cad软件开发基础 实验指导答案-6组机器学习实验,让你的机器效果更好
本文将带大家进行6组机器学习实验。
如果觉得一个实验过大,建议观看此文的老师根据教学进度将实验拆开,每一个小的步骤设计成一个实验。如实验项目4,可以在讲教材《机器学习(Python+sklearn+TensorFlow 2.0)-微课视频版》第三章回归时cad软件开发基础 实验指导答案,做第1步(样本数据分析和处理)和第2步(回归算法建模及分析)实验;在讲教材第五章特征工程时,做第3步(超参数调优)和第4步(特征选择)实验;在讲教材第七章神经网络时,做第5步(神经网络模型)实验。这样一件事件前后连贯起来做,实验效果可能会更好。
01
实验教学目的和要求
1) 实验目的
本课程实验旨在加深学生对于机器学习算法的理解,掌握科学的实验方法,培养初步应用能力,为今后从事相关工作打下坚实的基础。该实验内容采用循序渐进的方式,从环境搭建入手,逐步在降维、聚类、回归、分类、标注等机器学习的主要任务上展开实验。实验明确任务要求,学生自己查阅资料、设计方案和动手实践,并进行结果纪录和分析,充分发挥学生的创造性和主动性。
2) 实验要求:
理解机器学习常用算法,能够使用python语言、sklearn扩展库、TensorFlow2框架等进行初步算法应用。
02
实验环境要求
本课程实验面向广大初学者,旨在理解原理、掌握初步应用,只要求CPU处理器作为基本实验硬件。
本课程实验可基于windows平台完成。Python管理环境采用Anaconda。主要软件和工具的版本如下:
Python:3.7.5
Sklearn:0.23.2
Tensorflow:2.0.0
03
实验项目名称及目的要求
实验项目1 环境搭建
1、实验目的
1)掌握Anaconda的安装、配置方法
2)掌握sklearn和TensorFlow2的安装方法
3)学习Python和TensorFlow2的初步应用
2、实验内容
1)自行上网查阅相关资料,学习Anaconda的下载与安装,学习图形化管理与命令行管理的概念,学习Anaconda里环境的概念,学习Anaconda下载源的更换,完成下载Anaconda3-2019.10-Windows-x86_64.exe文件并安装,完成更换清华大学下载源,完成新建环境“ml”。
2)自行上网查阅相关资料,学习在Anaconda下安装库,完成在ml环境中安装Python(3.7.5)、Sklearn(0.23.2)、Tensorflow(2.0.0)及spyder和Jupyter Notebook等。
3)用Python语言实现水藻生长的迭代法应用
4)初步体验TensorFlow中算子的操作
3、实验原理
1)迭代法应用
迭代法是一种步步为营,逐次推进,逐步接近的现代计算机求解问题的基本形式。迭代法的核心是建立迭代关系式。
假设在空池塘中放入一颗水藻,该类水藻会每周长出三颗新的水藻,问十周后,池塘中有多少颗水藻?
第1周的水藻数量:1;
第2周的水藻数量:1+1 x 3;
第3周的水藻数量:1+1 x 3+(1+1 x 3)x 3;
…
可以归纳出从当前周水藻数量到下一周水藻数量的迭代关系式。设上周水藻数量为x,从上周到本周水藻将增加的数量为y,本周的水藻数量为x',那么在一次迭代中:
y ← 3x
x’ ←x+y
迭代开始时,水藻的数量为1,为迭代法的初始条件。
迭代次数为9(不包括第一周),为迭代过程的控制条件。
用Python语言编程实现上述问题的求解。
2)TensorFlow2中算子的操作
TensorFlow2深度学习框架中,张量(Tensor)是基本的数据结构,算子是施加在张量上的各种操作,它们是理解深度学习框架最基本的概念。
查阅资料,学习TensorFlow2中张量的概念及初始化方法,并探索对张量进行基本算子操作。
4、实验步骤
1)环境安装与配置

● 下载Anaconda3-2019.10-Windows-x86_64.exe文件并安装
● 更换清华大学下载源
● 新建环境“ml”
● 安装Python(3.7.5)、Sklearn(0.23.2)、Tensorflow(2.0.0)及spyder和Jupyter Notebook等
2)迭代法应用
● 分析实验要求
● 用循环语句实现迭代过程
● 记录并分析实验结果
3)探索对张量进行基本算子操作
● 分析实验要求
● 生成一个张量
● 对张量进行幂运算等算子操作
● 记录并分析实验结果
实验项目2 PCA降维
1、实验目的
1)理解PCA算法的原理
2)掌握sklearn中PCA算法的应用方法
2、实验内容
1)应用PCA算法对平面上指定的点进行降维,对照PCA原理分析结果
2)生成高维数据,将其降维到二维cad软件开发基础 实验指导答案,并在平面上画出
3、实验原理
1)PCA降维过程印证
PCA主成分分析是找出主要成分来代替原来数据。
在二维平面上有x1,x2,x3,x4四个点,坐标分别是(4,2)、(0,2)、(-2,0)和(-2,-4),它们满足所谓中心化要求,即
对于不满足中心化要求的点,可通过减所有点的均值来满足该要求。
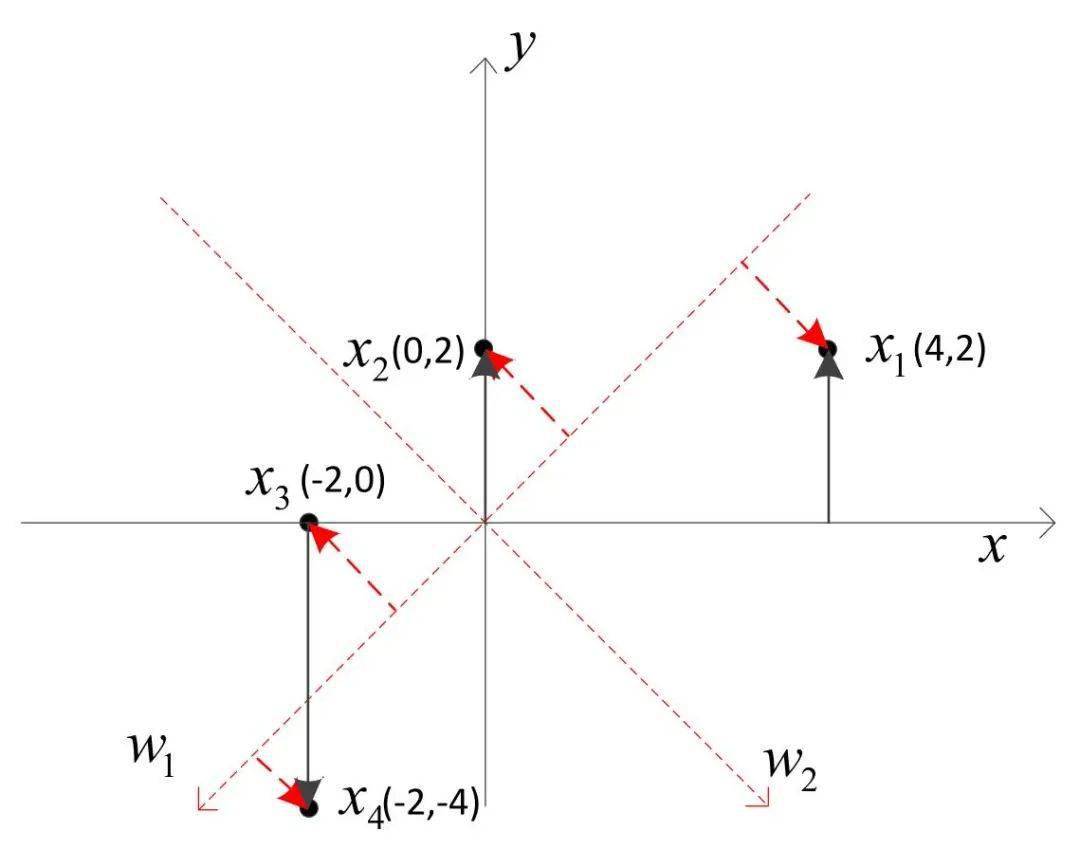
要将这四个点从二维降为一维,PCA算法是去掉其中一维坐标(设为y轴),只保留一维坐标。但并不是直接去掉一维坐标,而是同步旋转x和y轴,使得去掉y轴上的坐标带来的损失函数最小。
在sklearn扩展库的decomposition模块中实现了PCA算法,用该算法来印证上述过程。
在序列化PCA对象时,如果将n_components参数设为2,则只旋转坐标轴不降维,此时可以观察旋转后的坐标轴。
如果n_components参数设为1,可观察保留的坐标轴,再对比一下未降维时的坐标轴,分析一下保留的结果。
2)PCA高维数据降维应用
通过对高维进行降维操作,理解PCA各参数的含义,学习PCA的应用,图示对比分析实验结果。
4、实验步骤
1)PCA降维过程印证
● 分析实验要求
● n_components参数设为2应用PCA算法对指定数据进行分析,观测坐标轴的旋转变化
● n_components参数设为1应用PCA算法对指定数据进行分析,观测坐标轴减少变化
● 记录并分析实验结果
2)PCA高维数据降维应用
● 分析实验要求
● 用datasets模块中的Make_blobs函数产生各向同性的高斯分布的三维样本数据
● 画出样本数据在三维平面上的投影
● 用PCA进行降到二维,并画出降维后的结果
● 记录并分析实验结果
实验项目3 聚类算法应用及比较

1、实验目的
1)学习kmeans、DBSCAN和GaussianMixture三种算法的应用
2)学习用SC、DBI、CH和ZQ四个聚类评价指标来比较分析实验结果
2、实验内容
1)掌握复杂样本数据生成方法
2)理解kmeans、DBSCAN和GaussianMixture算法的原理,并掌握其应用方法
3)理解SC、DBI、CH和ZQ四个聚类评价指标,并掌握其应用分析方法
3、实验原理
1)聚类算法
见书上kmeans、DBSCAN和GaussianMixture三种算法相关内容。
2)聚类标价指标
SC、DBI、CH见书上相关内容。
ZQ指标:
1.定义众距离 z 来衡量簇内密集程度。记 MinPts_distance(x m ) 为样本点 x m 到它的第 MinPts 近邻居样本点的距离,则簇 C i 的众距离 Z i 为:
MinPts可以根据样本密集程度取1、2、…等值。
2.定义群距离 Q 来衡量簇的间隔程度。
两个簇的群距离 Q 是他们的样本点之间的距离的最小值:
用所有簇的众距离的均值除以所有簇间群距离的均值的结果作为评价聚类效果的指标,称为ZQ系数:
ZQ系数小表示簇内密集、簇间疏散。
实现ZQ系数的代码如下所示,其中,MinPts取值1。代码中的向量平方、开方、求和、求最小值、求均值等计算采用numpy模块中的square、sqrt、sum、min、mean等函数来完成。第32行和第39行的np.inf表示无穷大值。
importnumpy asnp
defZQ_score(X, labels):
'''
计算ZQ系数。
para X:数组形式的样本点集,每一行是一个样本点。
para labels:数组形式的测试标签集。
retrurn: ZQ系数。
'''
n_samples = len(X) # 标本总数
label = list(set(labels)) # 标签列表
n_labels = len(label) # 标签数
### 把样本及标签分簇存放
X_i = []
y_i = []
fori inlabel:
X_i.append([])
y_i.append([])
fori inrange(n_samples):
j = label.index(labels[i]) # 该样本在label标签列表中的下标
X_i[j].append(X[i])
y_i[j].append(labels[i])
### 计算簇内众Z距离
Z_dist = np.zeros(shape = (n_labels)) # 存放每个簇的Z距离
fori inrange(n_labels):
n_cluster = len(X_i[i])
sample_z_dist = [] # 用来记录簇内每个样本的最近邻距离
forj inrange(n_cluster):
min_dist = np.inf
fork inrange(n_cluster):
ifj == k:
continue
dist = np.sqrt(np.sum(np.square(X_i[i][j] - X_i[i][k]))) # 两个样本间的欧氏距离
ifdist < min_dist:
min_dist = dist
ifmin_dist == np.inf:
sample_z_dist.append( 0) # 簇内只有一个元素时
else:
sample_z_dist.append(min_dist)
Z_dist[i] = np.mean(sample_z_dist)
### 计算簇间群Q距离
Q_dist = np.zeros(shape = (n_labels, n_labels)) # 二维数组,用来存放簇之间的Q距离
fori inrange(n_labels):
forj inrange(n_labels):
ifi == j:
continue
i2j_min_dist = [] # 用来记录第i个簇内样本点到第j个簇的最小距离
forsample1 inX_i[i]:
min_dist = np.inf
forsample2 inX_i[j]:
dist = np.sqrt(np.sum(np.square(sample1 - sample2))) # 两个样本间的欧氏距离
ifdist < min_dist:
min_dist = dist
ifmin_dist < np.inf:
i2j_min_dist.append(min_dist)
Q_dist[i,j] = np.min(i2j_min_dist) # 群距离是样本点之间距离的最小值
# Q_dist[i,j] = np.min(i2j_min_dist) # 群距离用点到簇的距离来定义
returnnp.mean(Z_dist) / ( np.sum(Q_dist) / ( n_labels * (n_labels -1) ) )
4、实验步骤
1)生成样本数据
● 分析实验要求
● 学习datasets模块中make_circles、make_blobs、make_moons、make_gaussian_quantiles函数
● 生成实验样本
1)分簇并比较
● 应用kmeans、DBSCAN和GaussianMixture算法对样本进行分簇
● 用SC、DBI、CH和ZQ四个聚类评价指标进行比较分析
● 记录并分析实验结果
实验项目4 房价回归
1、实验目的
1)强化对回归问题的理解
2)掌握回归算法的应用

3)掌握搭建多层全连接层神经网络
2、实验内容
1)样本数据分析与处理
2)回归算法建模
3)全连接层神经网络搭建回归模型
3、实验原理
1)样本数据分析与处理
下载后,对样本数据进行分析。该实验是依据房屋的属性信息,包括房屋的卧室数量,卫生间数量,房屋的大小,房屋地下室的大小,房屋的外观,房屋的评分,房屋的修建时间,房屋的翻修时间,房屋的位置信息等,对房屋的价格进行预测。
2)回归算法建模及分析
运用各类回归算法对数据进行建模,选择最好的模型。
3)特征工程
运用sklearn提供的工具对特征进行相关系数分析,对模型参数进行网格调优。
4)全连接层神经网络搭建回归模型
在TensorFlow2框架下搭建全连接层神经网络模型用于房价回归预测。
4、实验步骤
1)样本数据分析与处理
● 分析实验要求
● 下载实验数据
● 初步分析数据
● 划分训练集和验证集
● 对特征进行归一化
2)回归算法建模及分析
● 学习回归算法的应用方法
● 对样本数据进行建模并验证
3)超参数调优
● 网格搜索超参数调优
4)特征选择
● 用相关系数来观察特征之间以及特征和标签之间的相关性
● 用散点图观察特征与标签之间的相关性
● 用模型尝试去掉特征
5)神经网络模型
● 搭建神经网络模型
● 训练并应用神经网络模型
● 记录并分析实验结果
实验项目5 电信用户流失分类
1、实验目的
1)强化对分类问题的理解
2)学习分类算法的建模方法
2、实验内容
1)样本数据分析
2)用户画像
3)分类算法建模及分析
3、实验原理
1)样本数据分析
该实例数据同样来自kaggle,它的每一条数据为一个用户的信息,共有21个有效字段,其中,最后一个字段Churn标志该用户是否流失。运用numpy和pandas等工具对数据进行初步分析,尽量理解特征之间的关系。

2)用户画像
运用各类分析工具对流失用户和非流失用户进行特征分析,说明流失用户和非流失用户的特点。
3)分类算法建模及分析
运用各类分类算法对数据进行建模,包括多项式朴素贝叶斯模型、高斯朴素贝叶斯模型、逻辑回归模型、决策树模型、随机森林模型、装袋决策树模型、极端随机树模型、梯度提升树模型和多层全连接层神经网络模型等。并用准确度指标和AUC指标对它们的预测效果进行评估。
4、实验步骤
1)样本数据分析
● 分析实验要求
● 分析实验数据的完整性、重复性
● 分析实验数据各特征之间的关联关系
2)用户画像
● 分析各特征与用户是否流失的关系
● 综合上述关系,给出流失用户和非流失用户的特点
3)分类算法建模及分析
● 学习分类算法的应用方法
● 对样本数据进行建模
● 用准确度指标和AUC指标评估模型
● 记录并分析实验结果
实验项目6 中文分词
1、实验目的
1)强化对标注问题的理解
2)强化对隐马尔可夫模型、条件随机场模型和循环神经网络的理解,掌握其应用方法
3)理解中文分词
2、实验内容
1)实验样本预处理
2)隐马模型建模
3)条件随机场工具应用
4)循环神经网络建模
3、实验原理
1)中文分词
中文分词是将中文句子分解成有独立含义的字或词,如“我爱自然语言处理”可分解成“我 爱 自然 语言 处理”或“我 爱 自然语言 处理”。
当前,标注方法是比较成功的分词方法。标注分词方法给句子中的每个字标记一个能区分词的标签,如SBME四标注法中,“S”表示是该字是单字,“B”表示该字是一个词的首字,“M”表示该字是一个词的中间字,“E”表示该字是一个词的结尾字。“我爱自然语言处理”一句两种分词的标注如下图所示。
2)隐马尔可夫模型、条件随机场和循环神经网络
原理见书上内容。
4、实验步骤
中文分词
● 分析实验要求
● 打开实验语料文件traindata.txt,对其进行预处理
● 按隐马模型要求统计各项数据,建立隐马模型,对测试语句进行分词
● 用CRF++工具建立模型,对测试语句进行分词
● 在TensorFlow2框架下,搭建循环神经网络,建立模型,对测试语句进行分词
03
实验参考及代码下载

04
参考教材
《机器学习(Python+sklearn+TensorFlow 2.0)-微课视频版》
ISBN:978-7-302-55928-3
 上一篇
上一篇