

java数字正则表达式-java正则表达式
正则表达式(regular expression,简称regex)是用来描述匹配一组字符串的模式的字符串。
在String类中,有比较字符串的matches方法和equals方法,matches
该方法的功能比较强大,不仅可以匹配固定的字符串,还可以匹配一组相同模式的字符串
例如。 “Java 很有趣”。匹配(“Java.*”)真
“Java 很酷”。 匹配(“Java。*”)真
“Java 很强大”。 匹配(“Java。*”)真
上面语句中的“Java.*”是一个正则表达式。 他描述了一个字符串模式,它以“Java”开头,后跟 n 个字符串。 这里子字符串“.*”匹配任意字符的 0 个或多个。
正则表达式由文字字符和特殊符号组成。
常用的正则表达式:
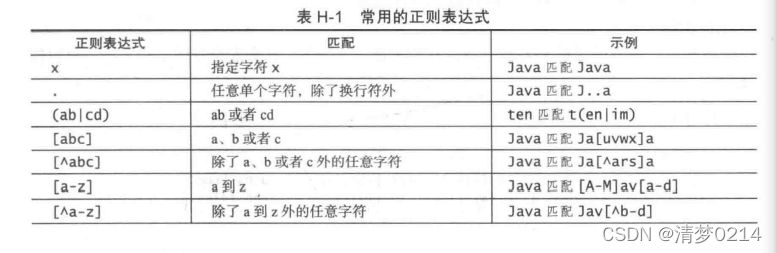
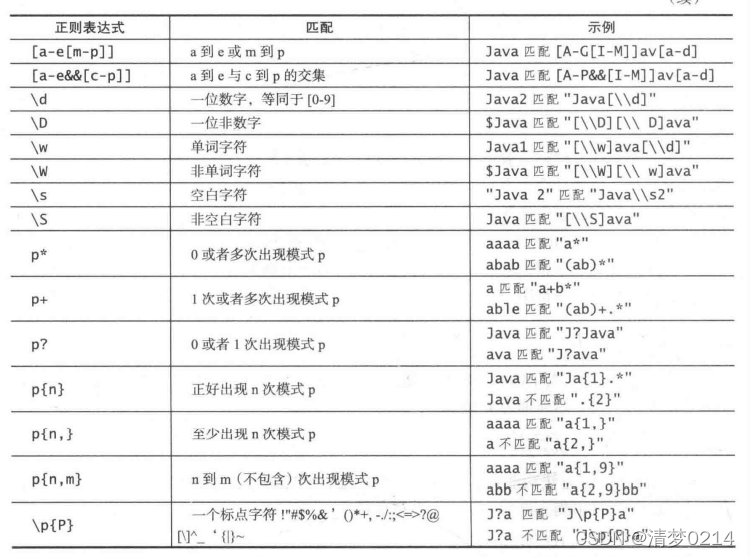
(图片来源《Java语言程序设计与数据结构》附录)
注意:单词字符是任何字母、数字或下划线字符。 所以 \w 匹配任何类字符,包括下划线。 相当于 [^A-Aa-z0-9_]。
注意:表中的最后六个条目 *、+、? , {n}, {n, }, {n,m}称为量词,多用于决定量词前面的模式重复多少次。 例如:A*匹配0个或多个A,A+匹配1个或多个A,A? 匹配0个或1个A。A{3}正好匹配AAA,A{3, }至少匹配3个A,A{3, 6}匹配3到6个A。*等价于{0,},+是相当于 {1,}, ? 相当于{0.1}。
警告:不要在重复量词中使用空格。例如,A{3,6} 不能在逗号后写空格
一个{3,6}。
注意:括号可用于对模式进行分组。例如,(ab){3} 匹配 abababjava数字正则表达式,但 ab{3} 匹配
abbb。
例子
社会安全号码的格式是 xxx-xx-xxx,其中 x 是一位数字。 其正则表达式可以描述为[\\d]{3}-[\\d]{2}-[\\d]{4} 例如:"111-22-3333".matches("[\\ d ]{3}-[\\d]{2}-[\\d]{4}") 返回真。
思考:在这种情况下,可以使用正则表达式来管理用户登录系统时的账号/密码输入格式。
如果字符串与正则表达式匹配,则 String 类的 matches 方法返回 true。 String 类还包含
用于替换和拆分字符串的 repalceAll、replaceFirst 和 split 方法。 replaceAll 方法替换所有匹配的子字符串,replaceFirst 方法替换第一个匹配的子字符串。 例如:
System.out.println("Java Java Java".replaceAll("v\\w'', "wi")); 显示爪夷文爪夷文
System.out.println("Java Java Java".replaceFirst("v\\w'', "wi")); 显示爪夷文Java Java
有两个重载的 split 方法。 split(regex) 方法使用匹配的分隔符将字符串拆分为子字符串
string.例如下面的语句
字符串 [] 标记 = "Java1HTML2Perl"。 拆分(“\\d”);
将字符串“Java1HTML2Perl”拆分成Java、HTML和Perl分别存入tokens[0]、tokens[1]
在令牌[2]中。
在 split(regex, limit) 方法中,limit 参数决定了模式匹配的次数。 如果 limit 为 0,则该模式最多匹配 limit -1 次。
下面是一些例子: "Java1HTML2Perl".split("\\d", 0); 拆分为 Java、HTML、Perl
"Java1HTML2Perl" .split("\\d",1); 拆分为 Java1HTML2Perl
"Java1HTML2Perl" .split("\\d", 2); 拆分为 Java、HTML2Perl
"Java1HTML2Perl".split("\ld", 3); 拆分为 Java、HTML、Perl
注意:默认情况下,所有量词都是“贪婪”的。 这意味着它们将匹配尽可能多的次数。
例如,以下语句显示 JRvaa。 因为第一个匹配成功的是aaa。
系统。 出去 。 print1n("Jaaavaa" .replaceFirst("a+", "R"));
可以通过在其后添加问号 (?) 来更改量词的默认行为。量词变为“不情愿”或
“惰性”java数字正则表达式,意味着它会匹配尽可能少的次数。例如,下面的语句显示 JRaavaa 因为
第一个成功的匹配是 a。
System.out.println("Jaaavaa" .replaceFirst("a+?", "R"));
 上一篇
上一篇 








