

python 把unicode编码-unicode编码转换
发布时间:2023-02-08 14:08 浏览次数:次 作者:佚名
最近一直被字符编码所困扰,然后搜索博文等资料彻底解决了这个疑惑python 把unicode编码,发现众说纷纭,于是根据个人倾向(有点随意)做了一些总结性的结论:
字节、字节流、二进制
ASCII、GBK、Unicode、UTF-8
python2, str, Unicode, 字符串
python3, str, Unicode, 字符串
编码(),解码(),Unicode
一、结语:
1、ASCII和GBK同时代表字符集和编码方式。 ASCII用1个字节存储一个字符,第一位为0; GBK用2个字节存储一个汉字,第一个字节为1,GBK兼容ASCII字符集。
2、Unicode是一种字符集,UTF-8是一种编码方式(Unicode字符集的编码实现)。 Unicode编码方式可分为utf-32(4个字节存储一个字符)、utf-16(2个字节存储一个字符)、utf-8(1-4个字节存储一个字符python 把unicode编码,汉字占3个字节)。
3、python 2中默认的字符集和编码方式是ASCII。
4、python 3中默认的字符集是Unicode,默认的编码方式是UTF-8。
5、编码:将字符按照指定的字符集编码成字节; 解码:根据指定的字符集将字节解码为字符。
6、字符编码使用的字符集必须和解码使用的字符集一致,否则会出现乱码。
2.py3中编码转码的过程
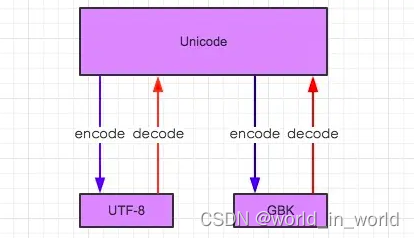
注意:Unicode 是一个中间字符集。 任何字符编码转换都会先解码成Unicode,再根据需要的编码方式进行编码。
#无需声明字符编码,当然你声明也不会报错
s = '你好'
s_to_gbk = s.encode("gbk") # 字符串s已经是unicode,无需解码
print("------s_to_gbk------")
print(s_to_gbk)
gbk_to_utf8 = s_to_gbk.decode("gbk").encode("utf-8") #需要先使用gbk解码成unicode,再使用utf-8编码
print("------gbk_to_utf8------")
print(gbk_to_utf8)
utf8_decode = gbk_to_utf8.decode("utf-8") #使用utf-8解码成unicode
print("------utf8_decode------")
print(utf8_decode)------s_to_gbk------
b'\xc4\xe3\xba\xc3'
------gbk_to_utf8------
b'\xe4\xbd\xa0\xe5\xa5\xbd'
------utf8_decode------
你好 上一篇
上一篇 








