼接语音合成
通过前期录制大量的音频,尽可能全的覆盖所有的音节音素,基于统计规则的大语料库拼接成对应的文本音频,所以波形拼接技术通过已有库中的音节进行拼接,实现语音合成的功能。一般此技术需要大量的录音,录音量越大,效果越好,一般做的好的音库,录音量在50小时以上。

优点:音质好,情感真实。
缺点:需要的录音量大,覆盖要求高,字间协同过渡生硬,不平滑,不是很自然。
2) 参数语音合成技术
参数合成技术主要是通过数学方法对已有录音进行频谱特性参数建模,构建文本序列映射到语音特征的映射关系,生成参数合成器。所以当输入一个文本时,先将文本序列映射出对应的音频特征,再通过声学模型(声码器)将音频特征转化为我们听得懂的声音。
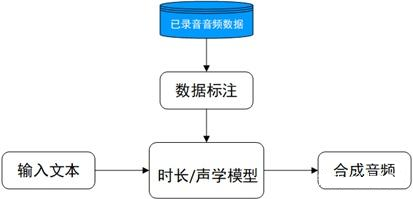
优点:录音量小,可多个音色共同训练,字间协同过渡平滑,自然等。
缺点:音质没有波形拼接的好,机械感强,有杂音等。
3) 端到端语音合成技术
端到端语音合成技术是目前比较火的技术,通过神经网络学习的方法,实现直接输入文本或者注音字符 ,中间为黑盒部分,然后输出合成音频,对复杂的语言分析部分得到了极大的简化。所以端到端的语音合成技术,大大降低了对语言学知识的要求,且可以实现多种语言的语音合成,不再受语言学知识的限制。通过端到端合成的音频,效果得到的进一步的优化,声音更加贴近真人。


优点:对语言学知识要求降低,合成的音频拟人化程度更高,效果好,录音量小。
缺点:性能大大降低,合成的音频不能人为调优。
以上主要是对语音合成技术原理的简单介绍,也是目前语音合成主流应用的技术。当前的技术也再迭代更新,像端到端技术目前比较火的wavenet,Tacotron,Tacotron2以及deepvoice3等技术,感兴趣的朋友可以自己了解学习。
二,技术边界
目前语音合成技术落地是比较成熟的,比如前面说到的各种播报场景,读小说,读新闻以及现在比较火的人机交互。但是目前的TTS还是存在着一些解决不掉的问题。
1.拟人化
其实当前的TTS拟人化程度已经很高了,但是行业内的人一般都能听出来是否是合成的音频,因为合成音的整体韵律还是比真人要差很多,真人的声音是带有气息感和情感的,TTS合成的音频声音很逼近真人,但是在整体的韵律方面会显得很平稳,不会随着文本内容有大的起伏变化,单个字词可能还会有机械感。
2.情绪化
真人在说话的时候,可以察觉到当前情绪状态,在语言表达时,通过声音就可以知道这个人是否开心,或者沮丧,也会结合表达的内容传达具体的情绪状态。单个TTS音库是做不到,例如在读小说的时候,小说中会有很多的场景,不同的情绪,但是用TTS合成的音频,整体感情和情绪是比较平稳的,没有很大的起伏。目前优化的方式有两种,一是加上背景音乐,不同的场景用不同的背景音乐,淡化合成音的感情情绪,让背景音烘托氛围。二是制作多种情绪下的合成音库,可以在不同的场景调用不同的音库来合成音频。
3.定制化
当前我们听到语音合成厂商合成的音频时,整体效果还是不错的,很多客户会有定制化的需求,例如用自己企业职员的声音制作一个音库,想要达到和语音合成厂商一样的效果,这个是比较难的,目前语音合成厂商的录音员基本上都是专业的播音员,不是任何一个人就可以满足制作音库的标准,如果技术可以达到每一个人的声音都可以到达85%以上的还原,这将应用于更多的场景中。
三,效果指标和技术指标
随着语音合成技术的发展,语音合成(TTS)已经应用于生活中的各个场景,实现了语音合成技术的应用落地。例如,在高铁,机场的语音播报工作,医院的叫号业务,以及现在比较火热的语音交互产品。语音合成的各种应用说明它不仅仅是一项技术,更是一款产品,作为产品,可以用哪些指标来衡量这款产品呢?
下面将介绍两种衡量TTS产品的指标,效果指标和性能指标。
1.效果指标
1)MOS值
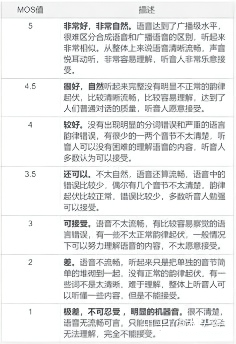
目前关于TTS合成效果的评判标准,行业内一致认可的是mos值测试,找一些业内专家,对合成的音频效果进行打分,分值在1-5分之间,通过平均得到最后的分数,这就是mos值测试。很显然这是一个主观的评分,没有具体的评分标准,这和个人对音色的喜好,对合成音频内容场景的掌握情况,以及对语音合成的了解程度是强相关的,所以算是仁者见仁,智者见智的测试方式。
由于TTS合成效果的评判主观性,导致在一些项目的验收中,不能明确出具体的验收标准,例如在定制音库的项目中,客户想做一个独有的定制音库,最后验收肯定是客户对合成音频效果满意,则成功验收,这是一个很主观的标准,怎么样才算满意呢?对于TTS厂商而言,这是不公平的。所以需要找一些可以量化的标准使得项目可以更好的验收,双方也不会因为合成效果出分歧。这里推荐一条验收标准,可以将语音合成效果量化,分别对原始录音和合成音频进行盲测打分(mos值测试),合成音频的mos值能达到原始录音的85%(数值可以根据项目情况来定)以上,就可验收,这样就可以把验收标准确定下来,且进行了量化。当然打分团队可以是客户和TTS厂商的人,也可以请第三方的人来打分,确保公平。
虽然mos值是一个比较主观的测试方式,但也有一些可评判的标准。例如在合成的音频中,多音字的读法,当前场景下数字的播报方式,英语的播报方式,以及在韵律方面,词语是否连在一起播报,应该重读的地方是否有重读,停顿的地方是否合理,音色是否符合应用于当前的这个场景,都可以在打分的时候做为得分失分的依据。
分享一个简单的评分标准,可作为参考依据。
2)ABX测评
合成效果对比性测试,选择相同的文本以及相同场景下的音色,用不同的TTS系统合成来对比哪个的合成效果较好,也是人为的主观判断,但是具有一定的对比性,哪一个TTS更适合当前的场景,以及合成的效果更好。
2.性能指标
1)实时率
在语音合成中,合成方式分为非流式合成和流失合成,非流失合成指的是一次性传入文本汉字制作广告语音合成软件,一次性返回合成的文本音频;流式合成指的是文本传输给TTS时,TTS会分段传回合成的音频,这样可以减少语音合成的等待时间,在播报的同时也在合成,不用等到整段音频合成完再进行播报,所以对于语音合成时间的一个指标就是实时率。实时率等于文字合成所需时长除以文字合成的音频总时长,下面是实时率的计算公式:


为什么讲实时率会说到非流失合成和流式合成,因为在流式合成场景中,开始合成的时候也就已经开始播报了,音频合成完成也就播报完成了,不会产生等待的过程,这种过程主要用于语音交互的场景,智能机器人收到语音信号之后,马上就可以给予答复,不会让用户等太久。所以为了确保用户的最佳体验,要求“文字合成所需时长”≤“文字合成出的音频时长”,也就是实时率要小于等于1 。
2)首包响应时间
在流式合成中,分段合成的音频会传输给客户端或者播放系统,在合成首段音频时,也会耗费时间,这个耗时称为“首包响应时间”。为什么会统计这个时间呢,因为在语音交互中,根据项目经验以及人的容忍程度,当用户说完话时,在2000ms(1500ms体验就更佳)之内,机器人就要开始播报回复,这样就不会感觉有空白时间或者停顿点,如果时间超过2000ms,明显感觉会有一个等待的时间,用户体验不佳,性子急的用户可能就终止了聊天。2000ms的时间不只是TTS语音合成的首包时间,还有ASR(语音识别)和NLP(自然语言处理)所消耗的时间,所以TTS首包响应时间要控制在500ms以内,确保给ASR,NLP留有更多的时间。
3)并发数
人工智能的发展主要有三个方面,分别为算法,算力,数据,其实讲的性能指标相当于是算力的部分,目前承载算力的服务器有CPU服务器和GPU服务器。前面说到实时率的指标是要小于等于1,那如果实时率远小于1,是不是会对服务器造成浪费呢,因为只要实时率小于等于1,就可以满足用户的需求,让用户体验良好。所以上面说的实时率是针对CPU服务器单核单线程时,或者GPU单卡单线程时,那实时率的公式可以为:
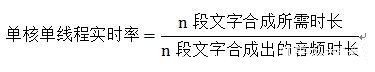
为了资源的最大利用化,我们只需确保实时率接近1,或者等于1就行,没必要远小于1,所以当在单核单线程实时率远小于1时,则可以实现一核二线,一核三线的线程数,使得实时率为1,这个一核“二线”汉字制作广告语音合成软件,“三线”,这个“几线”说的就是几并发数,准确说是单核并发数。那这个并发数怎计算呢,举个例子,如果单核单线程的并发数是0.1,则一核10线程的并发就是1,也是满足需求的,就可以按照这个并发数给客户提供。所以并发数的计算公式如下:

所以当用户需要200线程的语音合成并发数使,按0.1的实时率,一核十线,只需要20核的cpu服务器,则可以跟客户要求24核的cpu服务器即可满足客户的需求,也为客户节省了成本。
再说一下这个线程和并发的概念,线程,并发算是同一个概念,例如200线并发,指的是需要同时支持200线的语音合成,200线是同时合成音频的,合成内容可以相同也可以不同。
4)合成100个字需要多少时间(1s能合成多少个字)
有些客户对于实时率,响应时间这些概念是比较模糊的,他会问你们的TTS合成100个字需要多少时间或者1s能合成多少个字,所以这个时候为了方便和客户沟通,我们需要知道合成100个字TTS消耗的时间。这个数据是可以大概算出来的,当然也可以直接让测试测出一百字消耗的时间。这里主要讲一下计算的方法。
按照正常的播报速度,1秒可以播报4个字左右,我们就按照四个字计算,100个字的音频,音频时长大概就是25s(100除以4),假如实时率为0.1,再根据当前的实时率计算公式,算出合成时间为2.5s,也可以计算出1s合成的字数(100/2.5)为40个字。
简单介绍了语音合成产品会涉及到的一些参数指标,还有一些测试时需要了解的指标数据,例如cpu占用,内存占用,DPS(单位时间合成的音频总时长),TPS(单位时间合成的音频任务数)以及TP99,感兴趣的朋友可以查询研究一下,这些数据也主要用于项目poc的测试中,或者TTS产品整体的测试中,可以算是对于TTS产品的一个整体的了解。
四,语音合成厂商
有很多厂商拥有语音合成技术,有互联网大厂,也有一些只专注于人工智能的企业。
科大讯飞科大讯飞的语音合成技术在全球范围内也是数一数二的,合成的音频效果自然度高,讯飞官网挂接的音库是最多的,且涉及很多的场景,以及很多的外语音库。
阿里巴巴在阿里云官网的音库,有几个音库的合成效果非常棒,例如艾夏,合成的音频播报时感觉带有气息感,拟人化程度相当高。
百度百度的语音合成技术还是很强的,但是官网给的合成音库较少,具体不太好评判。
灵伴科技这家公司在语音合成领域是不在忽略的。灵伴的音库合成音效果也是非常的棒,有一个东北大叔的音库,主要是偏东北话,整体的韵律,停顿,重读等掌握的很好,很到位。
标贝科技标贝科技和灵伴科技一样,是语音合成领域不可小觑的两个企业,是因为他们TTS合成的音频效果拟人化程度很高,每个场景的风格也很逼真。
捷通华声捷通华声是一家老牌的人工智能企业,合成的音频效果整体还是不错的,且支持多种语种的音库。
还有些企业没有一一列出来,是因为上面这些企业是在平时项目中,或者TTS技术落地应用上比较多的企业。
五,小结
目前的语音合成已经应用于各种场景,是较成熟可落地的产品,对于合成音的要求,当前的技术已经可以做很好了,满足了市场上绝大部分需求,语音合成技术主要是合成类似于人声的音频,其实当前的技术已完全满足。目前的问题在于不同场景的具体需求的实现,例如不同的数字读法,如何智能的判断当前场景应该是哪种播报方式,以及什么样的语气和情绪更适合当下的场景,多音字如何更好地区分,确保合成的音频尽可能的不出错。当然错误有时候是不可避免的,但是如何在容错范围之内,或者读错之后是否有很好的自学机制,下次播报时就可以读对,具有自我纠错的能力,这些可能是当前产品化时遇到的更多更实际的问题,在产品整体设计的时候,这些是需要考虑的主要问题。
关键词:罗姆语音合成LSI
 上一篇
上一篇 








