

unity3d研究院之游戏开发中的人工智能ai-unity3d游戏开发 pdf
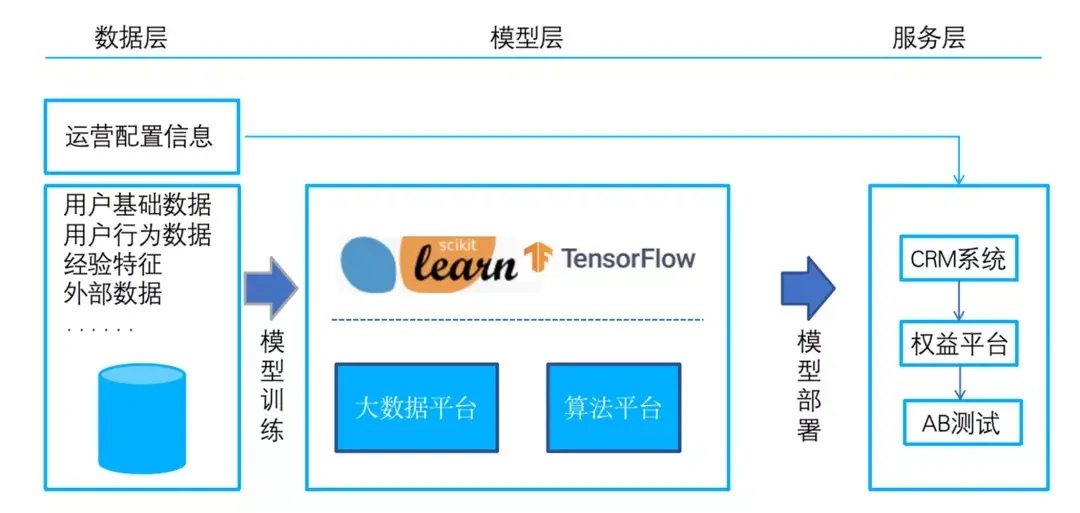
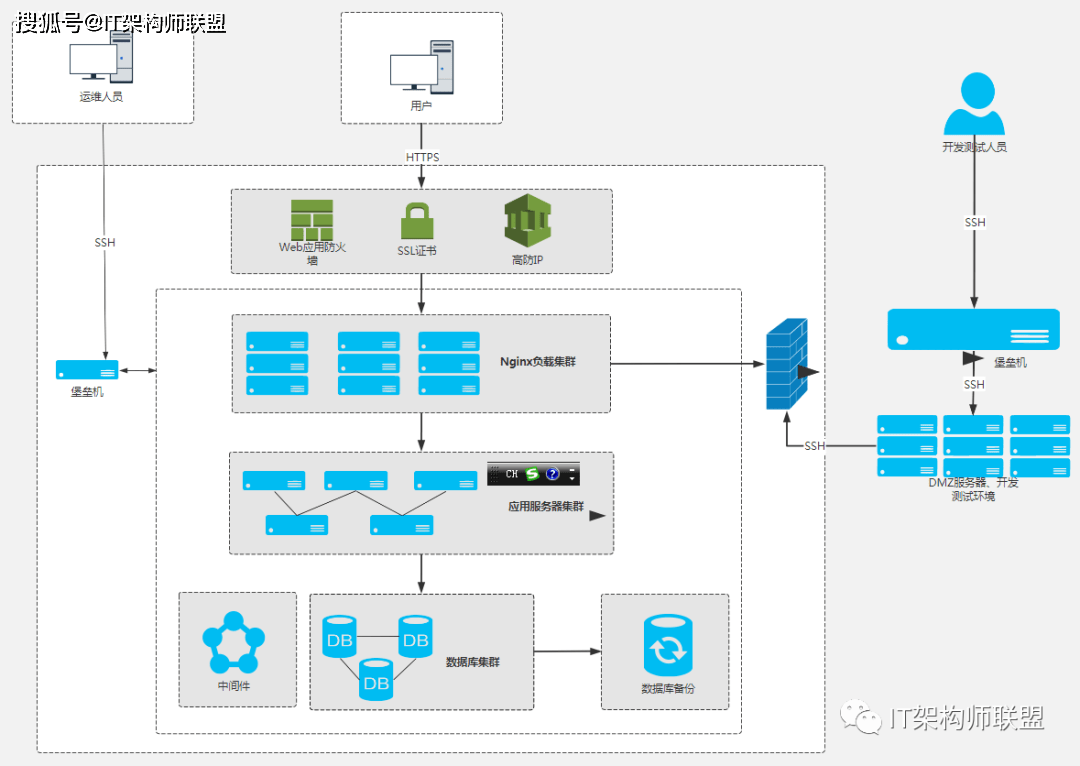
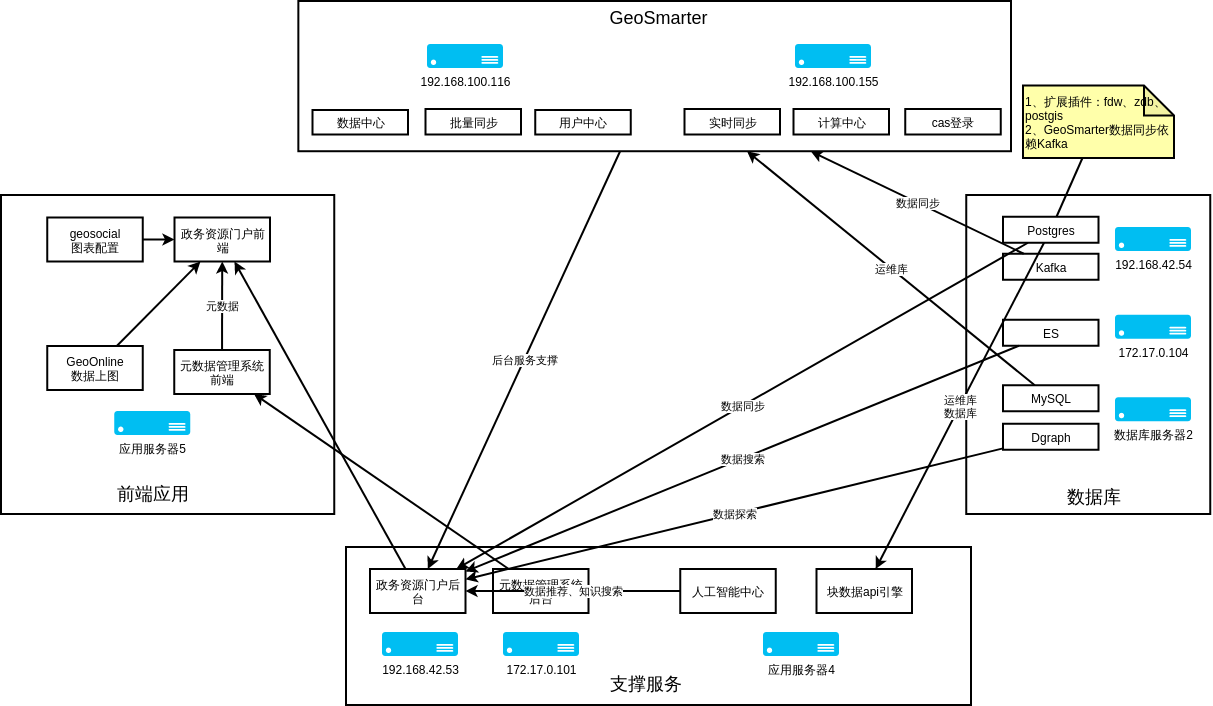
使用现代工具可以很容易地进行机器学习系统的开发和部署,但是这个过程通常是很仓促的。一方面缺乏尽职的调查可能导致技术债务、范围蔓延、目标错位、模型误用与失败等代价高昂的后果。另一方面,为了简化开发,获得高质量、可靠的结果,工程系统会遵循定义好的流程和测试标准。
最极端的是航天器系统unity3d研究院之游戏开发中的人工智能ai,在开发过程中,关键任务措施和鲁棒性已根深蒂固。根据航天器工程和 ML 的经验,来自 NASA、微软研究院等多家机构的研究人员为机器学习开发和部署开发了一个经过验证的系统工程方法:机器学习技术准备水平 (Machine Learning Technology Readiness Levels,MLTRL) 框架,该框架定义了一个可确保原则性的过程,以保证系统的鲁棒性、可靠性和负责任度,同时对 ML 工作流进行优化,包括与传统软件工程的关键区别。
更重要的是,MLTRL 定义了一种通用语言,可使不同团队和组织的人员能够在人工智能和机器学习技术上协同工作。研究人员在论文中描述了这个框架,并举例说明,所用示例涉及基础研究、产品化和部署等,覆盖医学诊断、消费者计算机视觉、卫星图像和粒子物理等多个领域。
论文链接:
MLTRL 框架
MLTRL 定义了技术准备水平 (TRL) 以指导和沟通 AI 和 ML 的开发与部署。TRL 表示模型或算法、数据 pipeline、软件模块或其组成的成熟度;典型的 ML 系统由许多相互关联的子系统和组件组成,系统的 TRL 是其组成部分的最低级别。对一个层级的分解是由关卡式评审(gated review)、不断发展的工作组、具备风险计算的需求文档、渐进的代码和测试标准,以及诸如 TRL 卡(图 3)和伦理检查表之类的可交付成果来标记的。
MLTRL 的层级如下图所示:
图 1:MLTRL 通过原型设计、产品化和部署进行研究。图 1:MLTRL 通过原型设计、产品化和部署进行研究。

大多数 ML 工作流规定了数据处理、训练、测试和服务模型的孤立的线性过程 [6]。但这些工作流没有定义 ML 开发过程中如何迭代此基本过程,使其变得更成熟、更具有鲁棒性,也没有定义如何与包含软件、硬件、数据和人员的更大型系统进行集成。此外,MLTRL 在部署之后仍没有停止:对于产品生命周期持续的可靠性以及改进而言,监测与反馈循环非常重要。
Level 0 第一原则:该阶段针对 AI 新研究,主要包括文献综述、构建数学基础、white-boarding 概念和算法unity3d研究院之游戏开发中的人工智能ai,以及构建对数据的理解。对于理论 AI 和 ML 的研究,目前还没有数据可供使用。
Level 1 目标导向研究:从基本原理到实际应用,研究人员设计并运行低层级实验来分析特定的模型 / 算法属性。
Level 2 原理验证(PoP)开发:主要通过在试验台上的开发和运行来启动积极研发:模拟环境或与真实场景的条件和数据紧密匹配的替代数据。注意,这些是由特定于模型的技术目标所驱动的,不一定是应用或产品目标。
Level 3 系统开发:这里有一些检查点,将代码开发推向互操作性、可靠性、可维护性、可扩展性和可伸缩性。代码成为原型校准器(prototype-caliber):研究代码在鲁棒性和整洁性方面迈出的一大步。

Level 4 概念验证 (PoC) 开发:旨在真实场景中演示技术。这一阶段是应用驱动开发的种子;对于许多组织来说,这是与研发组以外的产品经理和利益相关者的第一个接触点,可帮助定义最终生产系统的服务水平协议(SLA)和服务水平目标(SLO)。
Level 5 机器学习能力:在这一阶段,技术不仅仅是孤立的模型或算法,还是一种特定的能力,例如基于移动机器人的立体视觉传感器生成深度图像。在许多组织中,这代表了从研发到产品化的技术过渡或转移。MLTRL 使这一转变变得明确,发展必要的工作、指导性文档、目标和度量以及团队;事实上,如果没有 MLTRL,这一阶段被错误地跳过是很常见的,如下图所示:
Level 6 应用开发:这里的工作重点是大量软件工程,使代码达到产品水平:此代码将部署给用户,因此需要遵循精确的规范、广泛的测试覆盖率、定义良好的 API 等。生成的 ML 模块应该针对一或多个目标用例进行鲁棒化。
Level 7 集成:为了将技术集成到现有的生产系统中,该研究建议工作小组在基础设施工程师和应用 AI 工程师之间保持平衡——这一阶段的开发易受潜在模型假设和故障模式的影响,因此不能完全由软件工程师开发。
Level 8 Flight-ready:该阶段应执行额外的测试,包括部署方面的测试,尤其是 A/B 测试、蓝绿部署测试、阴影测试、金丝雀测试。该阶段对不断变化的 ML 方法和数据进行主动和渐进的测试。
Level 9 部署:在部署 AI 和 ML 技术方面,监控当前版本并明确考虑改进下一个版本是非常有必要的。例如,性能下降可能是隐藏的,这种情况很危险,而特性改进通常会带来意想不到的后果和限制。因此,在这一层级上,需要使用维护工程(即监测和更新方法)。
应用示例
在实际应用场景中,AI 和 ML 面临很多挑战和风险,MLTRL 旨在缓解这些挑战和风险。如果这些问题不解决,将会导致意想不到的、代价昂贵的后果,如医疗误诊、偏差决策。
有人类参与的神经病理学工作
隐藏反馈循环:在现实世界系统中,隐藏反馈循环很常见,但它存在一些问题,并且会影响训练数据:随着时间的推移,用户行为可能会演变成为特定的 AI 系统选择他们偏好的数据输入,这可能导致训练数据存在偏差。在这种情况下,选择全视野数字病理切片对于人工检查而言最为困难,甚至会受个人用户偏见的影响。类似地,研究发现底层医疗流程可能成为隐藏的混杂因素,导致不可靠的决策支持工具 [18]。MLTRL 通过要求特定于 ML 的测试(在本例中是阴影测试与监测数据不变量)和 TRL 卡来提供帮助,使所有人都能看到隐藏的反馈循环(参见下图)。
计算机视觉
物理引擎和图形处理方面的进展,推动了 AI 环境和数据生成能力的发展,同时更加强调了跨越模拟 - 现实差距的模型转换。为了开发一个用于自动回收的计算机视觉应用,研究人员使用了 Unity Perception,这是一个为基于感知的 ML 训练和验证生成大规模数据集的工具箱。使用 Unity Perception,研究人员生成了合成图像,以补充真实世界的数据源(图 4)。这一应用包含了机器学习产品开发所面临的两大挑战:处理混合数据源以及隐藏的性能下降。而 MLTRL 可以帮助解决这些问题。
图 4:用于自动回收应用程序的计算机视觉 pipeline(a)
 上一篇
上一篇 








