

软件测试发展怎么样-测试直播网络延时测试软件
随着人工智能的发展与应用,AI测试逐渐进入到我们的视野,传统的功能测试策略对于算法测试而言,心有余而力不足,难以满足对人工智能 (AI) 的质量保障。
结合在人脸检测、检索算法上的测试探索、实践的过程,本文将从以下几个方面介绍人工智能 (AI) 算法测试策略。
我们将算法测试测试流程中的几个核心环节提炼如上几点,也就组成了我们算法测试的测试策略,在此,抛砖引玉的分享一下。
算法测试集数据准备
测试集的准备对于整体算法测试而言非常重要,一般测试集准备过程中需考虑以下几点:
测试集的覆盖度
如果,测试集准备只是随机的选取测试数据,容易造成测试结果的失真,降低算法模型评估结果的可靠性。
好比我们的功能测试,根据功能测试设计,构造对应的数据进行测试覆盖。算法测试亦然,以人脸检测算法而言,除了考虑选取正样本、负样本外,还需要考虑正样本中人脸特征的覆盖,如人脸占比、模糊度、光照、姿态(角度)、完整性(遮挡)等特征。

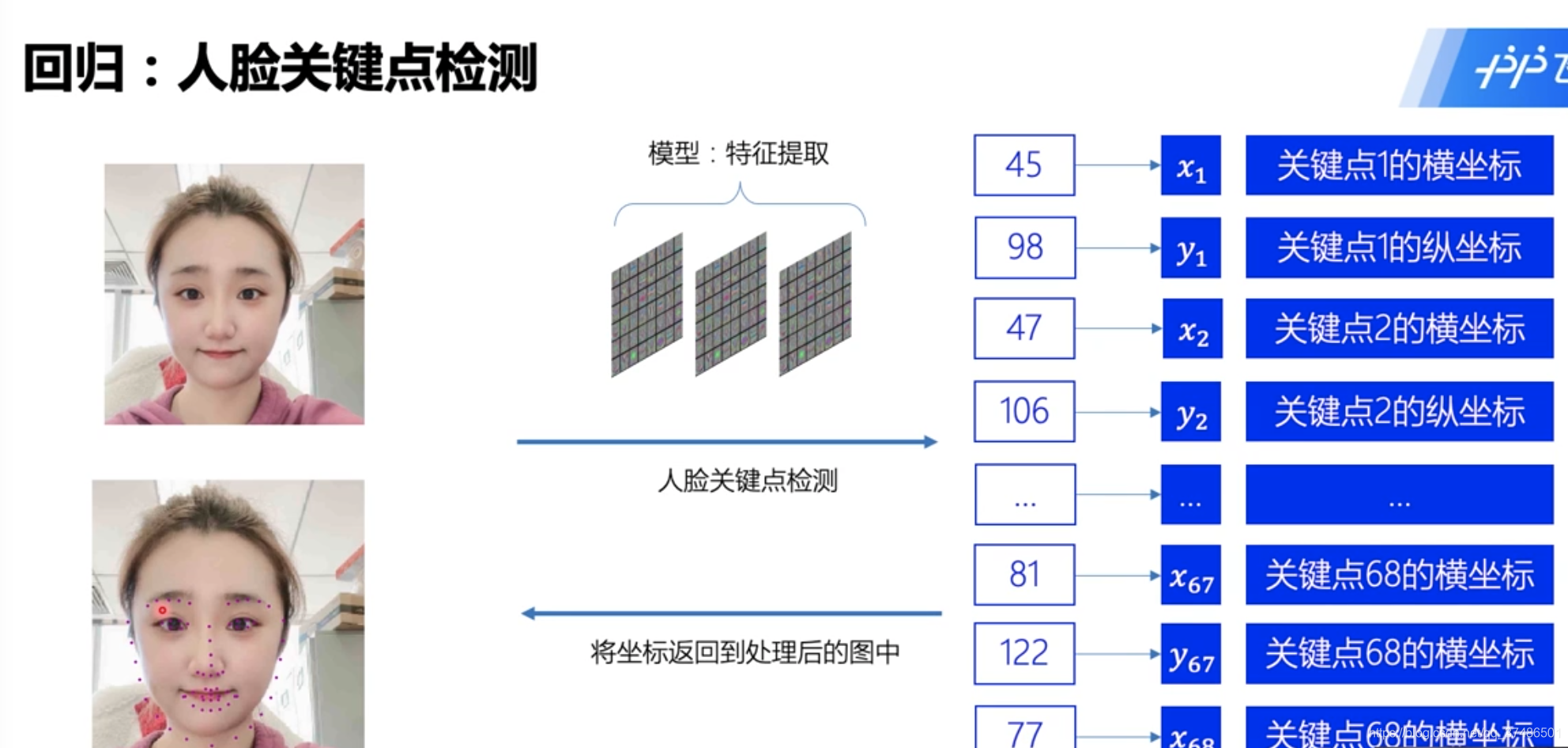
选择好对应的测试数据后,后来后期的指标计算、结果分析,还需对数据进行标注,标注对应的特征,以人脸检测为例,使用工具对人脸图标进行人脸坐标框图,并将对应特征进行标注记录及存储,如下图。
另外,除了数据特征的覆盖,也需要考虑数据来源的覆盖,结合实际应用环境、场景的数据进行数据模拟、准备。比如公共场所摄像头下的人脸检索,图片一般比较模糊、图片光照强度不一,因此准备数据时,也需要根据此场景,模拟数据。一般来讲,最好将真实生产环境数据作为测试数据,并从其中按照数据特征分布选取测试数据。
此外,关于测试数据的数量,一般来讲测试数据量越多越能客观的反映算法的真实效果,但出于测试成本的考虑,不能穷其尽,一般以真实生产环境为参考,选取20%,如果生产环境数据量巨大,则选取1%~2%,或者更小。由于我们的生产环境数据量巨大,考虑到测试成本,我们选取了2W左右的图片进行测试。
测试集的独立性
测试集的独立性主要考虑测试数据集相互干扰导致测试结果的失真风险。
我们以人脸检索为例,我们准备200组人脸测试数据,每组为同一个人不同时期或角度的10张人脸照片,对人脸检索算法模型指标进行计算时,如计算TOP10的精确率,此时若在数据库中,存在以上200组人的其他照片时,便会对指标计算结果造成影响,比如我们200组人脸中包含Jack,但数据库中除了Jack的10张,还存在其他的8张Jack的照片。若算法微服务接口返回的TOP10图片中有我们测试集中的Jack图片6张,非测试集但在数据库中的其他Jack照片2张,还有2张非Jack的照片,测试的精确率该如何计算,按照我们的测试集(已标注)来看,精确率为60%,但实际精确率为80%,造成了精确率指标计算结果的失真。

因此,我们在测试集数据准备时,需考虑数据干扰,测试准备阶段对数据库的其他测试数据进行评估,比如从200组人脸测试数据组,进行预测试,对相似度非常高的数据进行研判,判断是否为同一人,若是则删除该照片或者不将该人从200组测试集中剔除。
测试集的准确性
数据集的准确性比较好理解,一般指的是数据标注的准确性,比如Jack的照片不应标注为Tom,照片模糊的特征不应标注为清晰。如果数据标注错误,那么直接影响了算法模型指标计算的结果。
对于测试集的准备,为了提高测试集准备效率及复用性,我们尝试搭建了算法数仓平台,实现数据(图片)的在线标注、存储等功能,作为算法测试数据的同一获取入口。
算法功能测试
以我现在接触的人工智能系统而言,将算法以微服务接口的形式对外提供服务,类似于百度AI开放平台。

因此需要对算法微服务接口进行功能性验证,比如结合应用场景从功能性、可靠性、可维护性角度对必填、非必填、参数组合验证等进行正向、异向的测试覆盖。此处不多做介绍,同普通的API接口测试策略一致。
算法性能测试
微服务接口的性能测试大家也比较了解,对于算法微服务同样需要进行性能测试,如基准测试、性能测试(验证是否符合性能指标)、长短稳定性能测试,都是算法微服务每个版本中需要测试的内容,同时产出版本间的性能横向对比,感知性能变化。常关注的指标有平均响应时间、95%响应时间、TPS,同时关注GPU、内存等系统资源的使用情况。
一般使用Jmeter进行接口性能测试。不过,我们在实际应用中为了将算法微服务接口的功能测试、性能测试融合到一起,以降低自动化测试开发、使用、学习成本,提高可持续性,我们基于关键字驱动、数据驱动的测试思想,利用Python Request、Locust模块分别实现了功能、性能自定义关键字开发。每轮测试执行完算法微服务功能自动化测试,若功能执行通过,则自动拉起对应不同执行策略的性能测试用例,每次测试执行结果都进行存储至数据库中,以便输出该算法微服务接口的不同版本性能各项指标的比较结果。
算法模型评估指标
首先,不同类型算法的其关注的算法模型评估指标不同。
比如人脸检测算法常以精确率、召回率、准确率、错报率等评估指标;人脸检索算法常以TOPN的精确率、召回率、前N张连续准确率。
其次,相同类型算法在不同应用场景其关注的算法模型评估指标也存在差异。
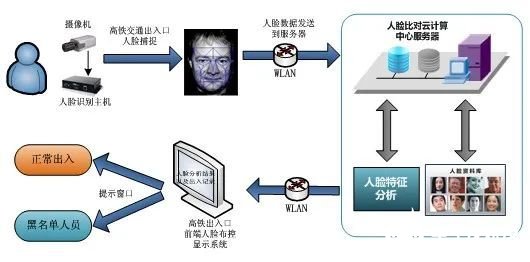
比如人脸检索在应用在高铁站的人脸比对(重点人员检索)的场景中,不太关注召回率,但对精确率要求很多,避免抓错人,造成公共场所的秩序混乱。但在海量人脸检索的应用场景中,愿意牺牲部分精确率来提高召回率,因此在该场景中不能盲目的追求精准率。
除了上述算法模型评估指标,我们还常用ROC、PR曲线来衡量算法模型效果的好坏。
我们在算法微服务功能、性能测试中介绍到,使用了基于关键字驱动、数据驱动的测试思想,利用Python Request、Locust模块分别实现功能、性能自定义关键字开发。考虑到测试技术栈的统一以及可复用性软件测试发展怎么样,我们基于上述设计,实现了算法模型评估指标的自定义关键字开发,每次运行输出相同测试集下的不同版本模型评估指标的横向比较。
当然除了不同版本的比较模型评估指标的比较,如果条件允许软件测试发展怎么样,我们还需要进行一定的竞品比较,比较与市场上相同类似的算法效果的差异,取长补短。
算法指标结果分析
我们对算法模型指标评估之后,除了感知算法模型评估指标在不同版本的差异,还希望进一步的进行分析,已得到具体算法模型的优化的优化方向,这时候就需要结合数据的标注信息进行深度的分析,挖掘算法优劣是否哪些数据特征的影响,影响程度如何。比如通过数据特征组合或者控制部分特征一致等方式,看其他特征对算法效果的影响程度等等。
这时候我们一般通过开发一些脚本实现我们的分析过程,根据算法微服务接口的响应体以及数据准备阶段所标注的数据特征,进行分析脚本的开发。
另外指标结果的进一步分析,也要结合算法设计,比如人脸检索算法,每张图片的检索流程为“输入图片的人脸检测“ -> “输入图片的人脸特征提取“ -> “相似特征检索“,通过此查询流程不难看出人脸检索的整体精确率受上述三个环节的影响,因此基于指标结果的深度分析也需要从这三个层次入手。
算法测试报告
一般算法测试报告由以下几个要素组成:
由于算法微服务测试的复杂度相对普通服务接口较高,在报告注意简明扼要。
 上一篇
上一篇 








