

建站需求表-sitelusongsong.com seo建站需求
这是学习笔记的第2328篇文章
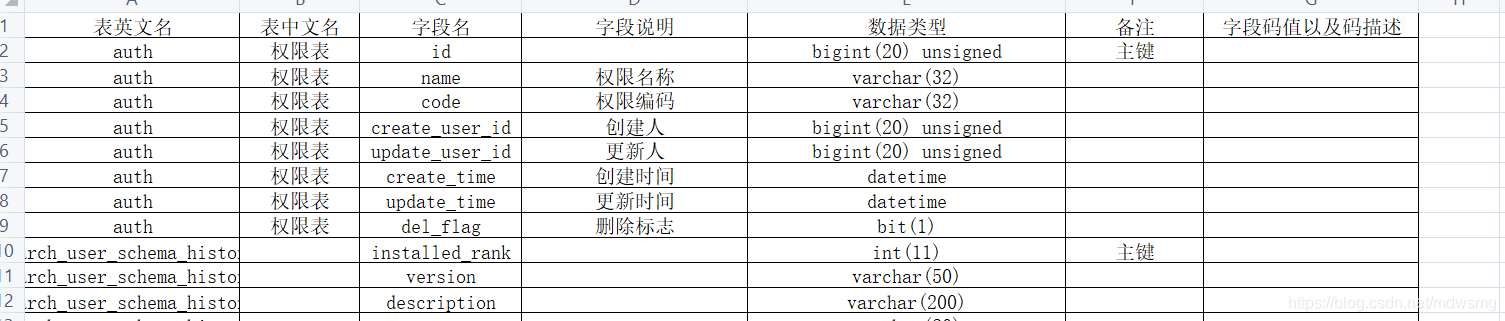
昨天收到一个业务同学的需求邮件,一般有些复杂的需求业务同学会发邮件告知我们,需要我们评估之后再做交付,我看了邮件之后,发现这个需求好像有点别扭,大体的意思是在中间件的环境中创建一张表,表结构如下:
CREATE TABLE `app_loading_info` (`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增ID',`pid` bigint(20) NOT NULL DEFAULT '0' COMMENT ,`appid` int(11) NOT NULL DEFAULT '0' COMMENT 'APPID',`username` varchar(64) NOT NULL DEFAULT '' COMMENT '姓名',`card` varchar(20) NOT NULL DEFAULT '' ,`ai` varchar(40) NOT NULL DEFAULT '' ,`state` int(11) NOT NULL DEFAULT '0' ,`ctime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',`mtime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',PRIMARY KEY (`id`),KEY `idx_pid` (`pid`),KEY `idx_state` (`state`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
按照ID分片,基本逻辑如下:

每天会去筛选为完成处理的用户数据,重新处理,处理完成后会去修改用户的一个标志位,主要有几个步骤:
1)根据state状态提取state=0的数据(未完成处理数据)
2)程序中按照id为区间分批提取
3)提取完成后修改state为state=1,根据pid,state组合
看了这个初步的设计之后,我总是感觉哪里不对,于是找业务同学面对面沟通。
首先对于这个表的定义上,业务同学说是归属于状态表,也就意味着表中的每一个用户都有唯一的状态值对应,这个表中存储的数据量会越来越大。
其次,按照state状态字段去提取未完成处理的数据,这个目标环境是一套集群环境,集群中是按照id进行分片,但是查询条件按照state是有潜在问题的。
比如业务层对于自增id的使用,在分片环境中可能是不唯一的,如上图所示,可能id=1最多会存在N条同样的数据(N为分片数),所以从业务需求上是不太能满足的。
另外根据state=0去查询数据,这个查询的复杂度较高,也就意味着state=0需要遍历所有的分片,每个分片中会通过state=0的索引条件过滤数据最后汇总起来,从使用上来说,这也是分库分表的一个潜在影响建站需求表,不是很建议这种使用方式。
还有字段id的设计,按照状态表的使用方式,也是不合理的,在一些特殊的场景中我们会采用id+其他业务属性字段组合主键,在这里这种场景显然不是。
如果去掉id字段采用主键的模式,好像就违背了业务初衷根据id进行区间提取的方式,细细品来这个需求是矛盾的。

如果按照最勉强的方式,建议是指定时间范围内处理,比如8点到9点之间处理,这个之外的时间范围就不要做类似心跳或者服务检测的处理了,对于业务侧来说,还是能够基本接受的,但是无论如何这不是一种最优解,而且对于索引的使用实在有悖于中间件服务使用的初衷。
经过进一步的沟通,我们再次挖掘需求,对于里面的表数据是如何处理的,业务同学说其实表中的数据如果时间长了之后是需要考虑数据清理的,所以按照这种模式,这个需求的就基本清晰了,和初始需求有比较大的差异。
到了这里需求的方向其实就有了大的转折,这个表按照目前的需求其实使用日志表的模式要更好一些,比如表中的数据是按照如下的列表情况存储,以日期表为维度进行存储。
如果需要按照T+1的模式去处理未完成的数据建站需求表,整个复杂度只针对某一天的表执行索引扫描,不会对其他的表产生关联影响,而如果按照日期为单表存储,整个事情的自由度就更大了,按照state或者是pid的维度进行查询,效果都是可以接受的。
所以最后经过讨论和评估,其实没有必要在中间件环境中进行该类业务的处理,相比而言,性价比也不高。而基于中间件的服务承接的是偏核心的业务,对于性能和负载的影响较为敏感,如果稀里糊涂就执行了,其实后面会带来一些其他的隐患。
通过这样一个看起来简单的需求的沟通和挖掘,最后产生了不同的解决方案,对于业务侧来说还是比较满意的,至少能够超出他们的基本需求期望实现,而且很多细节的工作也不需要更多的人工参与和后期讨论,大大减少了沟通的边际成本。
以上仅是一个需求的讨论过程,不代表方案是最优的,仅供参考。
各大平台都可以找到我
近期热文:
 上一篇
上一篇 








