

dfs文件服务器java代码-java代码实现文件上传
翻译:陈之炎
校对:王威力
本文约1500字,建议阅读5分钟。
在本文中,大数据专家将为您介绍如何使用HDFS以及如何利用HDFS创建HDFS集群节点。
我们将从HDFS、Zookeeper、Hbase和OpenTSDB上的系列博客开始,了解如何利用这些服务设置OpenTSDB集群。在本文中,我们将探究HDFS。
HDFS
Hadoop分布式文件系统(HDFS)是一种基于Java的分布式文件系统,它具有容错性、可伸缩性和易扩展性等优点,它可在商用硬件上运行,也可以在低成本的硬件上进行部署。HDFS是一个分布式存储的Hadoop应用程序,它提供了更易访问数据的接口。
架构
HDFS架构包含一个NameNode、DataNode和备用NameNode。
HDFS具有主/从架构。
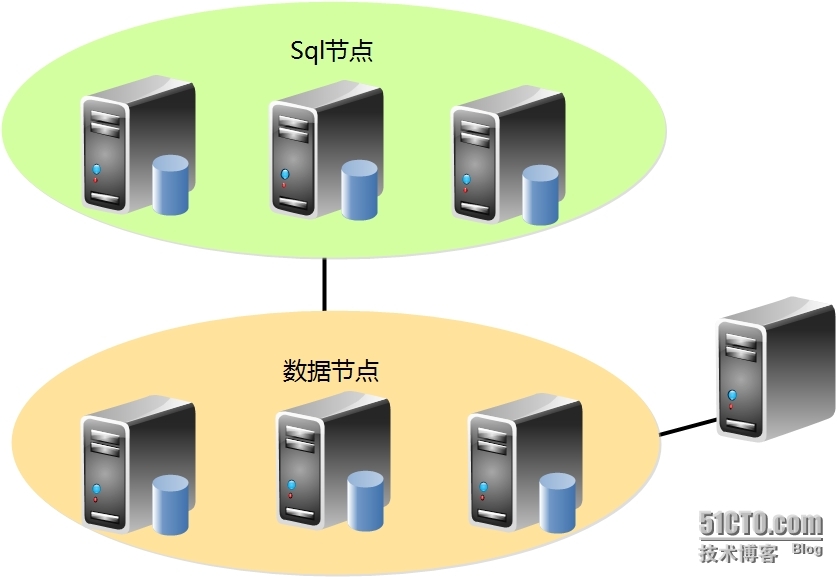
NameNode:HDFS集群包含单个NameNode(主服务器)dfs文件服务器java代码,它管理文件系统命名空间并控制客户端对文件的访问权限。它维护和管理文件系统元数据;例如由哪些块构成文件,以及存储这些块的数据节点。
DataNode:可以有多个DataNode,通常是集群中每个节点有一个DataNode,它负责管理运行节点的存储访问。HDFS中的DataNode存储实际数据,可以添加更多的DataNode来增加可用空间。
备用NameNode :备用NameNode服务并非真正的备用NameNode,尽管名称是称为备用NameNode。具体来说,它并不为NameNode提供高可用性(HA)。
为什么需要备用NameNode?
备用NameNode记录文件系统的修改痕迹,追加到本机文件系统文件的后面,作为修改日志。
关键特征
容错:为了防止机器故障,可跨多个DataNode复制容错数据dfs文件服务器java代码,复制因子的默认值是3(如果有3个DataNode,每个块至少存储在三台计算机上)。
可伸缩性- DataNode之间可实现直接数据传输,所以读/写次数应与DataNode的数量相匹配。

空间-需要更多的磁盘空间?只需添加更多DataNodes和再平衡。
行业标准-其他分布式应用程序均构建在HDFS之上(HBASE,Map-Reduction)。
HDFS是用来处理大数据集的,它具有write-once-read-many(一次写-多次读)的语义,不适合低延迟访问。
数据结构
分块安置策略
设置HDFS集群
要创建HDFS集群,会用到Docker。有关Docker映像的详细信息,请参见:
步骤
查看Gist上的代码。
NameNode
在VM1中为NameNode创建环境变量文件(namenode_env)。
查看Gist上的代码。
在VM1上创建NameNode:
查看Gist上的代码。

查看Gist上的代码。
在VM1上创建DataNode1:
查看Gist上的代码。
查看Gist上的代码。
查看Gist上的代码。
在所有vms中,通过执行docker ps检查所有容器是否已启动并正常运行。
一旦所有容器均已启动并运行,请转到VM1,打开浏览器,打开:50070/dfshealth.html#tab-datanode.将会看到如下输出:
HDFS CLI
在本文中,我们研究了HDFS以及如何创建3个节点HDFS集群。在下一篇文章中,我们将关注Zookeeper,并创建一个Zookeeper集群。
参考文献:
#walkthrough
本文首次在Generic Class博客上发表。
原文标题:
An Introduction to HDFS
原文链接:
 上一篇
上一篇 








