

数据库技术及应用基础教程-大数据技术全解基础,设计,开发与实践
业务创新驱动力
业务创新不是由数字驱动的,而是在深入分析各个业务环节之间关系的基础上,进行相应的业务变革,从而带来业务创新,所以关系是行为的最强预测器。
例如,零售商和超级公司可以通过分析客户与产品之间的关系来推荐产品,通过分析商品商店与供应商之间的关系来优化供应链。 这些是分析推动业务的关系的真实示例。
图数据库与其他数据库相比的优势在于:
擅长处理间接关系&建立知识网络
关系数据库具有分类帐式结构。 外键可以将信息从一个表连接到另一个表。 关系数据库可以轻松处理直接关系,间接关系将涉及缓慢的多级连接。 但是间接关系在关系数据库中很难处理。
图形数据库仅由点和线组成。 可以快速跨越多种类型的实体,并且可以处理间接关系。
间接关系示例:
一个特殊的查询场景:查到开发商是XXX,小区绿化率大于30%,200米内有大型超市,500米内有地铁,1000米内有三甲医院,高层2000米以内入学率60%以上的学校。 房价在800W以内,最近被中介看房次数最多的房子。
为什么mysql和es不适合?
MySQL一次关联几十张表
ES需要有一个非常广泛的listing列表,但是不可能搜索到这个listing周围200米范围内的大型超市。
图数据库应用(13个场景)
通过构建路网实现智能导航。
社会化商业具有高连接性的特点,如友情等。
在搜索引擎中,实体信息的精准聚合与匹配、关键词的理解、搜索意图的语义分析等;
通过识别用户语义获取搜索结果。
智能问答类似于语义搜索。 对于问题的内容,计算机首先分析问题的语义,然后将语义转化为查询语句,在知识图谱中搜索,提供与提问者最接近的答案。
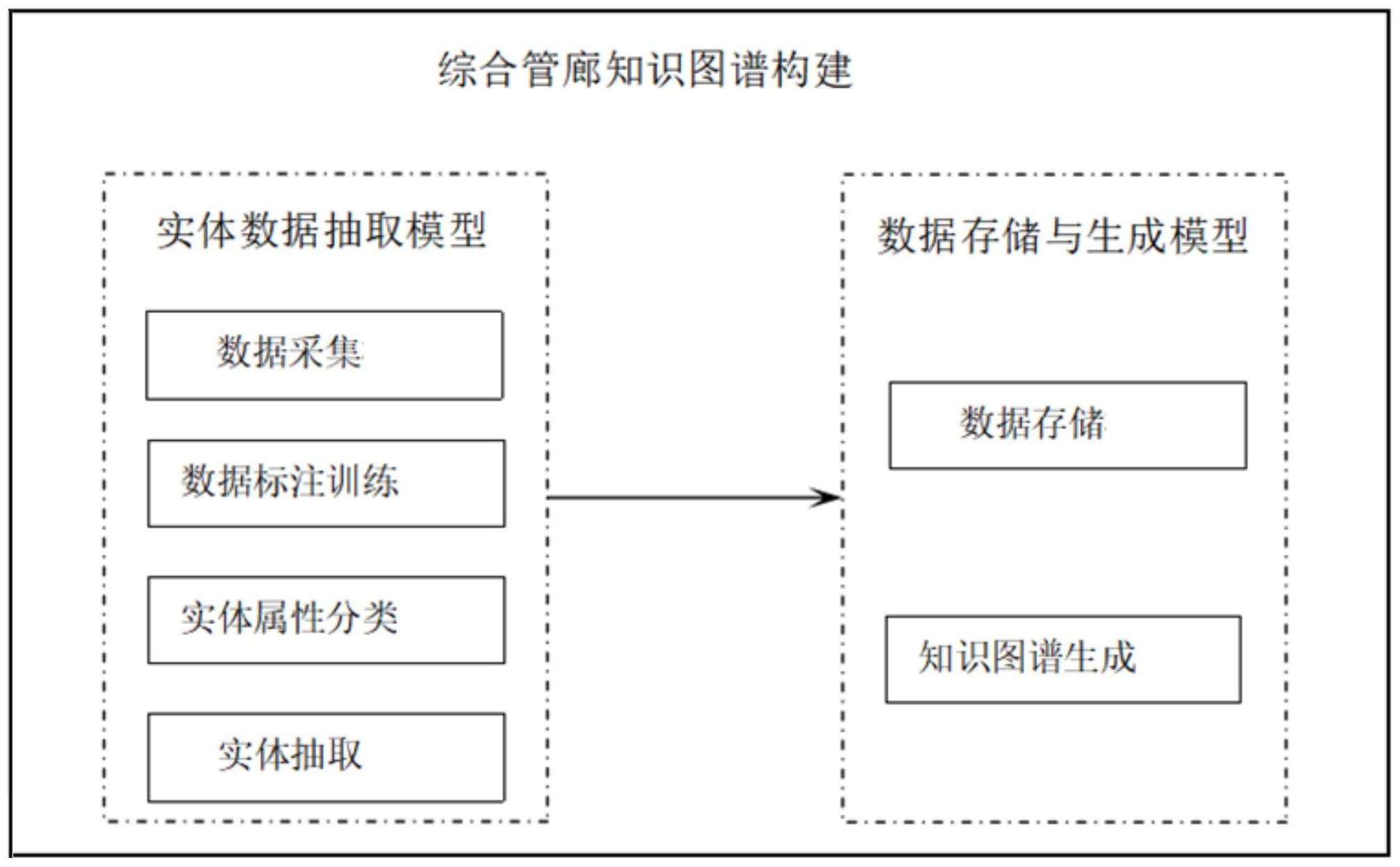
推荐系统首先要收集用户的需求,分析用户过去的数据,提取共同的特征,然后按照一定的规则向用户推荐商品。 淘宝就是一个典型的例子。
传统推荐系统的主要类型包括热门推荐、人工推荐、相关推荐和个性化推荐。
1、热门推荐:时事热点,具有广泛的社会关注度,以达到“广而告之”的效果。例如知乎、新浪微博的“热榜”等。
2. 人工推荐:由编辑或内容运营者人工推荐的优秀内容/项目
3、相关推荐:根据当前浏览的内容,根据一定的信息或关联规则进行内容推荐,主要起到“丰富和扩展”的作用。 比如看完《快乐大本营》第四期,会推荐第一期、第三期等。
4、个性化推荐:根据用户的历史记录、实时行为和个人喜好,通过算法和模型为用户量身定制推荐,达到了“想你所想”的效果
构建产品知识图谱,精准匹配用户购买意向与产品候选集,知识图谱+推荐系统;
利用实体之间的关系分析金融活动的风险,以在风险触发后提供补救措施(如反欺诈等);
当事件产生负面影响时数据库技术及应用基础教程,可以根据知识图谱的相关信息快速控制受其影响的人或事件,将损失降到最低。
分析实体与实体之间的关系,获取案件线索等;
法律条文的结构化表示和查询,用于辅助案件判断等;
为药物分析、疾病诊断等提供可视化知识表示;
建设决策课题相关知识库、政策分析模型库和情报研究方法库,构建并不断完善辅助决策系统,为决策课题提供全方位、多层次的决策支持和知识服务。
其中,知识图谱是与图数据库关系最密切、场景范围最广的应用方向。 知识图谱以图数据库为存储引擎,对海量信息进行智能处理,形成大规模的知识库,支撑业务应用。
初步知识
结构化、半结构化和非结构化数据
原始数据类型一般分为三种
实体
实体可以简单理解为对象,是图最基本的单位。 实体是指现实世界中的人、地名、概念、药物、公司等事物。
属性
实体包含几个属性,例如一个人有姓名、年龄等。属性用三元组表示(人的 ID,类型是姓名,实际姓名)。
属性图
关系
关系是实体之间的链接。 表示图中的“边”。 如人——“住”——北京,张三和李四是“朋友”。 关系通常用三元组表示。 请注意,关系也有属性。 关系的属性也用三元组表示。
关系图
三合会
三元组(主语、谓语、宾语)
三元组是指形状为((x, y), z)的集合,三元组是计算机科学的公共基础课——数据结构中的一个概念。
主要是用来存储稀疏矩阵的一种压缩方式,也叫三元表。 假设三元表用顺序存储结构表示,得到稀疏矩阵的一种压缩存储方式,即三元表,简称三元表。
简单的三重
多重关系图
那么什么是多关系图呢?
数据结构图(Graph)。 图由节点(Vertex)和边(Edge)组成,但这些图通常只包含一类节点和边。
多关系图:一般包含多种类型的节点和多种类型的边。 例如,左下图代表一个经典的图结构,而右图代表一个多关系图,因为图包含多种类型的节点和边。 这些类型用不同的颜色标记。
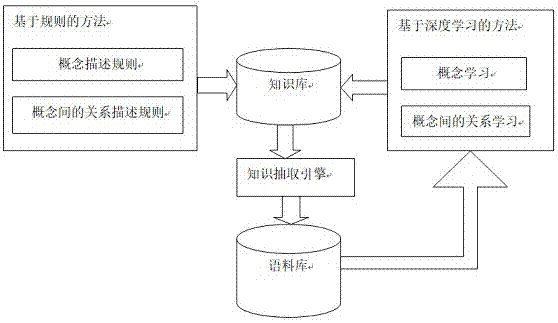
数据结构图和多关系图
图存储
学术RDF方法:
RDF方法
工业图数据库方法:
图数据库
HDT(Header, Dictionary, Triples)是RDF的一种紧凑的数据结构和二进制图标序列化格式,可以压缩大数据集以节省空间,同时保持搜索和浏览操作而无需事先解压。 这使它成为在 Web 上存储和共享 RDF 数据集的理想格式。
图和人工智能融合
知识驱动
图构建的简单架构
基础设施
数据采集
结构化数据是指关系数据库表示和存储的二维形式的数据。 这类数据可以通过Schema融合、实体对齐等技术直接提取到图中。
半结构化数据主要是指具有相关标签以分隔语义元素但不以数据库形式存在的强定义数据。 如网页中的表格数据、维基百科中的Infobox等。这类数据可以通过爬虫、网页分析等技术转化为结构化数据。
非结构化数据主要是从纯文本数据中获取知识,主要包括实体识别、实体分类、关系抽取、实体链接等技术。
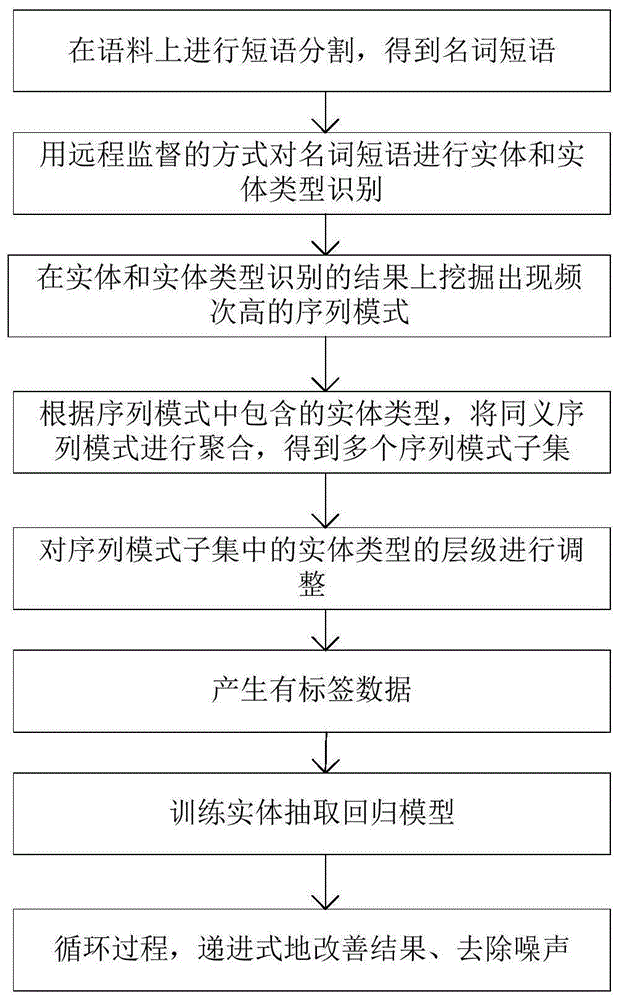
知识提取
从各类数据源中提取实体、属性以及实体之间的相互关系,并在此基础上形成本体知识表达;
实体提取
实体抽取,也称为命名实体识别,是图的核心单元。 从文本中提取实体是知识获取的关键技术。 实体抽取的质量(准确率和召回率)对后续知识获取的效率和质量有很大的影响。 因此,它是信息抽取中最基础、最关键的部分。
识别文本中的实体通常可以作为序列标记问题来解决。 传统的实体识别方法以HMM、CRF等统计模型为主。 随着深度学习的兴起数据库技术及应用基础教程,BiLSTM+CRF模型备受青睐。 该模型避免了传统CRF的特征模板构建工作,同时双向LSTM可以更好地利用前后语义信息,可以显着提高识别效果。
关系抽取
关系抽取是从文本中自动抽取实体之间的特定语义关系,以补充图中缺失的关系。 该方法包括人工构建规则和模板来识别实体关系。
实体抽取后,文本语料库得到一系列离散的命名实体。 为了获取语义信息,需要从相关语料库中提取实体之间的关联关系,通过关联关系将实体(概念)联系起来。 形成知识结构网络。
案例:摘自《奶酪鱼原来是奶酪做的》。
其实可以大致归类为一个分类问题。 为什么会这样? 因为最后需要得到的是成分之间的关系,所以训练一个模型进行多分类就OK了。
属性提取
属性抽取是从不同的信息源中收集特定实体的属性信息。 例如,对于一个公众人物,可以从互联网上的公开信息中获取他的昵称、生日、国籍、教育背景等信息。 属性抽取技术可以从各种数据源中收集这些信息,以实现对实体属性的完整描述。
属性抽取可以转化为一个实体抽取+分类的问题,因为实体的属性可以看作是实体与属性值之间的名称关系。
知识融合
知识融合是将多个知识库中的知识进行整合,形成一个知识库的过程。 知识融合要解决的问题是实体对齐。
来自不同数据源的实体对收集知识的侧重点不同,这些知识可能指向现实世界中的同一个对象。 例如,有些知识库可能侧重于描述自身某一方面,有些知识库可能侧重于描述实体和其他实体。 通过实体对齐的知识融合可以对不同知识库中的知识进行补充融合,形成全面、准确、完整的实体描述。
案例:对于历史人物曹操的描述,百度百科、互动百科、维基百科等不同知识库的描述存在一定差异。
实体对齐有两个主要的关键:
实体消歧

在文中,同一个实体可能有不同的写法。 比如“Angelbaby”是杨颖的别名,所以“杨颖”和“Angelbaby”指的是同一个实体。
作用是区分同名实体。 例如,可以通过性别、工作、爱好等其他属性来区分同名的两个人。
照应消歧
引用消歧类似于实体消歧,两者都处理同一个实体。 比如黄晓明案例中的“他”,其实就是指“黄晓明”。 因此,在提及解决方案时要做的就是找出这些代词所指的实体。
知识加工
对于融合后的新知识,在将合格部分加入知识库之前,需要对其进行质量评估(部分需要人工识别),以保证知识库的质量。
本体提取
本体比较抽象,可以简单理解为一系列的概念。 这一系列概念集可以描述特定领域内万物的共同特征,概念之间存在一定的关系,形成层次结构。
例如,足球领域是一个本体。
本体抽取过程包括三个阶段:
例子:
当你拿到“阿里巴巴”、“腾讯”、“手机”这三个实体时,你可能会认为它们之间没有什么区别。
第一步,计算三个实体之间的相似度后,会发现阿里巴巴和腾讯在手机上可能比较相似和不同,但实际上还是没有上下层的概念,还是一判断阿里巴巴和手机不属于一类,不能相提并论。
第二步提取实体-上位词关系完成这样的工作,从而生成第三步的本体。
第三步结束后,很明显“阿里巴巴和腾讯是公司本体下的细分实体,和手机不属于一个范畴”。
知识推理
知识推理是指根据已有的实体关系数据,通过计算机推理在实体之间建立新的关联,从而扩展和丰富知识网络。 知识推理是构建知识图谱的重要手段和关键环节。 从现有知识中发现新知识。
质量评估
量化知识的可信度,保留高置信度的,丢弃低置信度的,有效保证知识的质量。
参考
 上一篇
上一篇 








