

python爬取动态网页-python爬虫爬取网页所有数据
0x00 前言
如果读者看过我之前关于爬虫的文章,应该知道我们现在可以在静态网页上“为所欲为”,但是技术的发展总是永无止境的,仅仅对付静态页面是远远不够的像这样,要知道现在很多网页为了防止静态爬虫,都会有意无意的使用ajax技术来动态加载页面。 在本系列文章的开头,据说会提供动态加载网页的解决方案。 在这篇文章中,作者在这里提出了这个解决方案,以解决我们以前没有办法做的问题。
0x01 动态页面解决方案Selenium+PhantomJS
Python2(或Python3)本文使用Python2.7.11
Selenium自动化Web测试解决方案
PhantomJS 一个没有 GUI 的浏览器
0x02 原理回顾与比较
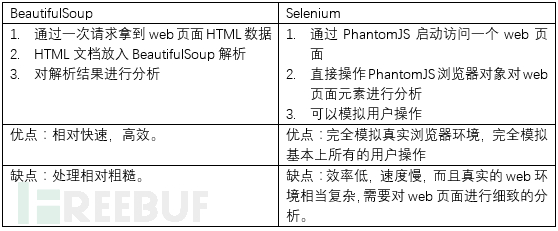
讨论:我讲了selenium自动化测试技术在爬虫数据挖掘中的应用。 其实我也经历过一段思考期。 有基础的朋友可能知道,完全基于静态网页分析的BeautifulSoup是无法执行JS的。 但是在使用web的过程中,基本上不可能不使用JS脚本。 当时想找个JS引擎集成BeautifulSoup,然后打算用到Spidermonkey技术。 如果我们需要这样做,我们会发现我们不仅需要使用 BeautifulSoup 爬取页面的目标元素,还要考虑爬取 JS 脚本。 执行完这些js脚本后,我们需要再次分析这些脚本返回的数据或者对HTML页面的影响。 我认为这增加了太多。 我们不想花太多时间在脚本编写上,既然选择了Python,就要充分发挥其巨大的Pythonic优势。 然后还有一个解决方案就是github主页的Ghost.py。 我想也许我们通过这个方案引入的不仅仅是一个爬虫,更是一扇新世界的大门,所以我还是选择了selenium,一套完整的web自动化测试解决方案。
其实我们从BeautifulSoup方案到selenium方案的转变,在思维上是一个“回归”的过程,从直接解析HTML -> 解析JS -> webkit -> 干脆直接使用headless browser去操作网页的selenium。
那么也就是说,我们接下来要讨论的爬虫使用selenium,与我们之前学习的静态页面处理有着根本的区别,对我们来说也算是一个全新的技术。
0x03 快速启动
在这里我们可以负责任的说,下面的例子并不能让读者完全掌握selenium的使用,但是通过动手,你可以了解到selenium非常好用,并不逊色于BeautifulSoup(可能这两者不是一个级别的)无法比较)。 但是可以说BeautifulSoup中的定位元素可以在selenium中完成,selenium可以设置页面加载完成的等待时间,或者设置网页加载我们需要的数据的条件,然后获取数据.
下载并安装:
首先,我们需要从官网下载PhantomJS浏览器。
然后安装 selenium,可以使用 easy_install 或 pip 轻松安装:
1.轻松安装硒
2.pip安装selenium
那么我们的第一个目标页面就很简单了,就是存在ajax的情况:页面如下:
Some JavaScript-loaded content

This is some content that will appear on the page while it's loading. You don't care about scraping this.
我们简单的看到这个网页使用ajax动态加载数据,GET请求LoadedContent.php然后直接在content中显示结果。 我们不需要对这个方法有很深的理解。 总之,我们只需要知道,如果用传统的方式获取,获取的是上面的静态htmlpython爬取动态网页,没有loadedContent.php中的内容。
作为selenium的爬虫应用quickstart,原理就不用解释太深了。 我们需要将 PhantomJS 和 python 脚本放在同一个文件夹中,并创建一个 selenium_test.py 文件夹
然后在selenium_test.py中输入内容:
#引入selenium中的webdriver
from selenium import webdriver
import time
#webdriver中的PhantomJS方法可以打开一个我们下载的静默浏览器。
#输入executable_path为当前文件夹下的phantomjs.exe以启动浏览器
driver =webdriver.PhantomJS(executable_path="phantomjs.exe")
#使用浏览器请求页面
driver.get("http://pythonscraping.com/pages/javascript/ajaxDemo.html")
#加载3秒,等待所有数据加载完毕
time.sleep(3)
#通过id来定位元素,
#.text获取元素的文本数据
print driver.find_element_by_id('content').text
#关闭浏览器
driver.close()建议您先用传统方法尝试这个页面,然后再使用上面的脚本执行。 观察两个结果之间的差异。 当然,我在这里说清楚:如果你真的不想学selenium的定位元素,发送数据等操作,其实也没有问题。 通过一个叫page_source的属性,我们可以得到当前整个页面的html,然后将页面传给BeautifulSoup,这样我们还是可以使用BeautifulSoup进行分析。
0x04 网络驱动API
我们发现要使用selenium来分析页面,我们引入了webdriver,它有很多简单易用的API:
定位元素、控制浏览器行为、刷新、操作网页元素、模拟键盘鼠标事件、获取认证信息、设置等待时间、上传下载文件、调用javascript、窗口截图。
我们写一个简单的爬虫可能需要的就是元素定位和设置等待时间。 这里我利用这两个特性再写一个例子给大家理解:
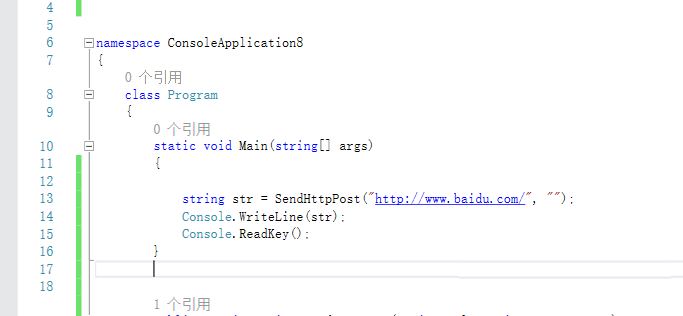
很多人学python不知道从何下手。
很多人学习python,掌握了基本语法后,却不知道去哪里找案例入门。
很多已经做过案例的人不知道如何学习更高级的知识。
所以针对这三类人,我会为大家提供一个很好的学习平台,免费的视频教程,电子书,以及课程的源码!
QQ群:721195303
抓取淘宝的商品信息
我们抓取了一个淘宝页面。 其实静态爬取是很难的。 淘宝的反爬虫措施相当到位。 我们可以先用最简单的方式试试:
import bs4
import requests
r = requests.get("https://s.taobao.com/search?q=surface&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.7724922.8452-taobao-item.1&ie=utf8&initiative_id=tbindexz_20160228")
data = r.content
soup = bs4.BeautifulSoup(data)
for tag in soup.tagStack:
print tag.encode('gbk','ignore')
我们找到了结果:
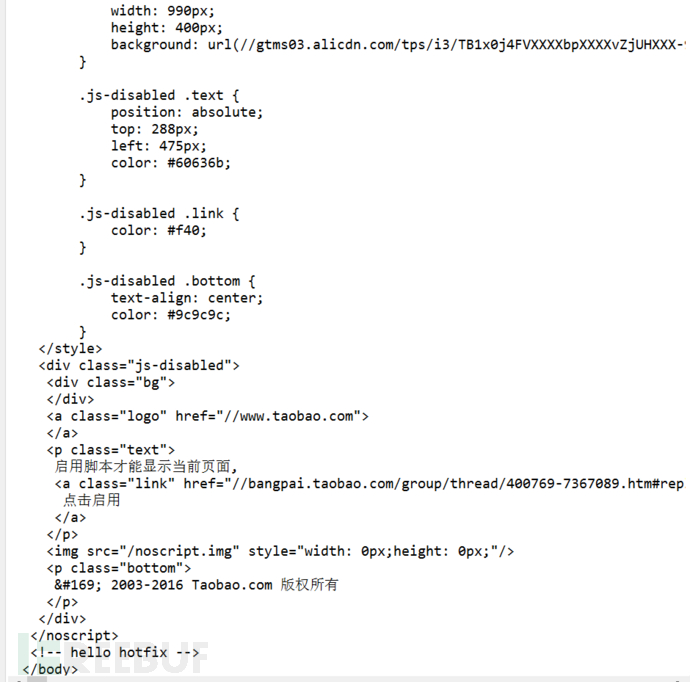
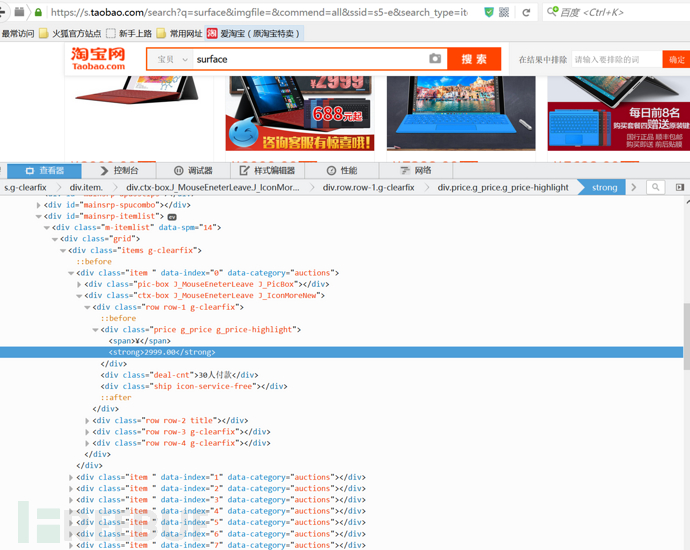
同时我们发现通过这种方式获取到的html中并没有商品信息。 这样基本上所有的静态方法都不能用了。
但是selenium的方法是直接操作浏览器,所以淘宝不能阻止这种数据采集。
我们简单看一下能否获取到这个淘宝页面:
from selenium import webdriver
import time
driver = webdriver.PhantomJS(executable_path="phantomjs.exe")

driver.get("https://s.taobao.com/search?q=surface&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.7724922.8452-taobao-item.1&ie=utf8&initiative_id=tbindexz_20160228")
time.sleep(7)
print driver.page_source.encode('gbk','ignore') #这个函数获取页面的html
driver.get_screenshot_as_file("2.jpg") #获取页面截图
print "Success To Create the screenshot & gather html"
driver.close()
我们还是轻松愉快的拿到了产品信息,查看文件夹下的截图文件:
2.jpg是我们截图的文件。 打开一看,图片明显没有加载。 实际效果应该是加载完所有图片:
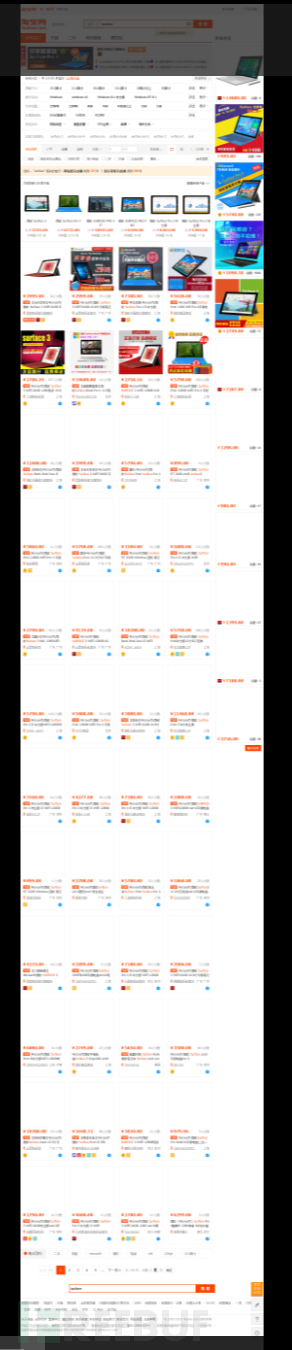
放大看高清网页截图:
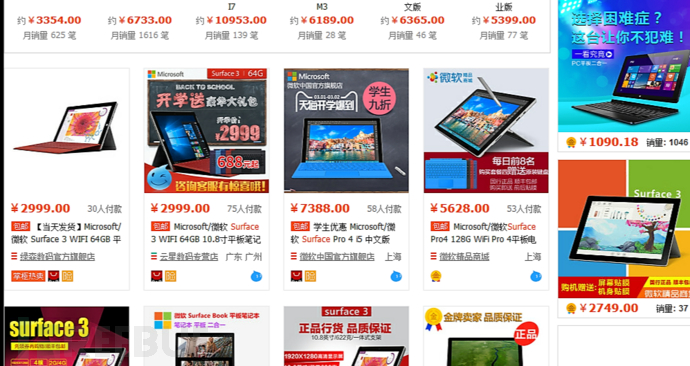
这时候我们有了静态分析和数据挖掘的html。
这里值得一提的是selenium侧重于对单个元素的操作,而beautifulsoup侧重于html页面的分析和数据分类python爬取动态网页,所以两者结合可以达到很好的效果,但是过程中你会发现一个问题of using,用selenium打开phantomjs的速度有点慢,当然你也可以用firefox或者chrome,这些selenium是支持的。
玩得开心!
事实上,硒还有各种神奇的功能。 例如,如果你想自动填写一个 web 应用程序的表单,selenium 肯定比任何按钮向导都好用得多。
0x05 匿名爬虫
有时我们使用爬虫来工作很烦人。 在某些情况下,IP 被限制,这会造成很多麻烦。 如果爬虫在服务端,可能还好,服务端可以提供多个IP可以选择,但是作为国内的爬虫,IP被锁定后,真的很头疼。
当然,所谓匿名爬虫也是一种匿名请求目标页面,然后获取页面结果的方式。
0x06 匿名爬虫解决方案(来自《webscraping with python》)Tor+PySocks
使用 Tor
PySocks 设置代理
如何使用非selenium匿名浏览设置:

import socks
import socket
from urllib.request import urlopen
#假设tor在9999号端口启动
socks.set_default_proxy(socks.SOCKS5, 'localhost', 9999)
socket.socket = socks.socksocket
print urlopen('target_web').read()使用硒的匿名方式:
from selenium import webdriver
#假定9999端口开启tor服务
service_args = ['--proxy=localhost:9999', '--proxy-type=socks5', ]
driver =webdriver.PhantomJS(executable_path="phantomjs.exe",service_args=service_args)
driver.get("target_url")
print driver.page_source
driver.close()0x07 总结结束
本系列文章共使用了约4篇文章(附件:Python高级爬虫:(1)、(2)、(3)),总篇幅数万字,通过大量有趣的例子来揭示爬虫的各种技术,旨在提供粉丝讲解爬虫技术,为需要使用爬虫的开发者提供一些实用的解决方案。 如果您喜欢本系列文章,可以在评论区留下您的看法。
这里还是要推荐一下我自己建的Python学习群:721195303,群里大家都在学Python。 如果你想学习或者正在学习Python,欢迎你的加入。 大家都是软件开发党,不定期分享干货(仅限Python软件开发相关),包括一份2020最新的Python进阶资料和自己整理的零基础教学,欢迎进阶有兴趣的朋友加入Python!
**以下内容无用,因为本博客被搜索引擎抓取使用
(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)
蟒蛇做什么? 学习python需要多长时间? python为什么叫爬虫?
python爬虫菜鸟教程 python爬虫通用代码 python爬虫如何赚钱
python基础教程网络爬虫pythonpython爬虫经典实例
蟒蛇爬虫
(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)
以上内容无用,因为本博客被搜索引擎抓取使用**
 上一篇
上一篇 








