

python 把unicode编码-python 编码成unicode
【先看要点】
一、字符编解码的概念
2、从ASCII编码到Unicode编码的发展过程
3.混淆字符编码和字符编码
【姐姐说】最后两集基本上让我们熟悉了字符串的常用用法,但也让我想起了一些混淆了很久的概念:ASCII码、Unicode、字符编码等等,我从来没有明白了吧,那么今天为什么不介绍一下这方面的内容呢。

关于字符编码的概念太多太复杂了。 当ASCII、GB2312、Unicode、UTF-8、UTF-16、encoding、decoding等等很多名词堆在一起的时候,真的很容易让人迷惑。
为了把这些问题讲清楚,我今天换个说法,不讲编程,只讲故事。 从历史的维度,在时间轴上梳理不同语言国家计算机不断发展的过程,从而透彻理解这些概念。
什么是字符编码和解码?
计算机能理解的“语言”是二进制数,最小的信息标识是二进制数字,8位二进制数字代表一个字节; 而我们人类能够理解的语言是英文字母、汉字和标点符号的集合。 由符号字符、阿拉伯数字和许多其他字符组成的字符集。 如果想让计算机按照人的意愿工作,就必须将这些人类使用的字符集转换成计算机能够理解的二级代码。 这个过程就是编码,它的逆过程叫做解码。

从 ASCII 到 Unicode 的演变
计算机最早是在美国发明和使用的。 需要编码的字符集不是很大,无非是英文字母、数字和一些简单的标点符号,所以采用单字节编码系统。 在这套编码规则中,人们将所需要的字符集中的字符一一映射为128个二进制数。 这128个二进制数的最高位为0,其余7位用来组成00000000~01111111(0X00~0X7F)。
0X00到0X1F的32个二进制数用于编码控制字符或特殊通信字符(如LF换行、DEL删除、BS退格),0X20到0X7F的96个二进制数用于编码阿拉伯数字、英文字母等符号下划线和括号被编码。 将这个字符集映射到0X00~0X7F二进制码的过程称为基本ASCII编码。 通过这个编码过程,计算机将人类的语言转换成自己的语言并存储起来; 将数字转换成字母数字字符进行显示的过程就是解码。
随着计算机的迅速推广和使用,欧洲非英语国家的人们发现美国人设计的字符集已经不够用了。 例如,一些带有重音符号的字符和希腊字母不包含在这个字符集中,因此扩展了 ASCII 编码规则。 ,把原本为0的最高位改成1,这样10000000~11111111(0X80~0XFF)的128个二进制数就展开了。 其中,最优秀的扩展方案是ISO 8859-1,俗称Latin-1。 Latin-1 使用 128 到 255 的 128 个二进制数,包括足够的附加字符集以涵盖基本的西欧语言,并兼容 0 到 127 范围内的 ASCII 编码规则。
随着越来越多的国家使用计算机,需要编码的字符集自然也越来越大。 由于单字节的限制,早期的ASCII编码字符集的容量远远不够。 几万个汉字,压力可想而知。 为此,国家标准总局发布了一套《信息交换用汉字编码字符集》国家标准,其标准号为GB 2312-1980。 该字符集共包含6763个汉字和682个非汉字图形字符。 它使用两个字节对字符集进行编码,并向后兼容ASCII编码方式。 简而言之,整个字符集分为94个区域,每个区域有94位python 把unicode编码,用一个字节来表示对应的区域和位。 每个区域对应一个字符,所以区域和位可以用来对汉字进行两个字节的编码。 后来生僻字、繁体字、日韩汉字也被收录到字符集中,才有了后来的GBK字符集和相应的编码规范。 GBK编码规范也向后兼容GBK2312。
中国在发展的同时,计算机在世界各国也越来越普及。 不同的国家和地区会发展自己的编码系统,因此编码系统是多种多样的。 这时候,问题就开始出现了,尤其是在互联网通信的环境下。 在这种情况下,配备不同编码系统的计算机之间的通信将不知道对方在“说什么”。 将需要的字符按照A编码系统的编码方式转换成二进制码后,在B编码系统的计算机上进行解码是不可能得到原始字符的,反而会出现一些意想不到的怪异字符,这就是所谓的乱码。
那么统一字符编码的需求就迫切的摆在了大家的面前。 为了实现跨语言、跨平台的文本转换和处理要求,ISO国际标准化组织提出了新的Unicode标准。 这套标准包括Unicode字符集和一套编码标准。 Unicode 字符集涵盖了世界上所有的字符和符号。 Unicode编码方案为字符集中的每个字符规定了统一唯一的二进制编码,可以彻底解决以往不同编码系统的冲突和乱码问题。 这套编码方案很简单:编码规范包含17组(称为平面),每组包含65536个码点(例如0组为0X0000~0XFFFF),每个码点对应一个唯一的字符,其中大部分位于字符集平面0的代码点,少数位于其他平面。
字符编码和字符编码的概念区别

既然提到了Unicode编码,那么经常伴随的UTF-8和UTF-16编码方案有哪些呢? 其实到目前为止,我们一直在混淆两个概念,即字符编码和字符编码。 单位的二进制序列。 在ASCII编码体系中,字符编码和字符编码是一致的。 比如字符A,在ASCII字符集中的序号,也就是所谓的字符编码为65,在磁盘中存储的二进制位序列为01000001(0X41,十进制也为65),在另外,比如在GB2312编码体系中,字符编码和字符编码的取值也是一致的,所以我们无形中忽略了两者的区别。
在Unicode标准中,我们目前使用的是UCS-4,即字符集中每个字符的字符编码用4个字节表示,字符编码0~127兼容ASCII字符集,一般汉字字符编码也集中在65535之前,使用大于65535的字符编码,即需要两个以上字节表示的字符编码比较少。 因此,如果仍然使用字符编码和字符编码的编码方式,英文字母和数字本来只需要一个字节编码,但目前需要4个字节进行编码,而汉字原本只需要两个字节进行编码,目前需要4个字节要编码的字节数,这对于存储或传输资源来说不划算。
因此需要在字符编码和字符编码之间进行重新编码,从而产生了UTF-8、UTF-16等编码方式。 基于以上需求,UTF-8就是将不同范围的字符编码转换成不同长度的字符编码。 同时这种编码方式是以字节为单位的,完全兼容ASCII编码,即0X00-0X7F的字符编码和字符编码是完全一样的,用一个字节来编码ASCII字符集,并且Unicode中常用汉字的字符编码为4E00-9FA5。 在文末的对应关系中,我们可以看到用了三个字节来对汉字进行编码。 UTF-16也是如此,它是以16位二进制数为基本单位对Unicode字符集中的字符编码进行重新编码。 原理与UTF-8一致。
因此,我们可以看到python 把unicode编码,在当前全球互联互通的背景下,Unicode字符集和编码方式解决了跨语言、跨平台通信的问题。 同时,UTF-8等编码方式有效地节省了存储空间和传输带宽。 ,从而得到了极大的推广应用。
[姐姐说]故事讲的很好。 以前觉得这些概念都是乱七八糟的。 这一集把字符编码的发展历史讲的很清楚。 人们很容易理解为什么会在某个时刻出现某种编码方式。 知道了来龙去脉,就很容易理解字符编码了。
日程:
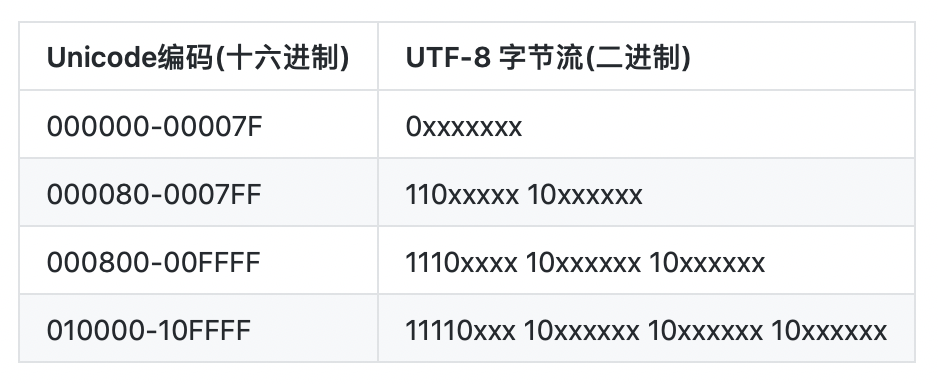
Unicode字符编码与UTF-8编码的对应关系
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
复制代码
 上一篇
上一篇 








