

sql数据库同步方式-flash声音同步方式
前言
众所周知,随着用户数量的增加,数据库操作往往成为系统的瓶颈,而一般系统中“读”的压力远大于“写”,因此我们可以提高系统的性能通过从数据库中分离读取和写入。 表现。
实施思路
通过设置主从数据库实现读写分离,主库负责“写操作”,从库负责“读操作”。 根据压力情况,可以部署多个从库,以提高“读”的速度,从而提高系统整体性能。
基础知识
1、要实现读写分离,就要解决主从数据库数据同步的问题。 在主库中写入数据后,需要保证从库中的数据也被更新。
主从数据库同步的实现思路如图:
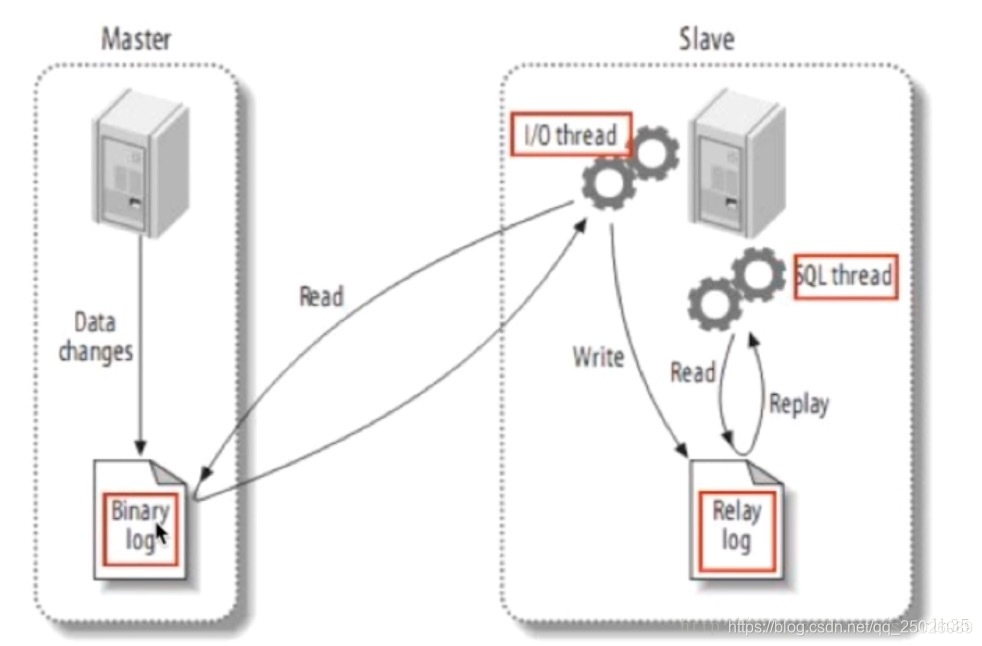
主从同步
主服务器master将数据库操作日志记录到Binary log,从服务器启动I/O线程将二进制日志记录的操作同步到relay log(保存在从服务器的缓存中), sql线程记录relay log日志在slave server上执行的操作。
记住这张图,接下来就是根据这张图实际搭建主从数据库了。
主从数据库设置的具体步骤
首先,要有两台数据库服务器,master和slave(也可以用一台服务器安装两套数据库环境,分别运行在不同的端口,可以类推设置多台slave)。 我们穷人买个虚拟云服务器玩玩就行了。 0.0。 以下操作假设你的两台服务器都安装了mysql服务。
1.打开mysql数据库配置文件
vim /etc/my.cnf
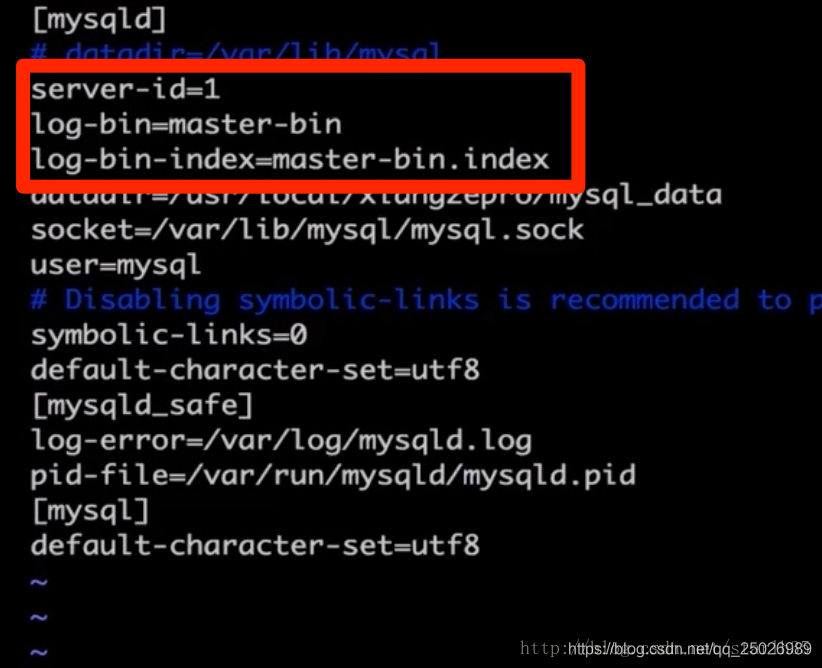
2、在主服务器master上配置并启用Binary log,主要是在[mysqld]下添加:
服务器-id=1
log-bin=master-bin
log-bin-index=master-bin.index
如图所示:
3.重启mysql服务
服务 mysql 重新启动
ps:重启方式随机
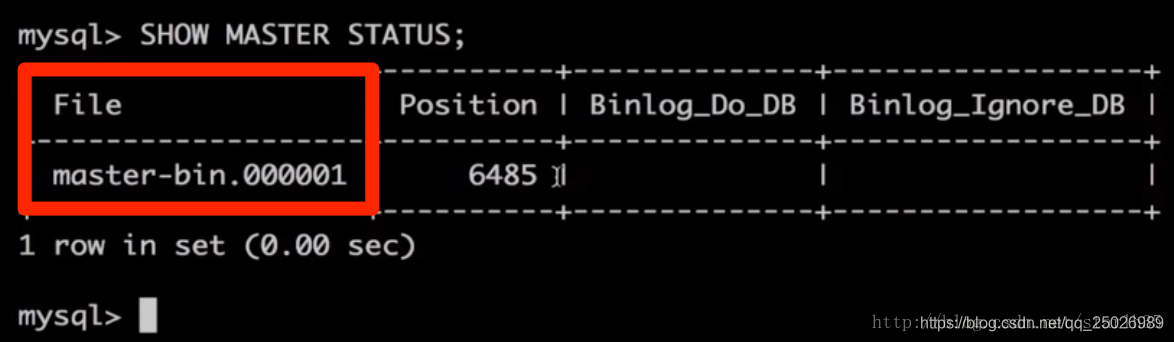
4.查看配置效果,进入master数据库执行
mysql> 显示主状态;
可以看到下图说明配置OK了。 这里的文件名:master-bin.000001 我们接下来在从库的配置中会用到它:
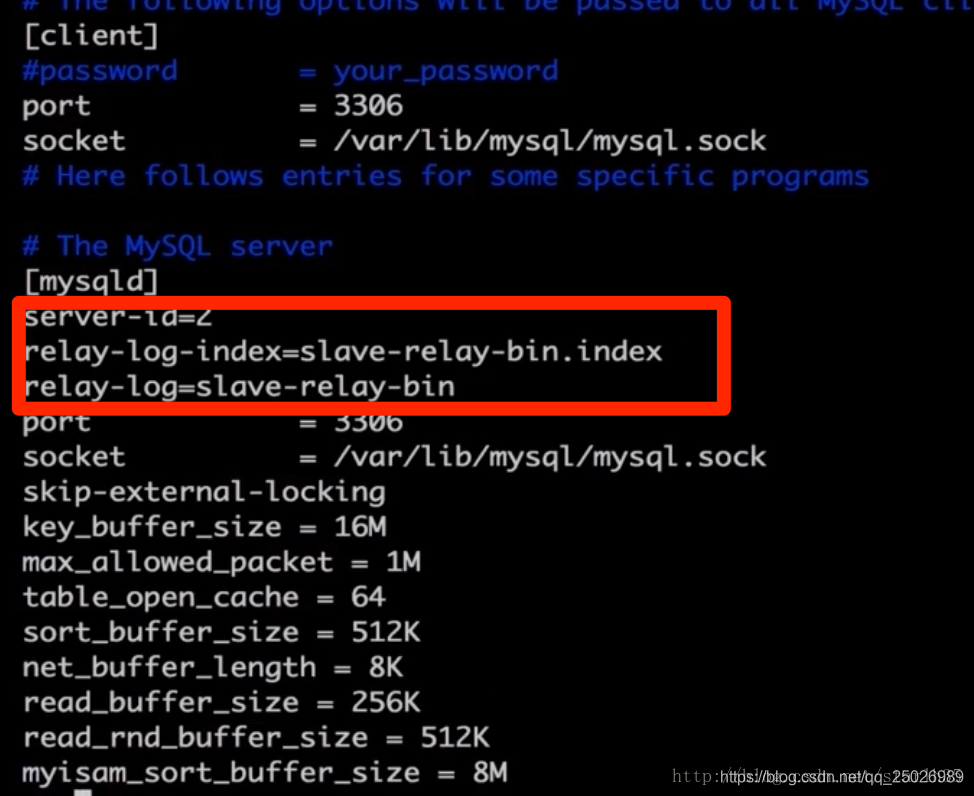
5.从服务器配置my.cnf
在[mysqld]节点下添加:
服务器-id=2
中继日志索引=slave-relay-bin.index
中继日志=从中继站
这里的server-id一定要和主库的不一样,如图:
配置完成后重启slave数据库
服务 mysql 重新启动
6.接下来配置两个数据库的关联
首先我们先创建一个操作主从同步的数据库用户,切换到主库执行:
mysql> 创建用户 repl;
mysql> GRANT REPLICATION SLAVE ON 。 TO 'repl'@'from xxx.xxx.xxx.xx' 由 'mysql' 识别;
mysql> 刷新权限;
这个配置的意思是创建一个数据库用户repl,密码为mysql。 从服务器使用repl账号连接主服务器时,会被授予REPLICATION SLAVE权限。 从表面上看,这个权限是针对master数据库中的所有表的。 , 其中 xxx 是从服务器的 ip 地址。
进入从库后,执行:
mysql> 将 master 更改为
master_host='master xxx.xxx.xxx.xx', master_port=3306, master_user='repl', master_password='mysql', master_log_file='master-bin.000001', master_log_pos=0;
这里的xxx是主服务器的IP,同时配置了端口。 Repl代表访问主数据库的用户。 以上步骤完成后,执行启动slave配置:
mysql> 启动从站;

停止主从同步的命令是:
mysql> 停止从站;
查看状态命令sql数据库同步方式,\G表示换行查看
mysql> 显示从站状态 \G;
可以看到状态如下:
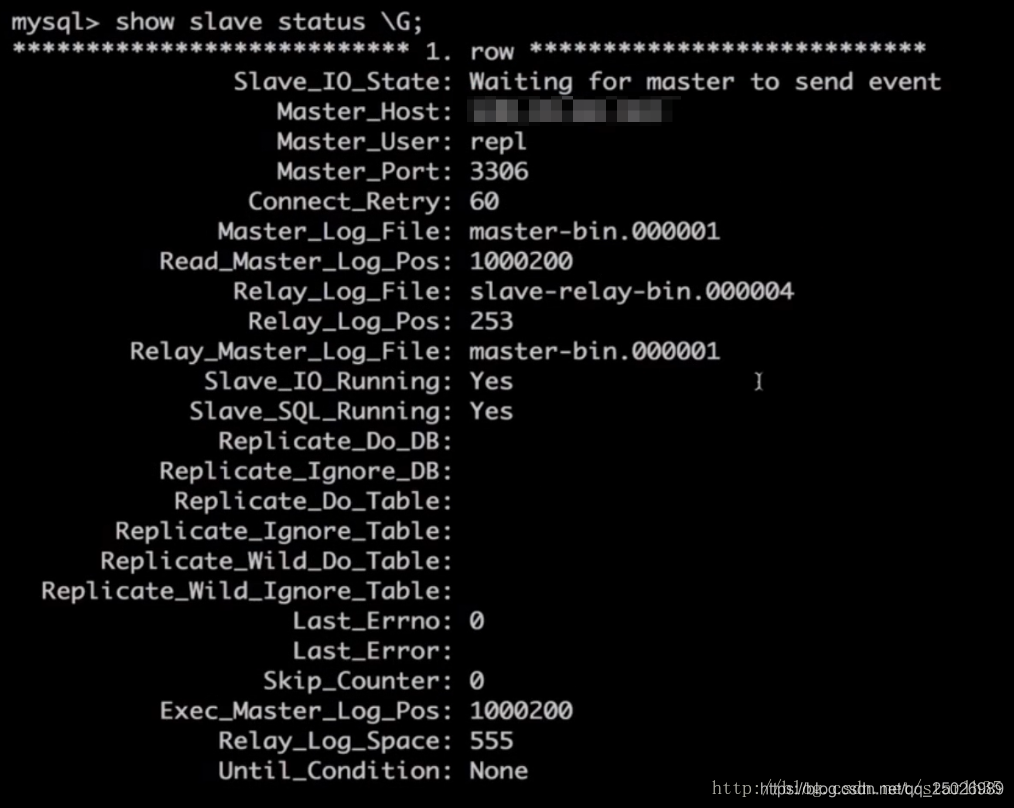
这里我们可以看到从库已经在等待主库的消息了,接下来在主库中的操作会在从库中执行。 我们可以使用主库负责写,从库负责读(不要对从库进行写操作),从而达到读写分离的效果。
我们可以简单地测试一下:
在主数据库中创建一个新数据库:
mysql> 创建数据库 testsplit;
从数据库查看数据库:
mysql> 显示数据库;
可以看到还有一个来自数据库的testsplit表,这里就不放图了,个人测试用。 在master数据库中插入数据,从数据库中也可以查到。
至此,数据库主从同步已经实现
代码层面实现读写分离
上面我们已经有两个数据库,并且实现了主从数据库同步。 接下来的问题就是要在我们的业务代码中实现读写分离。 假设我们使用的是主流ssm框架开发的web项目。 这里我们需要多个数据源。
在此之前,我们在项目中通常会使用一个数据库用户来远程操作数据库(避免直接使用root用户),所以我们需要在主从数据库中都创建一个用户mysqluser,并赋予其增删改查的权限,修改查询:
mysql> GRANT 选择、插入、更新、删除 ON 。 TO 'mysqluser'@'%'
由'mysqlpassword' WITH GRANT OPTION 标识;
然后我们在我们的程序中使用mysqluser用户来操作数据库:
1.编写jdbc.propreties
#mysql驱动
jdbc.driver=com.mysql.jdbc.Driver
#主数据库地址
jdbc.master.url=jdbc:mysql://xxx.xxx.xxx.xx:3306/testsplit?useUnicode=true&characterEncoding=utf8
#从数据库地址
jdbc.slave.url=jdbc:mysql://xxx.xxx.xxx.xx:3306/testsplit?useUnicode=true&characterEncoding=utf8
#数据库账号
jdbc.username=mysqluser
jdbc.password=mysqlpassword
这里我们指定了两个数据库地址,其中xxx是我们主从数据库的ip地址,默认端口是3306
2.配置数据源
在spring-dao.xml中配置数据源(这里不介绍spring的配置,假设大家已经配置好运行环境),配置如下:
阐明:
首先读取配置文件jdbc.properties,然后我们定义一个基于c3p0连接池的父类“抽象”数据源,然后配置两个具体的数据源master和slave,继承abstractDataSource,这里配置的具体属性数据库连接,然后我们配置动态数据源,这将决定使用哪个具体的数据源。 这里的关键是DataSourceSelector,接下来我们来实现这个bean。 接下来就是设置数据源的懒加载,保证数据源加载的时候已经加载了其他依赖的bean。然后就是常规的配置了。 我们的mybatis全局配置文件如下
3.mybatis全局配置文件
这里的关键是DateSourceSelectInterceptor拦截器,拦截所有的数据库操作,然后分析SQL语句判断是“读”操作还是“写”操作。 接下来,我们将实现上述的DataSourceSelector和DateSourceSelectInterceptor
4.编写DataSourceSelector
DataSourceSelector就是我们在spring-dao.xml中配置的,动态配置数据源。 代码如下:
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
/**
* @author lihang
* @date 2017/12/6.
* @description 继承了AbstractRoutingDataSource,动态选择数据源
*/
public class DataSourceSelector extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
return DynamicDataSourceHolder.getDataSourceType();
}
}
我们只要继承AbstractRoutingDataSource,重写determineCurrentLookupKey()方法,就可以动态配置我们的数据源。
编写DynamicDataSourceHolder,代码如下:
/**
* @author lihang
* @date 2017/12/6.
* @description
*/
public class DynamicDataSourceHolder {
/**用来存取key,ThreadLocal保证了线程安全*/
private static ThreadLocal contextHolder = new ThreadLocal();
/**主库*/
public static final String DB_MASTER = "master";
/**从库*/
public static final String DB_SLAVE = "slave";
/**
* 获取线程的数据源
* @return
*/
public static String getDataSourceType() {
String db = contextHolder.get();
if (db == null){
//如果db为空则默认使用主库(因为主库支持读和写)
db = DB_MASTER;
}
return db;
}
/**
* 设置线程的数据源
* @param s
*/
public static void setDataSourceType(String s) {
contextHolder.set(s);
}
/**
* 清理连接类型
*/
public static void clearDataSource(){
contextHolder.remove();
}
}
这个类决定返回的数据源是master还是slave。 我们需要使用 DateSourceSelectInterceptor 来初始化这个类。 我们拦截所有的数据库操作请求,通过分析SQL语句来判断是读操作还是写操作。 读操作设置slave为DynamicDataSourceHolder源,写操作设置master源,代码如下:
我
mport org.apache.ibatis.executor.Executor;
import org.apache.ibatis.executor.keygen.SelectKeyGenerator;
import org.apache.ibatis.mapping.BoundSql;
import org.apache.ibatis.mapping.MappedStatement;
import org.apache.ibatis.mapping.SqlCommandType;
import org.apache.ibatis.plugin.*;
import org.apache.ibatis.session.ResultHandler;
import org.apache.ibatis.session.RowBounds;
import org.springframework.transaction.support.TransactionSynchronizationManager;
import java.util.Locale;
import java.util.Properties;
/**
* @author lihang
* @date 2017/12/6.
* @description 拦截数据库操作,根据sql判断是读还是写,选择不同的数据源
*/
@Intercepts({@Signature(type = Executor.class,method = "update",args = {MappedStatement.class,Object.class}),
@Signature(type = Executor.class,method = "query",args = {MappedStatement.class,Object.class, RowBounds.class, ResultHandler.class})})
public class DateSourceSelectInterceptor implements Interceptor{
/**正则匹配 insert、delete、update操作*/
private static final String REGEX = ".*insert\\\\u0020.*|.*delete\\\\u0020.*|.*update\\\\u0020.*";
@Override
public Object intercept(Invocation invocation) throws Throwable {
//判断当前操作是否有事务
boolean synchonizationActive = TransactionSynchronizationManager.isSynchronizationActive();
//获取执行参数
Object[] objects = invocation.getArgs();
MappedStatement ms = (MappedStatement) objects[0];
//默认设置使用主库
String lookupKey = DynamicDataSourceHolder.DB_MASTER;;
if (!synchonizationActive){
//读方法
if (ms.getSqlCommandType().equals(SqlCommandType.SELECT)){
//selectKey为自增主键(SELECT LAST_INSERT_ID())方法,使用主库
if (ms.getId().contains(SelectKeyGenerator.SELECT_KEY_SUFFIX)){
lookupKey = DynamicDataSourceHolder.DB_MASTER;
}else {
BoundSql boundSql = ms.getSqlSource().getBoundSql(objects[1]);
String sql = boundSql.getSql().toLowerCase(Locale.CHINA).replace("[\\t\\n\\r]"," ");
//如果是insert、delete、update操作 使用主库
if (sql.matches(REGEX)){
lookupKey = DynamicDataSourceHolder.DB_MASTER;
}else {
//使用从库
lookupKey = DynamicDataSourceHolder.DB_SLAVE;
}
}
}
}else {
//一般使用事务的都是写操作,直接使用主库
lookupKey = DynamicDataSourceHolder.DB_MASTER;
}
//设置数据源
DynamicDataSourceHolder.setDataSourceType(lookupKey);
return invocation.proceed();
}
@Override
public Object plugin(Object target) {
if (target instanceof Executor){
//如果是Executor(执行增删改查操作),则拦截下来
return Plugin.wrap(target,this);
}else {
return target;
}
}
@Override
public void setProperties(Properties properties) {
}
}
通过这个拦截器,所有的insert、delete、update操作都设置为使用master源,select将使用slave源。
下一步是测试。 这是生产环境的代码。 我直接打印日志。 小伙伴们可以添加日志,测试使用的是哪个数据源。 结果与预期相同。 这样我们就实现了读写分离~
ps:我们可以配置多个slave进行负载均衡,只需要在spring-dao.xml中添加slave1、slave2、slave3...,然后修改dataSourceSelector bean,
只需在地图标签中添加 slave1、slave2、slave3...。 具体的负载均衡策略可以在DynamicDataSourceHolder和DateSourceSelectInterceptor中实现。
最后梳理一下整个过程:
1、项目启动后,依赖bean加载完成后,我们的数据源开始通过LazyConnectionDataSourceProxy加载,会引用dataSourceSelector来加载数据源。
2. DataSourceSelector 将选择一个数据源。 我们在代码中设置默认数据源为master,初始化时默认使用master源。
3、执行数据库操作时,DateSourceSelectInterceptor拦截器拦截请求sql数据库同步方式,通过分析sql决定使用哪个数据源,“读操作”使用slave源,“写操作”使用master源。
写在后面
现在很多读写分离中间件大大简化了我们的工作,但是自己实现一个小规模的读写分离,有助于我们进一步理解数据库读写分离在业务中的实现。 咦~
 上一篇
上一篇 








