

python 协同过滤算法-基于用户的协同过滤推荐算法
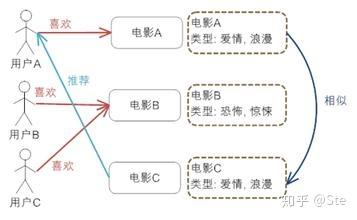
基于内容的推荐
比如上图中,用户A喜欢电影A,而电影A属于“爱情”、“言情”类型,则继续推荐该类型的其他电影,比如电影C。就像我说我爱千与千寻,你可能会认为我也爱幽灵公主(我都爱 hhh)。
这些步骤与基于人口统计的步骤类似,不同之处在于更改用户的用户画像以构建项目的特征集:
构建物品特征集(特征包括关键字、标签等); 根据物品特征集计算物品相似度; 根据用户过去的偏好找到相似的物品进行推荐。缺点:3.基于协同过滤的推荐
协同过滤推荐是推荐算法中应用最广泛的算法。 它的基本思想是汲取集体智慧,不需要对物品或用户进行特殊处理,只需要通过用户在物品之间建立联系。 比如能成为朋友的大部分都是志同道合的python 协同过滤算法,所以当朋友说“想见你”好,那我就大概率点赞(User-based CF)。 或者如果我很喜欢《千与千寻》,那么当我看到很多看过《千与千寻》的人对《幽灵公主》评价很高的时候,我喜欢《幽灵公主》的可能性也很高(Item-based CF).
注意:这与基于人口统计和基于内容不同。 基于人口统计,用户自身肖像特征的相似性决定相似用户集,而User-based CF根据用户对物品的偏好相似性决定相似用户集。 Content-based recommendation是根据item本身内容的相似度来确定相似的item sets,而Item-based CF类似于User-based CF,根据不同用户对不同item的偏好来计算item之间的关系,从而得到相似的项目集。
下面具体分析,基于协同过滤的推荐算法分为两类:
基于内存的协同过滤算法、基于模型的协同过滤算法
其中,基于记忆的协同过滤包括基于用户的协同过滤和基于物品的协同过滤。
1)基于用户的协同过滤(User-based CF)
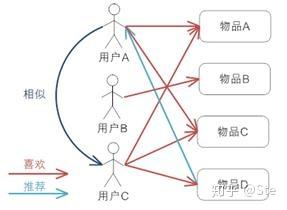
基于用户的CF
如上图所示:用户ABC中,用户A和C的偏好最相似(都喜欢物品A和C),那么用户C喜欢但用户A没见过的物品D会被推荐给用户A。
具体步骤:
构建用户-项目评分矩阵,计算用户的相似度; 使用阈值法或KNN法生成一组相邻用户; 根据相邻用户集合中的item集合(去掉待推荐用户看过的item)python 协同过滤算法,按照加权法得到被推荐用户的推荐item集合topN。 阈值法:即通过设置相似度阈值\varepsilon来确定最近邻用户。 如果用户 v 和用户 u 的相似度超过 \varepsilon,则 v 被选为与 u 相似的用户。 特点:该方法得到的最近邻用户个数不是常数。
KNN方法:取与用户v相似度最高的k个用户作为当前最近邻用户。 特点:该方法最终得到的最近邻用户数量是一定的。
加权方法:对用户u打分的item进行加权求和,权重为每个item与item i的相似度,然后对所有item的相似度求和求平均,计算出用户u对item i的打分,即公式如下:
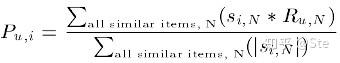
加权方法,其中s_{i,N}为item i与每个item的相似度,R_{u,N}为用户u对每个item的评分。
基于用户的 CF 特性:
推荐理由:难以为用户提供有说服力的推荐解释。
2)基于项目的协同过滤(Item-based CF)
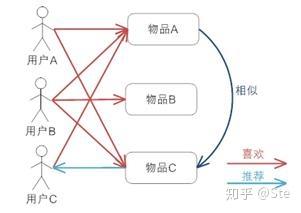
基于项目的CF
如上图所示:用户A和C都喜欢物品A,用户A也喜欢物品C,物品C与物品A相似,所以物品C会被推荐给用户A。
具体步骤:
构建用户-物品-用户评分矩阵,计算物品的相似度; 通过阈值法或KNN法生成邻居项集; 根据neighbor item set'(去掉用户看过的item),根据加权法得到推荐用户推荐的item set topN。
基于项目的 CF 特性:
推荐理由:利用用户的历史行为,给用户一个推荐解释,可以让用户更有说服力。
总的来说,基于记忆的协同过滤算法的优缺点:
缺点:
3)基于模型的协同过滤(Model-based CF)
基于模型的协同过滤推荐是基于样本用户偏好信息,训练推荐模型,然后根据实时用户偏好信息预测和计算推荐。
常用的训练模型有:pLSA、LDA、clustering、SVD、Matrix Factorization、LR、GBDT等。这种方法的训练过程比较长,但是训练完成后推荐过程比较快速准确。 因此更适合新闻、广告等实时性高的业务。 当然,如果要让这个算法达到更好的效果,还需要人工干预,反复组合过滤属性,也就是我们常说的特征工程。 由于消息的时效性,系统也需要反复更新在线数学模型以适应变化。
2. 基于混合的推荐
上面推荐的几种算法或多或少都有各自的优缺点,所以如果将多种方法混合在一起,可能会达到更好的推荐效果。 关于如何组合各种推荐机制,这里介绍一些比较流行的组合方式。
Weighted Hybridization:使用一个线性公式,按照一定的权重组合几个不同的推荐。 具体的权重值需要在测试数据集上反复测试才能达到最好的推荐效果。 Switching Hybridization:针对不同的情况(数据量、系统运行状态、用户和物品数量等),推荐策略可能会有很大的不同,所以switching hybridization的方法就是让在不同的情况下,选择最合适的推荐机制来计算推荐度。 Mixed Hybridization:采用多种推荐机制,向不同地区的用户展示不同的推荐结果。 事实上,亚马逊、当当网等很多电子商务网站都采用这种方式,用户可以获得全面的推荐,更容易找到自己想要的东西。 Meta-Level Hybridization:采用多种推荐机制,将一种推荐机制的结果作为另一种推荐机制的输入,从而综合各推荐机制的优缺点,得到更精准的推荐。 总结:
这里只是简单介绍几种经典的推荐算法。 常用的相似度计算方法和具体例子可以参考我放的第二个和第三个链接。 代码实现方面,大家可以上网或者GitHub搜索一下,自己运行。 笔者在整理这篇文章的过程中,发现自己之前的理解有些模糊,光看是没有用的,还是得实践一下!
去!去!去!
参考链接:
参考书目:
《推荐系统实战》项目上线
 上一篇
上一篇 








