排序算法 java实现-Java内存模型相关的基本概念和解决方法介绍
Java中的并发是基于共享内存模型实现的。学习并深入地理解Java内存模型,有助于开发人员了解Java的线程间通信机制原理,从而实现安全且高效的多线程功能。本文将简单介绍Java内存模型相关的基本概念。
1.处理器内存模型
计算机在执行程序时,每条指令都是在CPU中执行的,而执行指令过程中,势必涉及到对主存中数据的读取和写入。由于CPU的处理速度相比对内存数据的访问速度快很多,如果任何时候对数据的操作都要通过和内存的交互来进行,会大大降低指令执行的速度。因此在CPU里面就有了高速缓存。
然而引入高速缓存带来方便的同时,也带来了缓存一致性的问题。当多个处理器的运算任务都涉及同一块主内存区域时,将可能导致各自缓存数据不一致的问题。解决方法是缓存一致性协议(如Intel 的MESI协议)。
MESI协议保证了每个缓存中使用的共享变量的副本是一致的。当CPU写数据时,如果发现操作的变量是共享变量,会发出信号通知其他CPU将该变量的缓存行置为无效状态。因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。
除了增加高速缓存之外,为了使得处理器内部的运算单元能尽量被充分利用,处理器可能会对输入代码进行乱序执行(Out-Of-Order Execution)优化,处理器会在计算之后将乱序执行的结果重组,保证该结果与顺序执行的结果是一致的,但并不保证程序中各个语句计算的先后顺序与输入代码中的顺序一致,因此,如果存在一个计算任务依赖另外一个计算任务的中间结果,那么其顺序性并不能靠代码的先后顺序来保证。
2.Java内存模型的抽象
在java中,Java内存模型(Java Memory Model,JMM)抽象了不同硬件平台和操作系统的内存访问差异,并规范了Java的线程间通信机制。
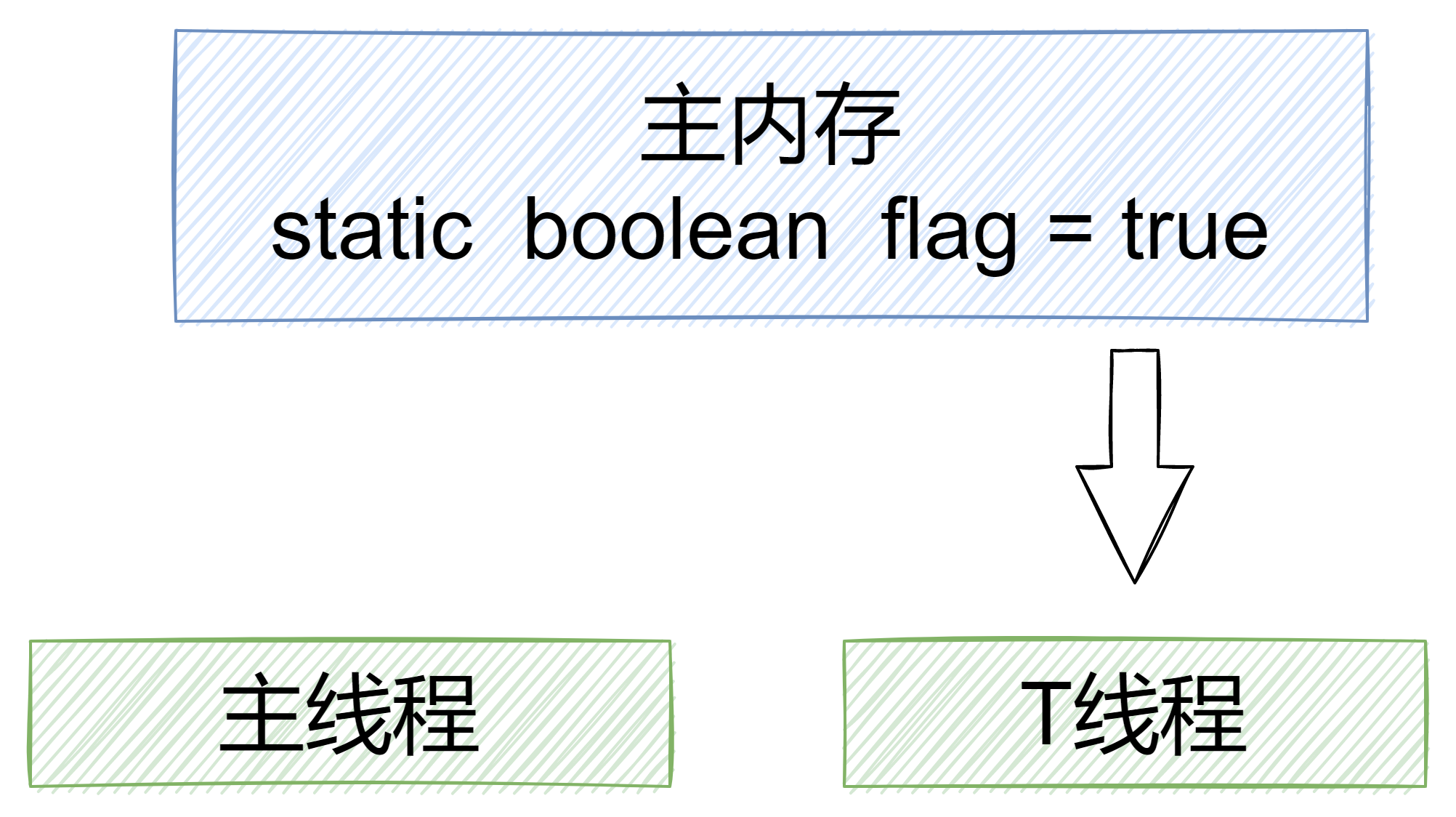
为了方便理解Java内存模型,我们可以抽象地认为,所有变量都存储在主内存中(Main Memory),每个线程都拥有一个私有的工作内存(Working Memory),保存了该线程已访问的变量副本。线程对变量的所有操作都必须在工作内存中进行,而不能直接对主存进行操作。
假设线程A要向线程B发消息,线程A需要先在自己的工作内存中更新变量,再将变量同步到主内存中,随后线程B再去主内存中读取A更新过的变量。因而可以看出,JMM通过控制主内存与每个线程的本地内存之间的交互,来为java程序员提供内存可见性保证。
3.重排序
在执行程序时,为了提高性能,编译器和处理器会对指令做重排序。从Java源码到实际执行的指令序列,会经历以下三种重排序:
1、编译器优化重排序:编译器在单线程程序语义(as-if-serial semantics)的前提下,可重新安排语句的执行顺序。
2、指令级并行的重排序:如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
3、内存系统的重排序:处理器使用缓存和读写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
其中as-if-serial是指,不管怎么重排序,单线程程序的执行结果不能被改变。
在Java中,JMM允许编译器和处理器对指令进行重排序,同时会通过插入内存屏障(Memory Barrier)指令来禁止特定类型的重排序,为程序员提供内存可见性的保证。
4.重排序带来的问题
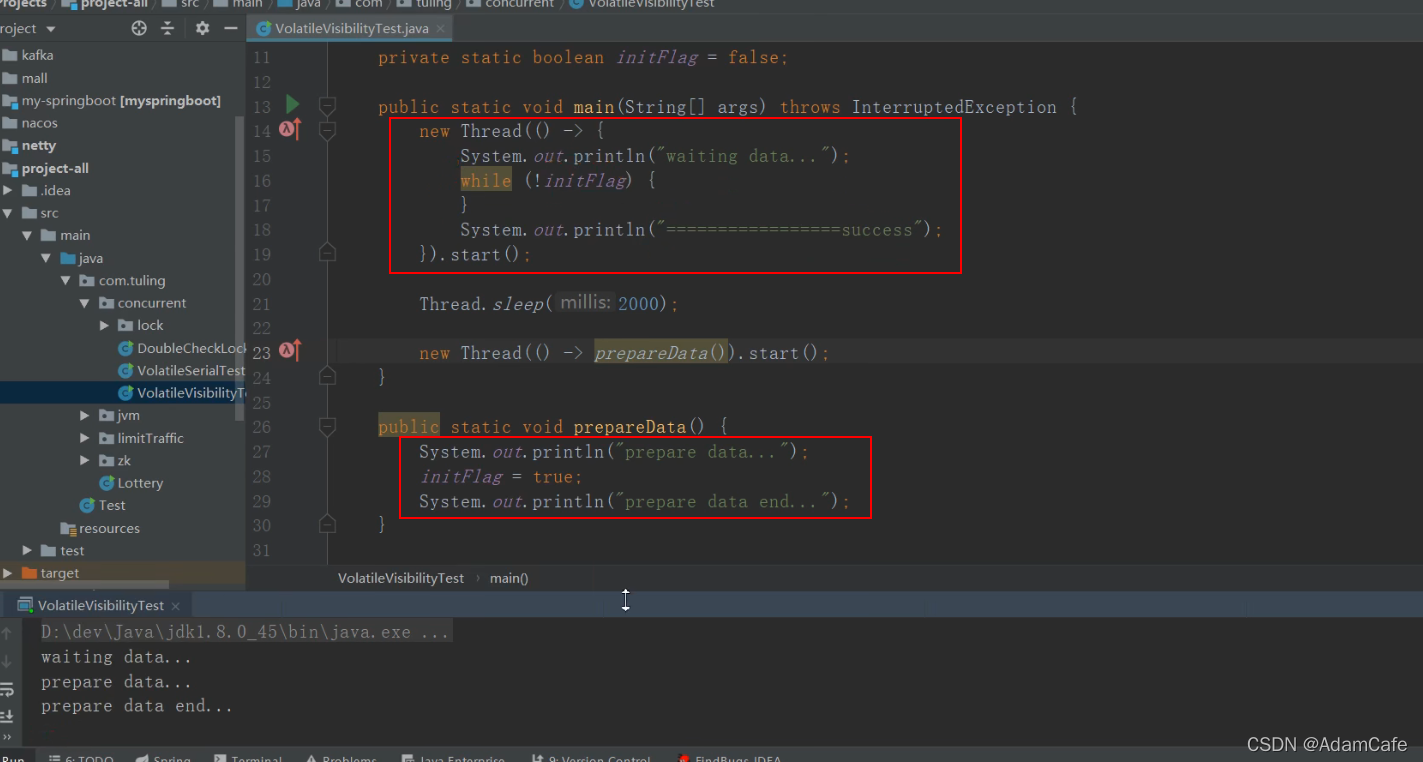
重排序过程不会影响到单线程程序的执行,但会影响到多线程并发执行的正确性。
class ReorderExample {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; //1
flag = true; //2
}
public void reader() {
if (flag) { //3
int i = a * a; //4
……
}
}
}假设线程A和线程B分别执行writer()和reader()方法。由于操作1和操作2没有数据依赖关系,因此编译器和处理器可能对它们进行重排序。而如果操作1和操作2发生了重排序,线程A先执行了操作2,接着线程B执行操作3判断满足if条件,进而执行操作4,如果此时操作1中变量a的值还未被写入,则会导致程序的语义被破坏。
5.先行发生原则
前面提到了,为了提高执行性能,JMM允许编译器和处理器对指令进行重排序。但是Java语言保证了操作间具有一定的有序性,概括起来就是先行发生原则(happens-before)。也就是说,如果两个操作的关系无法被happens-before原则推导,则无法保证它们的顺序性,有可能发生重排序。happens-before原则包括:
实际上,这些规则是由编译器重排序规则和处理器内存屏障插入策略来实现的。
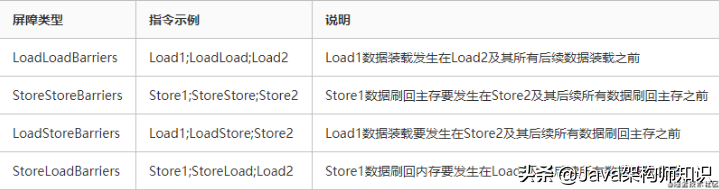
6.内存屏障
内存屏障是一条CPU指令,用于控制特定条件下的重排序和内存可见性问题。即任何指令都不能与内存屏障指令重排序。

Java编译器使用内存屏障的方式如下表所示。
参考资料
《深入理解Java虚拟机》
JSR-133:Java Memory Model and Thread Specification Revision
部门招聘
高级Java开发工程师
工作职责:
1、负责58同城APP,58同镇等相关后端研发工作;
2、负责基础平台的架构设计,核心代码开发;
3、调研并掌握业内通用技术方案,引入项目迭代,提升研发效率;
职位要求:
1、3年以上Java互联网项目开发经验;
2、Java基础扎实,编码规范,程序具备较高的健壮性,熟悉常用设计模式;
3、对MVC框架、RPC框架、基础服务组件等有深入的研究;
4、掌握Linux环境下的网络编程、多线程编程,数据结构和算法能力良好;
5、对高并发高可用系统设计有深入的实践经验;
6、具有高度的责任心、勇于承担责任,能承受较强的工作压力;
7、积极主动,敢于接受挑战,有较强的团队合作精神;
高级前端研发工程师
工作职责:
1、负责58同城App前端产品研发;
2、负责58同城前端无线产品某一技术方向,人才培养;
3、前端研发所需类库、框架、脚手架搭建;
4、交互模式调研及创新(React,ReactNative);
职位要求:
1、计算机及相关专业本科以上学历;
2、3年以上前端开发经验,负责过复杂应用的前端设计和开发 ;
3、精通web前端技术(js/css/html),熟悉主流框架类库的设计实现、w3c标准,熟悉ES6/7优先;
4、熟悉前端模块化开发方式(commonjs/webpack …);
5、熟悉移动端开发、自适应布局和开发调试工具,熟悉hybrid app开发;
6、掌握一门后端语言(node/java/php...),对前后端合作模式有深入理解;
7、有良好的产品意识和团队合作意识排序算法 java实现,能够和产品、UI交互部门协作完成产品面向用户端的呈现;
8、有技术理想,致力于用技术去推动和改变前端研发;
9、熟悉Vue/React/ReactNative优先,有BAT等公司经验优先;
高级Android开发工程师
岗位描述:
1、负责58同城App的研发工作;
2、肩负平台化任务(插件框架,Walle,Hybrid,WubaRN) ;
3、维护和开发服务库,公共库的工作;
4、调研Android前端技术;
5、提升开发效率和应用性能;
职位要求:
1、2年以上的Android开发工作经验;
2、精通Java语言排序算法 java实现,精通Android Studio开发,了解Gradle编译;
3、精通常用算法、数据结构和架构设计;
4、了解Android性能限制及优化方案;
5、了解常用的开源工具:Volley,RxJava,Fresco等等;
6、了解git, maven等等工具;
7、有插件开发经验,Hybrid开发经验,ReactNative开发经验优先;
8、积极主动、喜欢挑战,有强烈的创业精神,能承受高强度的工作压力;
以上如有小伙伴感兴趣,请发送简历到:
liunz@58ganji.com
 上一篇
上一篇