

游戏开发中的人工智能 拜拜-研究人工智能的首要问题是什么?|大赛
拥有好的测试台对人工智能研究来说很关键。游戏就是人工智能的测试台,因为它们为人工智能提供了各种挑战,而且非常吸引人。
对于人类来说,现在最重要的就是发明一个真正的人工智能:一个在绝大多数情况下可以独立思考并采取行动的机器或者软件。一旦这种人工智能出现,它就能帮助我们处理其他形形色色的问题。幸运的是,有数千名研究者在进行人工智能方面的工作。虽然他们中的大多数都在尝试用已知算法解决新问题,但是游戏开发中的人工智能 拜拜,有些人正在研究人工智能的首要问题。我兼顾两者。在我看来,解决应用问题刺激了新算法的产生,而且有了新算法,我们就可能解决新问题。为了取得进步,有必要找一些试着用人工智能加以解决的具体问题;如果试着发明人工智能,却没有它适合用来解决的问题,你会感到无从下手。我选择的领域是游戏,而且我也会解释为什么这是最相关的研究领域,如果你认真对待人工智能的话。

我对此说过很多,有些人可能会说,我一直在说。
但是,首先,让我们承认人工智能近期已然受到广泛的关注了,尤其深度学习这方面的研究遭到热捧,各大主流媒体争相报道,大公司巨额收购相关的初创公司。这几年人工智能也取得了许多令人瞩目的成就:识别场景中的物件、理解演讲内容、名字和人脸的配对、翻译文本。通过一些措施,近期ImageNet比赛的赢家在正确识别图片中的物件方面甚至做的比人更好。有时我会觉得Facebook的算法比我更善于在照片中认出我的好友。
ImageNet大赛中用到的示例照片。近期搭建的深度神经网络使机器可以学会极为精准的给图片打上标签。图片由image-net.org提供。
深度神经网络的拿手绝活儿就是所谓的模式识别问题,鲜有例外。基本上就是输入大量数据(一张图片、一首歌、一段文字),输出某些其他(通常小很多)的数据,比如一个名字、分类、另一张图或者其他语言的一段文字。为了学会这一技能,机器需要读取极大量的数据,找到其中模式。易言之,神经网络正在学习大脑感知系统所做的事:视觉、听觉、触觉等等。在较小范围内,他们也能做一部分我们大脑语言中枢的工作。
但是,这并不是智能的全部。人类并不会一天到晚坐在那里看东西。我们会有所作为:决策、执行以解决问题。我们对周边产生影响。(当然,我们有时候会在床上赖一天,但其他的大多数时候,我们总是以某种方式自主活动着的)。智能不断进化,帮助我们在一个充满危险的世界生存下去,而且做到这些需要与周边环境互动,规划行动复杂后果,也要不断适应变化中的环境。模式识别——识别物件或人脸、理解演说等功能——是智能很重要的一部分,但这只是一个不断思忖接下来怎么做的完整体系的一部分。想要研发人工智能,却只专注于模式认知,如同研发汽车却只专注轮胎。
为了建立一个完整的人工智能架构,我们就要建立一个体系,这个体系会涉及某种环境下的对应措施。怎样实现这一点呢?或许最显而易见的方法就是用机器人具身化人工智能(embody AI in robots)。而且实际上,我们也看到了,哪怕是那些最平凡的事情,比如随地形走路、拿起形状奇怪的物品,对机器人来说,都是很难完成的任务。80年代,机器人研究再度大量关注这类「简单」问题,也推动了应用领域的进步,也改善了人们对何为智能的理解。近数十年的机器人进步促使了自驾汽车的产生,这可能会成为人工智能在不久将来将要颠覆的社会领域之一。

曾经有段时间,我觉得自己也算是机器人专家了。前景中的车形机器人被设定要学会沿University of Essex校园(背景中)周边独自行驶。平心而论,我们低估了问题的难度。 (从左至右: 我 (现在在NYU纽约大学), Renzo de Nardi (Google), Simon Lucas (Essex), Richard Newcombe (Facebook/Oculus), Hugo Marques (ETH Zurich).
如今,机器人的研究接触久了便清楚认识到它的局限。机器人价格昂贵,结构复杂,推进很慢。当我刚开始攻读博士学位时,我的计划是研发一套从错误中自我学习的机器人系统,加速复杂性智能性。但很快发现,为了让我的机器人从他们的经验中自我学习,很多的任务不得不重复上千次,每次又需要好几分钟。这意味着,一项简单的任务就需要花上几天的时间,这还是在机器运行良好、电池散热正常的情况下。如果想要更近一步研发复杂的智能任务,我需要制造一个比以前更复杂的传感器和致动器,这极大增加了系统崩溃的风险。我也需要研发一个复杂的环境从而让复杂技能得以习得。以上种种很快就超出了能力范围。 这大概就是为什么进化机器人还没有能扩展到更复杂智能领域的原因。
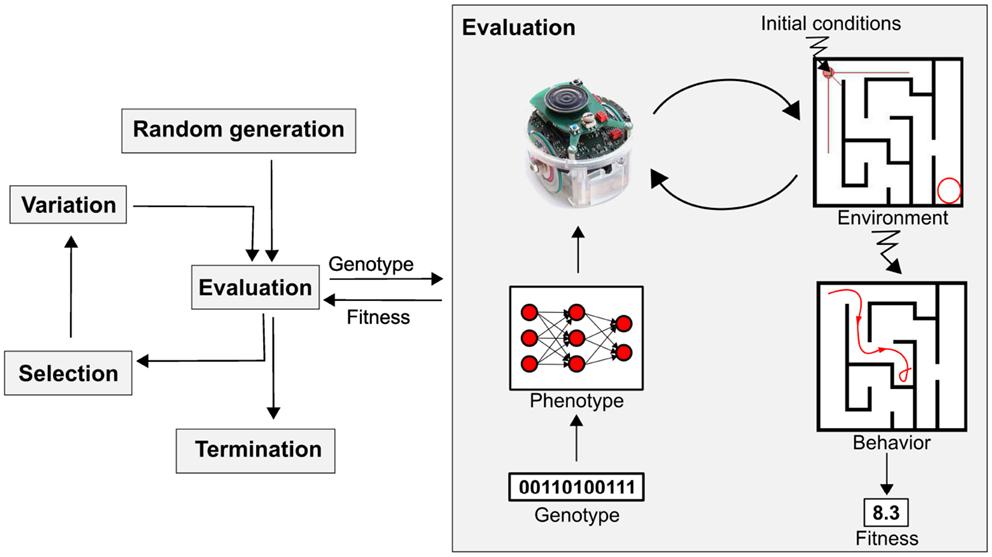
机器的进化理论:采用类似于达尔文进化理论的电脑算法帮助机器人通过人工智能的方式解决问题。上图源于最近的一篇论文。
我这次太迫不及待了,我渴望看到能从经验中自我学习的智能系统。于是我把主要精力投入到了电脑游戏领域。
游戏和人工智能有很悠久的渊源。早在人工智能被定义成一个专业范畴时,早期的计算机科学家就试图通过游戏编程来测试计算机是否能通过某种形式的「智能」来解决游戏中的问题。阿兰·图灵,计算机科学论证的奠基人,(重新)发明了极值算法并用它来下国际象棋(当时他还是用纸笔演算因为那时候还没有计算机);阿瑟·缪瑟尔(Arthur Samuel )第一个发明了学习机器的形式即现在的强化学习模型,他将这个程序用于跳棋游戏的自我对战。后来,IBM的深蓝计算机靠此战胜了国际象棋的卫冕冠军卡斯帕罗夫。如今,很多研究者力图研发更好的程序进行围棋竞技,但是仍旧没办法超过最好的人类选手。

阿瑟·谬瑟尔在1957年的时候就和一个体积如房间一样大的计算机进行跳棋博弈,尽管那时候的计算机功能还不及现在的手机强大,但计算机还是获胜了。
经典棋盘类游戏,比如象棋,跳棋还有围棋很适合也很容易用来做研究,因为很容易用代码模拟它们,而且模拟速度也相当快——在一台现代电脑上,你可以轻易实现每秒上百万步棋招——对许多人工智能来说,这也是必不可少的。要玩转这类游戏也需要思考,具有「学会仅需一分钟,精通却需一辈子」的特点。情况确实如此,游戏与学习密切相关,而且好的游戏能够不断教会我们游戏技巧。实际上,某种程度上说,玩游戏的乐趣就是在于不断学习它,当再没什么东西可学之时,我们基本上就会对这款游戏失去兴趣。这意味着,一款设计精良的游戏很适合作为人工智能的基准。但是,鉴于如今已经出现(相对简单的)会下棋的计算机程序,比人类还厉害,很明显,玩转这些游戏不需要你真的像人们普遍认为的那样聪明。 当你下棋思考时, 它们锻炼的只是人类思考技巧中非常小的一部分。

深蓝在象棋中击败大师凯斯帕罗夫
但是,我们身边的游戏远远不止这些,尽管祖父年代的人们可能一度这样认为。除了我们熟知的棋牌类,角色扮演类游戏外,还有视频游戏。视频游戏很着广大的粉丝,因为它能充分调动人们的各种感官。就拿超级玛丽来说,这款游戏不仅要求你有敏捷的反应,视觉理解和动作协调性,还需要你对路径的判断力,对于风险奖励的取舍能力,对敌人和角色接下来的预测能力,对在规定时间通关的掌控能力。还有一些游戏要求你对信息的获取能力(比如星际);剧情的理解能力(比如天际);或者长久的规划力(比如文明).
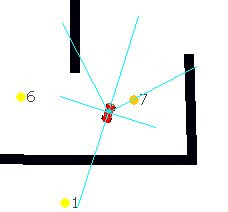
对于一款基本赛车类游戏的实验分析最后成就了我的博士论文。我们又称之为竞技类游戏。
综上所述,视频游戏可以在计算机中的不同可控环境下运行,而且不少游戏可以在自身的速度上进行加速。开始一款游戏并不复杂也不昂贵,并且在极短的时间内可以运行上千种变化,给学习算法创造了条件。

在第一年后,模拟竞速赛车开始转向TORCS 赛车游戏,这看起来更先进也更炫酷。
因此,近期,人工智能研究人员逐渐将视频游戏作为人工智能基准也就不足为奇了。研究人员,比如我自己,已经采用了许多电子游戏作为人工智能基准。我们已经组织过多次竞赛,比赛中,研究人员可以提交他们最棒的游戏人工智能(game-playing AI),通过与其他研究人员最好人工智能竞争,测试自己作品的水平;基于同一款游戏反复竞赛能够让参赛者们精炼自己的研究的进路和方法,以期来年获胜。这些用来测试的游戏有超级玛丽, 星际 (论文), TORCS赛车游戏 (论文), Ms Pac-Man (论文), 一款街头霸王类的格斗游戏(a generic Street Fighter-style figthing game) (论文), 愤怒的小鸟(论文), Unreal Tournament (论文)和其他等。几乎在所有比赛中,我们都发现每次比赛中,获胜人工智能玩家的表现都有提高。在促进圈内研究方面,这些竞赛也发挥了重要作用,每年发表了许多论文,竞赛软件也被用来作为一些新人工智能方法基准。因此,我们通过游戏竞赛来推进人工智能。
刚才的描述中有个问题,你能指出来吗?
就是那个。游戏特殊性。问题在于,提高人工智能玩家玩某款特定游戏的表现 ,并不必然有助于我们从总体上提升人工智能水平。事实是,在上述绝大多数以游戏为基础的比赛中,我们已经看到,参赛人工智能每次表现都更好了。但是,在绝大多数情况下,表现的提高并不是因为改善了人工智能算法,而是因为针对某些具体问题使用这些算法的方式更加聪明了。有时,这意味着人工智能的角色更加边缘化。比如,在第一年的赛车比赛中,几乎都是采用演化算法训练神经网络,让汽车跑在赛道上的人工智能。后来,大多数最好的参赛者使用了手动的「笨」方法让车跑在赛道上,但是使用了学习算法学习轨道的形状,调整行驶。这是一个解决特殊工程问题的聪明方法,但是,几乎没有一般智能方面的建树。
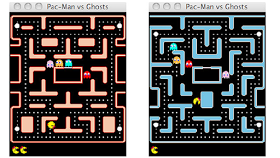
最近成功举办的一次人工智能竞赛使用了Ms.Pac-Man 这款游戏 ,来自全世界的学者、学生以及爱好者提交了他们人工智能Pac-Man玩家。游戏比赛激励研究者为了领先,发明出新的高端算法。不幸的是,到目前为止,最好的计算机玩家还不如中游的人类玩家。
为了确定这种竞赛是在测试接近人工智能的对象,我们需要重塑问题。为此,定义我们试图测量的对象——一般智能(general intelligence)——是个不错的主意。Shane Legg与Marcus Hutter提出了一个非常有用的关于智能的定义,大致就是一个代理(agent)在所有可能问题上的平均成绩。(在它们的最初方程中,每个对平均成绩有贡献的问题都会依据其简易性而被赋予权重,但是,让我们暂时忽略这一点)。很显然,在所有可能的问题上测试人工智能并不可能,因为问题是无限的。但是,也许我们可以用大量不同的问题来测试人工智能。例如,用大量不同的电子游戏?
想到的第一件事就是利用现有的一堆游戏机游戏,最好是能轻易模拟且能加速到实时速度许多倍的游戏,并搭建一个以此为基准的人工智能。这就是 Arcade Learning Environment (ALE)所做的事情。ALE可以让你在一百多个上世纪七十年代为复古雅达利2600游戏机发布的游戏上测试你的人工智能。人工智能代以像素级别来认识屏幕,必须用操纵杆来回答。ALE被用于大量实验,包括框架的最初研发人员做的实验。也许,最著名的就是谷歌Deep Mind在《Nature》上所发表的一篇论文,介绍了他们如何利用深度学习这样非凡的技能来学习不同游戏(基于深层卷积神经网络的Q型学习)。

Atari2600电子游戏。注意背景电视上1977年格斗游戏的复古画面图像。也请注意1977年复古的木质部分。你现在的游戏机很可能都没有这一木质部分。没有显示在图片中的:128bytes储存记忆。比起现在的手机少了几百万倍。
ALE是一个很好的人工智能基准,但是,有一个致命的局限性。利用Atari 2600电子游戏的问题在于,游戏数量是有限的,而且研发新游戏是一个麻烦的过程。Atari 2600编程之难,臭名昭著,而且游戏机的硬件局限性也妨碍了可加使用的游戏类别。更重要的是,既有游戏全部都是家喻户晓的,每个人也可以弄得到。这就有可能针对每一个特定游戏来调适你的人工智能。不仅可以针对每个游戏训练你的人工智能(DeepMind取得的成果就是靠每种游戏玩上成千上万次来训练系统),还可以为了在将要训练的游戏上表现更好,调适整个系统。
我们还能做得更好吗?是的,可以。如果我们想要大概了解人工智能可能产生的任何问题,那么,最好的办法就是对闻所未见的问题主动出击,进行测试。也就是说,人工智能设计者在测试之前并不知道哪些问题是之前测试过的。至少,这是我们设计GVGAI(the General Video Game Playing Competition- 通用电玩竞赛)的初衷。

Atari2600中的「青蛙过河」
借助GVG,任何人都可以为他们最好的人工智能选手「报名」,在这个特殊的服务器上,人工智能选手可以「玩」十个从未见过的游戏(除了竞赛组织者)。这些游戏的类型是八十年代早期个人电脑或者掌机上见过的类型;有些设计就是基于很多耳熟能详的游戏,比如钻石小子,吃豆人、太空侵略者、推箱子、导弹指令。比赛的获胜者无疑是在这些没有接触过的游戏中表现最好的人工智能「选手」。因此,人工智能设计师没办法针对某个特定游戏调适他们的软件。GVGAI大约有50个游戏可以用来训练你的人工智能,每次迭代都会推出更多游戏。
「青蛙过河」——通用电玩竞赛平台上用VGDL重新编译后的版本。
目前,50个游戏并不是一个大的数目;我们如何获取新的游戏呢?首先,所有游戏必须经过一种被称为「电玩描述语言」的标准进行编程。我们设计出这种简单的语言用来编写游戏,同时满足嵌入性和可读性的条件,类似网页编辑所用的HTML。这种语言的设计主要是为了可以解码经典的掌机游戏;这意味着所有游戏的设计都是基于动作和交互这两个维度。在Wolfenstein3D面世前,这两项是所有电玩设计中最重要的。无论如何,这种语言的简单性方便了新游戏创作,不论是从头开始制作或者是对现存游戏进行变化。(捎带说下,作为此项目的分支,我们正在探索VGDL作为游戏开发的原型工具。)
VGDL编写出的简单版本的经典猜谜游戏推箱子。
即使是将编写游戏这件事简单化了,仍然无法解决一个根本问题——还是需要有人进行编写和设计。由于GVG-AI的定位是能够最大可能的满足人工智能测试,我们需要源源不绝的游戏产生出来。因此,我们需要自动生成,需要有软件能够实现:只需点一下,就有新游戏产生,而这些游戏也不能太过简单,要是那种需要人工智能玩家具备一定技巧的好游戏。(副作用是,人类玩家可能也喜欢玩。)
VGDL版本的钻石小子。
我知道,设计出可以设计新游戏的软件听起来非常困难。然而,我们已经试图攻克该领域多年,我坚信这件事是可行的。Cameron Browne已经成功搭建了一个设计棋盘游戏的生成器,而我们最近的一些工作正致力于自动生成简单的VGDL游戏,尽管距离成功仍需时日。并且,生成游戏的一部分明显可行,比如游戏等级;过去五年,有很多研究专注于进度内容生成——游戏内容的自动生成。研究人员已经证实,诸如演化算法,计划以及回答设定编程之类的方法能够自动创造等级、地图、故事、项目和几何图形状,基本上可以生产游戏的其他任何内容类型。现在,研究的挑战在于泛化这些方法(意味着可以使用在任何游戏上,而不是针对某个特定游戏),让这些方法更具综合性,以便他们能够生成各种游戏元素,包括游戏规则。大多数生成方法包括对正被生成的游戏进行某种形式的模拟,这意味着玩游戏和游戏生产的问题是错综复杂联系在一起的,任何时候都应该一并思考。

Yavalath是一款完全由电脑程序设计出的棋盘游戏,该程序由Cameron Browne设计,证明电脑可以设计出完整的游戏。
一旦用自动游戏生成扩展通用电玩竞赛,我们就有好得多的办法来测试玩游戏的水平。当然,在比赛之外,软件也有用途,提供了一个简单测试玩游戏的人工智能一般智能水平的办法。
到目前为止,我们只谈到如何最好地测试或评估一种计算机程序的一般智能,而不是如何创造一个。嗯,这篇文章的主旨是阐述为何电玩游戏是创造人工智能必不可少的,我相信我已经解释的非常全面了: 作为衡量人工智能水平的一种公平且准确的基准。但出于完整性考虑,我们还是需要考虑创造出此类人工智能最有前途的方法。如上文所述,(深度) 神经网络最近吸引了大量关注是由于其图形识别中获得了惊人高的正确率。我相信,神经网络和类似的图形识别方法在对游戏进行评估和提供改进建议方面可以发挥重要作用。在许多情况下,针对游戏训练神经网络时,演化算法要比梯度方法更合适。
但是,智能并不仅限于模式识别。(同样,行为主义也不能完全解释人类行为:人类并不仅仅是在刺激与反应之间建立起映射,他们也会思考。)智能也必须吸收一些计划行为,在我们做出决定之前,行为的未来影响也会是刺激的一部分。最近,一种叫做Monte Carlo Tree Search的算法,通过对随机行为进行统计,模拟长系列行为后果,这个算法已经在棋盘游戏Go.中创造奇迹。在GVGAI中表现良好。最近在游戏计划任务中展现出巨大潜质的另一个算法家族是 rolling horizon evolution。这里,演化算法不仅被用于长期学习,还被用于短期行动计划。
我认为,通用电子游戏人工智能的下一波发展浪潮会来自神经网络、进化与树搜索的创造性结合。重要之处在于,对各种不同功能来说,模式识别和计划都是必须的。就像研究中经常遇到的情况,我们无法预测研究结果会如何(否则,就算不上研究了),但是,我打赌探索这些方法的各种组合会为研发下一代人工智能算法提供灵感。

要想玩转诸如The Elder Scrolls V: Skyrim这样的游戏需要掌握很多认知技巧
现在,你可能会反对说,这是一个非常逼仄的智能和人工智能观。那文本识别,听力理解,讲故事,肢体协调,讽刺和浪漫呢?我们的游戏人工智能可做不到这些,无论它能否玩转世上所有的电脑游戏。对此,我要说:耐心点!所有这些并不需要玩早期电脑游戏,这点没错。但是,当我们掌握了这些游戏并继续玩其他类游戏时,比如角色扮演,冒险游戏,模仿游戏以及社交网络游戏,玩好这些游戏需要掌握很多技巧。当我们掌握的游戏多样性越来越多,玩转游戏所需的认知技能广度也会递增。当然,我们的游戏人工智能必须进步更多才能应对地过来。理解语言,图像,故事,面部表情以及幽默感都是必须的,也不要忘记,与通用视频游戏挑战紧密相随的是来自生产通用视频游戏的挑战,这需要足够的其他类型智能。我确信,视频游戏(一般意义上的)会对所有形式的智能构成挑战,除了那些与身体运动密切相关的游戏,因此,视频游戏(一般意义上)是人工智能最好的测试台。无论采取何种标准,一个能玩几乎所有游戏并能创作各种视频游戏的人工智能就是智能的。

诸如Civilization V这样的游戏需要不同但丰富的技巧组合才可以玩得很棒
这篇博文开始变得很长——我原来计划的长度只是现在的一部分。但是,要解释的东西也很多。如果你已经读到这里,可能已经忘掉文章最开始的内容了。我来重复一下:拥有好的测试台对人工智能研究来说很关键。游戏就是人工智能的测试台,因为它们为人工智能提供了各种挑战,和机器人学一样,而且非常吸引人。
但是,它们也比较简单,便宜和快速,许多用机器人学无法切实实践的研究也都因此成为可能。这一领域最一开始,棋盘游戏就被用于人工智能研究中了,但是最近十年,越来越多的研究人员已经进入视频游戏领域中,因为游戏提供了更具多样性的相关挑战。(他们也更加有趣)。
竞赛在当中扮演了关键角色。但是,为了某个单一游戏,在人工智能上附注太多努力会在总体上限制人工智能的价值。因此,我们创造出通用电玩竞赛( General Video Game Playing Competition ),以及与之相关的软件框架。这意味着,它要成为针对通用智能的最全面的以游戏为基础的基准。通过玩多种人工智能设计者之前没有见过的游戏(而不是仅仅一种)来评估人工智能。通用电子游戏的下一个突破可能就会来自神经网络,演化算法以及Monte Carlo树搜索的组合。
与玩这些游戏挑战紧密相连的是生产新游戏和为这些游戏生产新内容的挑战。计划的目的在于让测试人工智能的游戏供给源源不断。尽管玩游戏和生产简单的电脑游戏对大量不同认知能力进行测试—— 比其他任何一种人工智能基准都要更具多样性——但是,我们目前仍没抵达测试所有智能的阶段。不过,考虑到玩转和设计现代视频游戏所需的各种智能,也没理由说我们到不了那里。如果你想更多了解这些课题,我已经在上述部分对各种博文,文章以及书籍做了链接。我目前在做的大多数研究(以及我们在纽约大学游戏创新实验室做的),是以某种方式与我在此处描绘的整体计划联系在一起的。
最近,我将过去几年研究回顾做了一个集合,并与自己最近研究做了链接。更多的文章可以在我的网页找到。认识到这一工作中的大部分内容都具有双重目的—— 促进人工智能发展和让游戏更有趣—— 很重要。我们正在研发的许多技术或多或少关注的是改善游戏。针对特定游戏提升人工智能这方面,仍有重要工作要做,这一点也很重要。
在最近的另一篇博文中,我试着想象,如果我们已经拥有真实人工智能,视频游戏会是什么样子?我最近写了一篇论文试着勾勒出游戏当中整个人工智能领域的轮廓,但是,内容很长和很复杂,我建议你先阅读博文游戏开发中的人工智能 拜拜,再去阅读文章。你也可以精读 Computational Intelligence and Games 和Artificial Intelligence and Interactive Digital Entertainment conference series的会议记录。
最后,注意这一点很重要:这一路线的研究还有很大的空间,你们可以参与进来,因为还有很多很多的开放研究问题。如果你尚未从事这方面的研究,我认为你应该开始了。它让人激动,因为它就是未来。你还等什么呢?
 上一篇
上一篇 








