

java实现协同过滤-协同过滤算法java实现
开谈不说大数据,读尽诗书也枉然。在大数据、云计算、移动互联网、物联网、人工智能大行其道的当下,街头巷尾听到最多的名词就是大数据了,但你真的理解大数据吗?大数据到底是什么?如果此时你心里只有“量大”这一个答案,那请耐心读完本文,我将用一张技能图谱、两个基础条件、三个工作方向、四个基本特点、五个里程碑、六个工作环节以及大数据时代需要具备的思维方式,让你能在别人面前高逼格的谈大数据
大数据技能图谱
两个基础条件
从网购到娱乐,从推荐系统到短视频,大数据系统在方方面面影响着我们的生活,大数据系统能够得到广泛应用,主要得益于以下两方面的进展。
(1)底层硬件的支撑
在这方面我想80/90后会有特别深刻的感受,对比一下十年前我们的电脑和手机性能【磁盘大小、内存、CPU】以及网络带宽和流量等,存储设备、计算性能、网络带宽,这些年都在快速地发展,这些都为大数据的运算处理以及大数据集群的构建提供了有力的硬件支撑
(2)数据生产方式
随着网络、手机、电脑等设备的普及,越来越多的人成了内容的生产者,也就是我们现在所说的自媒体。微信公众号、今日头条,以及今天盛极一时的抖音、快手,都是依赖大家自发地去制作和上传内容,在这些平台上,每天发布的内容数量要以千万甚至亿级来进行计算。除了这些主观的数据产生形式,我们的生活中还存在许多被动的数据产生形式:如交通路口的摄像头、各类人脸识别、打卡系统等这些数据的生产是源源不断的,所以java实现协同过滤,每天都会有大量的数据产生并且被存储下来。
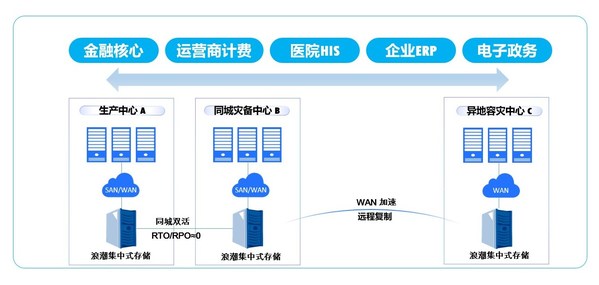
三个就业方向
(1)大数据架构方向
大数据架构方向涉及偏向大数据底层与大数据工具的一些工作。做这一方向的工作更注重的是:
Hadoop、Spark、Flink 等大数据框架的实现原理、部署、调优和稳定性问题;
在架构整合、数据流转和数据存储方面有比较深入的理解,能够流畅地落地应用;
熟知各种相关工具中该如何搭配组合才能够获取更高的效率,更加符合公司整体的业务场景。
从事这一方向的工作,需要具备以下技术。
大数据框架:Hadoop、Spark、Flink、高可用、高并发、并行计算等。
数据存储:Hive、HDFS、Cassandra、ClickHouse、Redis、MySQL、MongoDB 等。
数据流转:Kafka、RocketMQ、Flume 等。
(2)大数据分析方向
这里所说的大数据分析方向是一个广义上的大数据分析,在这个方向上,包含了各类算法工程师和数据分析师,一方面要熟练掌握本公司业务,一方面又具备良好的数学功底,能够使用数据有针对性的建设数据指标,对数据进行统计分析,通过各类数据挖掘算法探寻数据之间的规律,对业务进行预测和判断。
从事这一方向的工作,需要具备以下技术。
数据分析:ETL、SQL、Python、统计、概率论等。
数据挖掘:算法、机器学习、深度学习、聚类、分类、协同过滤等。
(3)大数据开发方向
大数据开发是大数据在公司内使各个环节得以打通和实施的桥梁和纽带,爬虫系统、服务器端开发、数据库开发、可视化平台建设等各个数据加工环节,都离不开大数据开发的身影。大数据开发需要具备 2 方面的能力:
要了解大数据各类工具的使用方法;
要具备良好的代码能力。
从事这一方向的工作,需要具备的技术有这些:数仓、推荐引擎、Java、Go、爬虫、实时、分布式等。
当然,除了上面这三个大的方向,在整个互联网大数据体系中,还有非常多的细分方向,甚至每一个关键词都可以作为一个方向考虑。随着大数据的发展,我想在未来还会有更多各式各样的岗位等待着我们。
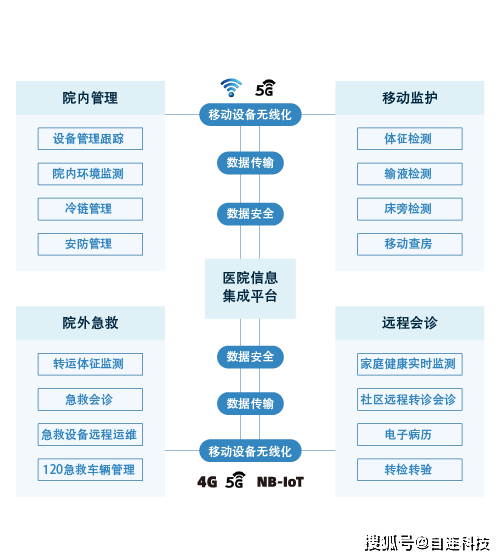
四个基本特点
如果网上搜索大数据,可能一千个专家有一千种定义方式,大数据的4V特性甚至也有5V特性的说法,是最普世最共性的特征,即数量多(Volume)、种类多(Variety)、速度快(Velocity)及数据价值(Value)。
(1)大量数据
这个特征是最明显最基本的特性,正如两个基本条件章节里说的,硬件的发展及数据生产方式的变化,使得数据的数量急剧膨胀。
(2)种类繁多
现在的数据不再局限于数字,你写的一段话、拍下的一张照片、录制的一段音频或者视频,都是大数据的组成部分。这些主要源于我们的视觉、听觉,在不久的将来,我们的触觉、味觉、嗅觉等数据也会进入机器获取的范畴,从而形成完整的数据获取体系。
(3)高速
在大数据的背景下,所有环节都变得更快了。这里的高速不单单指数据的生产速度,还有数据的交换速度、处理速度等。比如,当你在京东商城浏览商品的时候,你的每一次点击都会以毫秒级的时延传输到服务器上,而服务器集群又会根据你的这些行为,迅速地为你推荐出新的商品,在你下一秒的浏览内容中展示出来。显然,如果这个过程太慢,可能还没等后台的数据计算完成,你就已经关掉了京东转头去了淘宝,那岂不是会损失客户?所以,高速也是大数据体系一直不懈追求的目标。
(4)数据价值
我们拥有了大量数据,一定是期望这些数据能给我们带来一些价值。显然,大数据是有价值的,但是大数据价值有一个特色——价值密度低。
比如,危险品生产车间的监控摄像头在 24 小时不间断地记录并回传着数据,但是这些数据通常都是毫无变化的,它日复一日地记录着,每隔一段时间就需要删除一些,以便腾出存储空间。当出现异常的时候,比如说在视频中发现了高温点,可能是车间中存在火苗,这个时候需要立即调用消防系统对火苗进行扑灭,从而防止危险发生。像这种存在价值的数据可能只是摄像头记录的一个微小片段,所以说数据的价值密度较低。
以上就是大数据的一些重要特点。也就是说,符合这些特征的数据,我们基本可以认为是“大数据”。

五大发展里程碑
萌芽期:1980 年,大数据这个词被阿尔文·托夫勒写在了他的新书《第三次浪潮》里,不仅如此,他还声称大数据是第三次浪潮的华彩乐章,这就是大数据一词的由来。阿尔文·托夫勒是一位著名的未来学家,他非常成功地预测了大数据的爆发。
成长期:2008 年 9 月《自然》杂志也推出了名为“大数据”的封面专栏。象征着大数据概念已经成为大家普遍认同的事实。这个阶段,大数据正式诞生了。在这个时间段的中国,以腾讯、网易、新浪、搜狐、百度为代表的主流互联网公司,依赖社交、搜索、门户等产品迅速崛起。
2004 年前后,谷歌发表了三篇论文,也就是我们常说的大数据三驾马车:
分布式文件系统GFS,解决了数据的底层存储问题;
大数据分布式计算框架MapReduce,解决了数据的处理运算问题;
NoSQL 数据库系统BigTable,解决了数据的有序组织问题。
成熟期:一位名叫DougCutting的码农创办了一家小公司,想要做一个超越谷歌搜索的开源搜索引擎,尽管当时的谷歌搜索基本是独步天下的状态了。他先是开发了一个叫 Nutch 的项目,但随着谷歌公布的三驾马车论文,他将目标转向实现 GFS 和 MapReduce 方案,并想办法融合进自己的 Nutch 项目里。后来这个模块被雅虎看中了,于是 Doug Cutting 带着他的项目加入了雅虎,顺手拿了他儿子的一个大象玩具给这个项目命名为 Hadoop。
高潮期:2008年后随着网络、存储、计算等硬件的成熟; 智能手机成为移动业务的标配;Hadoop 项目不断成熟。大量依赖大数据的个性化 App 在这个阶段如雨后春笋般涌出,并迅速壮大。做社交的Facebook,做云服务的亚马逊,做内容服务的今日头条等等都在这个时间内发展起来,赚得盆满钵满。
爆发期:2017年以来,大数据基本上渗透到了人们生活的方方面面。比如说:
无处不在的交通违法监控;疫情之下的健康码。
这些都是大数据的产物。
同时,当前优秀的互联网公司都已经建设起了比较完善的大数据体系架构,并且在各自的业务中进行应用。各种新的数据库、计算引擎、数据流转框架喷涌而出,并随着新的需求不断迭代。伴随着互联网的成熟和发展,这充分说明了技术对于大数据行业发展的重要性,随着人工智能、云计算、区块链等新科技和大数据的融合,大数据将释放更多的可能,迎来全面的爆发式增长。
六个工作环节
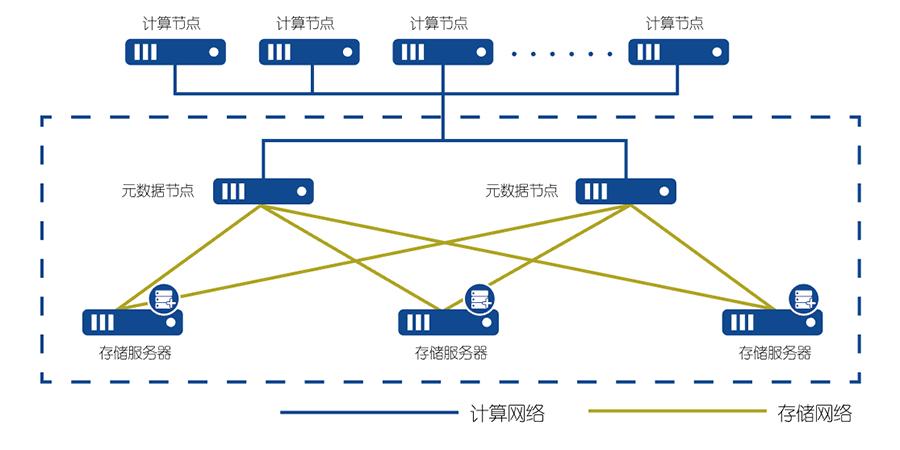
大数据体系在实践中,包含以下环节以及要解决什么样的问题。
(1)数据的采集
各式各样的数据生产方式都需要我们配备完整的数据采集方案,譬如你想要在 App 上收集用户的行为信息,就需要进行各种数据埋点。
(2)数据的存储
虽然说存储的硬件成本降低了,但是终归还是有成本的,同时数据也不可能杂乱无章地堆放在存储设备上,所以对应的数据库和文件存储方案,需要经过精密的设计来支撑这种巨量的数据存取。
(3)数据的计算
目前主流的就是批处理和流处理两种方式,而针对这些方式,又有多种计算框架被研制出来,比如当前应用广泛的 Spark、Flink 等。
(4)数据挖掘与分析
鉴于大量的数据和低密度的价值,我们期望能够使用一些巧妙的方案,从中找到那些有用的信息甚至是结论,于是各种算法与工具层出不穷。
(5)数据的应用
从数据中挖掘到的有价值的信息正在我们的身边发挥着巨大的经济价值,内容推荐、气象预测,乃至疫情控制,都是在大数据的指导之下进行的。
(6)数据安全
大数据有着重要的价值,而这些数据一旦泄露也会成为不法分子危害我们权益的帮手。所以,如何保障数据安全也是一个重要的问题。
大数据时代的思维方式

大数据时代,有哪些思维方式可以帮助我们快速进入工作状态。
全量思维
与全量思维相对应的就是抽样思维,抽样思维在很长的一段时间里,甚至在现在很多的行业和实验中,都扮演者十分重要的角色。在数据获取困难、处理难度大的情况下,抽样思维是一种非常优秀的权宜之计。
然而在大数据场景下,数据的采集已经变得极其方便,数据的存储也不再昂贵,各种硬件的性能不断提高,数据的计算速度也越来越快。尤其是还有很多优秀的研发机构推出了强大的大数据架构方案,比如 Hadoop、Spark、Flink 等,进一步降低了全量处理的成本,使得全量数据分析成为现实。
容错思维
在全量思维的基础之上,第二个重要的思维是容错。
我们所处的世界是纷繁复杂的,不确定性使得我们的世界充满了各种异常、偏差、错误,所以我们收集的全量数据自然也存在着这些问题,数据的残缺、误差、采集设备的不足、对非结构化数据的不同认知等都会引起这些问题。过去,对数据的处理我们往往追求精益求精,希望借助严格的数据筛选策略和足够复杂的计算逻辑来获得完美的效果,然而,这是不符合实际情况的,极端复杂也导致了泛化性能不好java实现协同过滤,在测试阶段的优秀效果,到了实际的生产环境中往往水土不服。
任何模型的准确率都不可能达到100%,在大数据的体系下,我们应该更加关注效率的提升,在这样一个前提下,要容忍那些本身就存在的误差甚至是错误。
相关思维
由于大数据数量众多,而数据中又存在着各种各样的误差,甚至是错误,数据之间的关系错综复杂。通过这些数据,我们会发现其中蕴含着各种各样奇怪的知识,而这些知识都属于“事实”,而非“因果”。比如说,当某个地区在百度上搜索“感冒”的人数超出了往常,你可能会从数据中推测出这里有很多人得了感冒,从而做出一些商业决策,比如说销售感冒药,但是你很难从这个数据中得出他们是为什么得了感冒。因为得感冒的原因很多。
在大数据背景下,我们不再追求难以捉摸的确定的因果关系,而是转向对相关关系的探索。通过对相关关系的分析,我们可以知道:
广东人比东北人更爱泡澡;
香山的 10 月中到 11 月中是全年流量高峰;
美国大选时义乌印谁的旗子多谁就会当选。
 上一篇
上一篇 








