

java高并发处理机制-java多线程的并发例子
JAVA并发万字长文,从ReentrantLock到juc框架
ReentrantLock 是 Java 中的可重入锁,它实现了 Lock 接口,与 synchronized 相比,ReentrantLock提供了更强大和灵活的锁机制。
ReentrantLock 的原理
ReentrantLock 是通过一个volatile 的变量和一个 FIFO 的队列来实现的。该 volatile 变量表示当前获得锁的线程,FIFO 队列用来存储等待锁的线程。
具体实现方式是:当一个线程获取锁时,将当前线程设置为 volatile 变量的值。如果其他线程试图获取该锁,则会加入 FIFO 队列的尾部,并标记为等待状态。当持有锁的线程释放锁时,它会唤醒 FIFO 队列头部的线程,这个线程继续执行并获取锁。
ReentrantLock 是可重入锁,意味着同一个线程可以多次获取这把锁。这是通过一个计数器实现的,每获取一次锁,计数器的值就加1。释放锁时计数器减1,减到0时才会真正释放锁。
ReentrantLock 的使用
使用 ReentrantLock 主要有三个步骤:
创建 ReentrantLock 对象
ReentrantLock lock = new ReentrantLock();复制
获取锁
lock.lock();复制
释放锁
lock.unlock();复制
一个使用示例:
ReentrantLock lock = new ReentrantLock();
lock.lock();
try {
// do something...
} finally {
lock.unlock();
}复制
相比 synchronized,ReentrantLock 提供了更丰富的功能,如可以中断正在等待锁的线程,可以设置锁的尝试获取时间等。这使得 ReentrantLock 在许多场景下可以替代 synchronized,成为并发程序的主流选择。
ReentrantLock 的框架使用实例常见于:线程池、死锁检测、队列等。日常开发中也经常会使用 ReentrantLock 来优化并发场景的性能。
ReentrantLock 的公平性选择
ReentrantLock 提供了公平锁和非公平锁两种模式,默认是非公平锁。
公平锁的锁获取顺序是按照线程请求锁的时间顺序来分配的,这保证了所有的线程获取锁的机会都是公平的。而非公平锁的锁获取顺序并不是根据请求锁的时间顺序来的,有可能刚请求的线程先获取到锁,这就是非公平的。
非公平锁的吞吐量通常高于公平锁,但可能造成饥饿,即某些线程长期等待锁。所以选择哪种模式需要根据具体应用来权衡。
使用方式:
// 公平锁:
ReentrantLock lock = new ReentrantLock(true);
// 非公平锁:
ReentrantLock lock = new ReentrantLock(false);
// 默认构造方法:
ReentrantLock lock = new ReentrantLock(); 复制
CAS操作
ReentrantLock 底层使用 CAS(Compare And Swap)操作来实现锁的获取和释放。
CAS操作包含三个操作数:
如果V的值等于A,那么processors将内存值V更新为B。否则,processor不会执行任何操作。
ReentrantLock 通过CAS操作来更新锁的状态,实现高效且线程安全的锁获取和释放。
通过分析 ReentrantLock 的原理和使用,我们了解到它是一个高效且灵活的锁实现,相比 synchronized 具有更高的扩展性和更丰富的功能。在并发环境下,ReentrantLock 应该是我们首选的锁机制,它的公平与非公平实现和CAS操作也为我们提供了细粒度的控制选项。
参考框架中的ReentrantLock使用ThreadPoolExecutor 中的应用

线程池ThreadPoolExecutor 使用 ReentrantLock 来控制对线程池状态的访问。主要有两个地方:
用于控制对 workerCount 和 runState 变量的访问。这两个变量分别代表线程池中的线程数和线程池状态。用于控制对等待队列和已完成队列的访问。这是为了保证在将任务添加/删除到这些队列时的线程安全。
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// Packing and unpacking ctl
private static int runStateOf(int c) { return c & ~CAPACITY; }
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }
// CAS (atomic) access to ctl
private boolean compareAndIncrementWorkerCount(int expect) {
return ctl.compareAndSet(expect, expect + 1);
}
private boolean compareAndDecrementWorkerCount(int expect) {
return ctl.compareAndSet(expect, expect - 1);
}
private void decrementWorkerCount() {
do {} while (!compareAndDecrementWorkerCount(ctl.get()));
} 复制
可以看到,ThreadPoolExecutor 通过 CAS 操作来原子地更新 ctl 变量,而 ctl 变量 Contains 线程池的状态和线程数,这就保证了线程池状态的修改的线程安全。
同时,ThreadPoolExecutor 也使用 ReentrantLock 来保护队列的访问,如:
private final ReentrantLock mainLock = new ReentrantLock();
private void addWorker(Runnable firstTask, boolean core) {
mainLock.lock();
try {
// ...
} finally {
mainLock.unlock();
}
}复制
所以,ReentrantLock 在 ThreadPoolExecutor 中发挥了很重要的作用,用于保证线程池状态和队列访问的线程安全。
ConcurrentHashMap中的应用
ConcurrentHashMap 也广泛使用了 ReentrantLock 来实现线程安全。主要使用在:
分段锁 - ConcurrentHashMap 使用 16 个锁来控制对 hash 表的访问,这 16 个锁就是 ReentrantLock 实例。重构链表时的锁 - 当两个线程并发扩容时,如果发现 hash 冲突,需要对相应的链表进行重构。这个过程使用的就是 ReentrantLock。读写锁 - 除了分段锁外,ConcurrentHashMap 还提供了读写锁来实现对 get 操作的优化。读锁就是 ReentrantReadWriteLock 的读锁。
下面是 ConcurrentHashMap 中使用 ReentrantLock 的部分示例代码:
/**
* The segments, each of which is a specialized hash table.
*/
final Segment[] segments;
static final class Segment extends ReentrantLock {...}
final ReentrantLock putLock = new ReentrantLock();
public V put(K key, V value) {
Segment s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
s = ensureSegment(j);
s.lock(); // lock the segment
try {
// ...
} finally {
s.unlock(); // unlock the segment
}
}
final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
private final ReentrantReadWriteLock.ReadLock rl = rwl.readLock();
private final ReentrantReadWriteLock.WriteLock wl = rwl.writeLock();
public V get(Object key) {
rl.lock(); // lock for reading
try {
// ...
} finally {
rl.unlock();
}
} 复制
通过代码我们可以看出,ReentrantLock 被广泛用于 ConcurrentHashMap 的各个方面,起到了保证线程安全的关键作用。
小结
综上,我们分析了 ReentrantLock 在 ThreadPoolExecutor 和 ConcurrentHashMap 两个重要开源框架中的应用。可以看出:
ReentrantLock 用于保证并发环境下对关键数据结构的访问线程安全。相比 synchronized,ReentrantLock 提供更加灵活的锁机制,如可中断锁、超时锁、公平锁等,这为框架的并发控制提供了更精细的权衡。ReentrantLock 通过 CAS 操作来高效地实现锁的获取和释放,这也是它比 synchronized 性能更高的原因之一。
熟悉这些开源框架的实现原理,不仅可以让我们在使用时更加得心应手,也可以在我们自己设计框架时学以致用。ReentrantLock 的应用就是一个很好的参考范例。
ReentrantLock 在实践中的运用
在实际开发中,我们也常常会使用 ReentrantLock 来实现高效的并发控制。这里给出几个示例:
自定义链表的线程安全实现
我们可以使用 ReentrantLock 来实现一个线程安全的链表:
public class ThreadSafeLinkedList {
private Node head;
private ReentrantLock lock = new ReentrantLock();
public void add(int value) {
Node node = new Node(value);
lock.lock();
try {
node.next = head;
head = node;
} finally {
lock.unlock();
}
}
public void remove() {
lock.lock();
try {
head = head.next;
} finally {
lock.unlock();
}
}
private class Node {
int value;
Node next;
public Node(int value) {
this.value = value;
}
}
}复制
我们在添加节点和删除节点时获取 ReentrantLock 的锁,这样可以确保在并发环境下链表操作的线程安全。
实现一个阻塞队列
我们可以使用 ReentrantLock 与 Condition 对象来实现一个阻塞队列:
public class BlockingQueue {
private LinkedList queue = new LinkedList<>();
private ReentrantLock lock = new ReentrantLock();
private Condition notEmpty = lock.newCondition();
public void put(Integer value) {
lock.lock();
try {
queue.add(value);
notEmpty.signal(); // 唤醒等待的线程
} finally {
lock.unlock();
}
}
public Integer take() {
lock.lock();
try {
while (queue.isEmpty()) {
notEmpty.await(); // 等待
}
return queue.removeFirst();
} catch (InterruptedException e) {
// ...
} finally {
lock.unlock();
}
}
} 复制
put 方法用于添加元素到队列,并唤醒等待的消费线程。take 方法用于消费元素,如果队列为空则等待生产者的通知。ReentrantLock 与 Condition 配合使用,很好地实现了阻塞队列的功能。
其他
综上,ReentrantLock 在实践中有很强的实用性,我们可以运用它来实现定制化的并发控制和复杂的协作逻辑。
总的来说,优先考虑使用 ReentrantLock,而不是 synchronized,这可以使我们的程序更加灵活高效。
ReentrantLock总结ReentrantLock 的原理:基于volatile变量和FIFO队列实现,支持可重入。ReentrantLock 的使用:lock()获取锁,unlock()释放锁,提供了更加灵活的锁机制。ReentrantLock 的公平性选择:公平锁和非公平锁,需要根据具体场景来选择。ReentrantLock 底层使用 CAS 操作来实现高效的锁获取和释放。ReentrantLock 在 ThreadPoolExecutor 和 ConcurrentHashMap 等开源框架中的应用,用于保证并发环境下的数据结构和状态的线程安全。ReentrantLock 在实践中的几个运用示例:自定义线程安全链表、阻塞队列的实现、锁超时和中断、公平锁等。
ReentrantLock 是一个功能强大且高效的锁实现,它应该是我们实现并发控制的首选方案。熟练掌握 ReentrantLock 有助于我们设计出更加健壮的多线程程序。
ReentrantLock FAQ
这里总结一些关于 ReentrantLock 常见的问题.
为什么ReentrantLock是可重入的?
可重入意味着同一个线程可以多次获取同一把锁。对于 ReentrantLock 来说,这是实现隐式锁的必要功能。
举个例子,如果一个类中的方法获取了锁,然后再调用同一个类的另一个方法,第二个方法也会自动获取锁。如果锁不可重入,那么第二个方法将永远等待锁,导致死锁。
所以,可重入的锁一定要在实现隐式锁机制的锁中实现,ReentrantLock做了这点考虑,使其成为更易用的锁。
与synchronized相比,ReentrantLock有什么优势?
相比 synchronized,ReentrantLock 有以下优势:
灵活性:ReentrantLock 提供了更加灵活的锁机制,如可中断锁、超时锁、公平锁等。这在许多场景下都很有用。性能:基于CAS实现,ReentrantLock的性能通常优于synchronized。尤其是在高并发的场景下,优势更加明显。可中断:获取 ReentrantLock 锁的线程可以响应中断,这在调试死锁时很有帮助。而synchronized的锁获取不可中断。超时:ReentrantLock可以设置锁的最大等待时间,这可以快速响应获取锁失败的情况。synchronized 的锁一直等待,容易发生死锁。公平性:可以选择公平锁或非公平锁。synchronized 的锁始终是非公平的。条件变量:ReentrantLock 提供的 Condition可以实现复杂的线程协作,而synchronized很难实现这点。
所以,总体来说,ReentrantLock提供了更强大和灵活的锁机制。如果需要这些功能,那么选择 ReentrantLock 是更好的选择。当然,在某些极简单的场景下,synchronized 也完全能够满足需求。
Condition和wait/notify对比?
Condition 是 JDK5 中引入的替代 Object 的 wait/notify 的一个工具,它依赖于 Lock 对象。主要有以下差异:
wait/notify必须和同步块一起使用,Condition可以和任何具有锁的对象一起使用。wait/notify只能在同步方法或同步块内调用,而Condition可以在任何地方调用。wait/notify唤醒的线程是随机的,而Condition可以精确地唤醒指定数量的线程。Condition可以提供更加强大的线程通信机制。
所以,总体来说,Condition的功能更加强大和灵活。对于复杂的线程协作逻辑,Condition是更好的选择。
不过,Condition依赖于Lock对象,使用略微复杂。而wait/notify是Object的内置方法,使用简单,适用于基本的线程通信场景。
所以,根据具体需求选择对应的工具就可以了。
ReentrantLock和synchronized的锁释放是否一定成功?
不一定。释放锁的操作并非原子操作,所以锁释放可能会失败。
对于 synchronized 来说,锁的释放依赖于 JVM,如果 JVM 在锁释放的时刻进行了线程切换,那么就可能导致锁释放失败。不过 JVM 总体来说会保证锁一定能被成功释放。
而对于 ReentrantLock 来说,它是通过 CAS 操作来释放锁的。如果 CAS 操作失败,那么锁的释放也就失败了。不过 ReentrantLock 提供了一套机制来保证锁最终一定会成功释放:
当释放锁失败时,锁持有线程会自旋一段时间再重试。如果重试多次仍未成功,则会加入一个释放锁的队列,并停止自旋。锁对象会定期重试那些在释放锁队列中的线程。为了避免重试过于频繁影响性能,释放锁操作会有一个最大自旋时间和最大重试次数。如果超过最大重试次数仍未成功,则会采取更加激进的措施来释放锁,比如通过 Thread.stop() 强制终止锁持有线程。
所以,总体来说,虽然锁释放可能失败,但是 JVM 和 ReentrantLock 都提供了相应的机制来保证锁最终一定会被成功释放,对程序的正确性影响不大。但频繁的释放失败会影响程序的性能,所以我们应该尽量减少造成这种情况的可能。
公平锁与非公平锁的优缺点?
公平锁与非公平锁的主要区别在于锁的分配方式不同:
两者有以下优缺点:
公平锁:
优点:防止饥饿,保证每个线程获取锁的机会。
缺点:公平策略会降低吞吐量。
非公平锁:
优点:通常可以提高吞吐量。
缺点:可能会导致某些线程长期无法获取锁(饥饿)。

所以,选择哪种锁需要根据具体场景来权衡:
如果对吞吐量要求较高,可以选择非公平锁,并采取其他手段防止饥饿。
如果需要严格的公平性,以防止某些线程无法获取锁,可以选择公平锁,并容忍一定程度的吞吐量降低。
如果同时需要高吞吐量和公平性,可以选择自适应的锁,它可以根据当前情况动态选择公平锁或非公平锁。
综上,没有一种锁可以绝对优于另一种,我们需要根据具体应用场景选择最合适的锁。
如何解决ReentrantLock带来的死锁问题?
ReentrantLock 虽然提供了比 synchronized 更强大的锁机制,但是也带来了更复杂的死锁问题。主要有以下几点需要注意:
避免嵌套锁:一个线程获取多个锁时,必须遵循获取锁的顺序,否则很容易出现死锁。不要在锁内调用可被其他锁调用的方法:如果在锁内调用其它锁保护的方法,那么可能会出现死锁。使用 lockInterruptibly() 方法:这样可以在等待锁的线程中响应中断,提高死锁发生时的可调试性。使用 tryLock() 设置超时:如果在指定超时时间内无法获取锁,线程可以选择放弃获取,避免死锁发生。分层加锁:按照锁的粒度从大到小依次加锁,这样可以避免加锁顺序错误导致的死锁。使用 Thread.join() 代替同步:在某些场景下,join() 可以代替同步,而 join() 不会有加锁操作,所以也就不存在死锁问题。选择非阻塞算法:在并发程序设计过程中,尽量选择非阻塞的数据结构和算法,这样可以避免加锁产生死锁。合理设置同步范围:同步范围应尽可能小,只在真正需要同步的地方添加锁,这样可以减少加锁操作带来的死锁风险。检查加锁顺序:对复杂的并发程序来说,最好能检查加锁顺序,避免加锁顺序的错误配置导致死锁发生。这通常需要对程序加锁逻辑进行静态检查。使用 jps 和 jstack 检查死锁:如果发生死锁,可以使用这两个工具来分析线程 Dump,找到死锁的根源,然后修复代码。
总之,解决 ReentrantLock 带来的死锁问题主要依靠灵活的使用它提供的功能,遵循良好的加锁规则与并发设计原则,选择合理的线程协作方式,并在发生死锁时能够快速找到问题所在。
ReentrantLock 中的 Condition 如何唤醒指定数量的线程?
ReentrantLock 提供的 Condition 对象允许我们唤醒指定数量的线程。这是它相比 Object 的 wait/notify 具有的优势之一。
Condition 定义了几个方法来唤醒线程:
那么如何实现唤醒指定数量的线程呢?主要靠循环调用 signal() 方法来实现:
// 唤醒 n 个线程
for (int i = 0; i < n; i++) {
condition.signal();
}复制
每调用一次 signal(),就会从等待队列中唤醒一个线程。所以通过循环调用,我们可以精确地唤醒想要的线程数量。
例如,我们可以实现一个生产者-消费者场景,生产者负责唤醒指定数量的消费线程:
public class ProducerConsumer {
private ReentrantLock lock = new ReentrantLock();
private Condition condition = lock.newCondition();
private int queueSize = 0;
public void produce(int num) {
lock.lock();
try {
// 生产 num 个商品
queueSize += num;
// 唤醒 num 个消费者线程
for (int i = 0; i < num; i++) {
condition.signal();
}
} finally {
lock.unlock();
}
}
public void consume() {
lock.lock();
try {
while (queueSize == 0) {
// 如果没有商品,等待生产者的通知
condition.await();
}
// 消费一个商品
queueSize--;
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}复制
在这个例子中,生产者线程会调用 produce() 方法生产商品,并唤醒指定数量的消费者线程。消费者线程调用 consume() 方法消费商品,如果商品为空会等待生产者的通知。
所以,通过 Condition 的 signal() 方法循环调用,我们可以精确地唤醒指定数量的线程,这在实现复杂的线程协作逻辑时很有用。
这个例子可以帮你加深对 Condition 的理解,在并发编程中运用自如。Condition 是一个很强大的工具,它配合 ReentrantLock可以实现各种复杂的线程间协作与控制。
ReentrantLock 的读写锁如何实现?
ReentrantLock 本身不提供读写锁的功能,但是我们可以通过它提供的锁与条件变量来简单实现一个读写锁。
读写锁主要有以下几个方法:
读写锁还需要遵循以下规则:
同一时刻只允许有一个写锁,或者多个读锁写锁不能与其他锁(读锁或写锁)同时持有读锁之间可以同时被多个线程持有
基于此,我们可以这样实现一个简单的读写锁:
public class ReadWriteLock {
private ReentrantLock lock = new ReentrantLock();
private Condition readCondition = lock.newCondition();
private Condition writeCondition = lock.newCondition();
private int readCount = 0;
private boolean writing = false;
public void readLock() {
lock.lock();
try {
while (writing) { // 如果有线程持有写锁,等待
readCondition.await();
}
readCount++; // 增加读锁持有数
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void readUnlock() {
lock.lock();
readCount--; // 减少读锁持有数
if (readCount == 0) { // 如果没有线程持有读锁
writeCondition.signal(); // 唤醒等待的写线程
}
lock.unlock();
}
public void writeLock() {
lock.lock();
try {
while (readCount > 0 || writing) { // 如果有读锁或写锁,等待
writeCondition.await();
}
writing = true; // 标记有线程持有写锁
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void writeUnlock() {
lock.lock();
writing = false; // 标记写锁已经释放
readCondition.signalAll(); // 唤醒所有等待的读线程
writeCondition.signal(); // 唤醒一个等待的写线程
lock.unlock();
}
}复制
通过 ReentrantLock 与 Condition,我们实现了一个简单的读写锁。读锁通过读锁持有数 readCount 来实现多个线程同时获取,写锁通过 writing 标记来保证同一时间只有一个线程获取。
读写锁是一个比较复杂的并发工具,上面这个实现还比较简单,但已经能够满足基本的需求。如果需要一个更为高级的读写锁,可以参考 JDK 中的 ReadWriteLock 接口的实现。
通过这个例子可以加深你对 ReentrantLock 的理解,以及如何运用它来实现各种并发控制工具。读写锁只是其中一个例子,我们还可以实现各种锁,信号量,栅栏等并发工具。
ReentrantLock 的锁降级会带来什么问题?
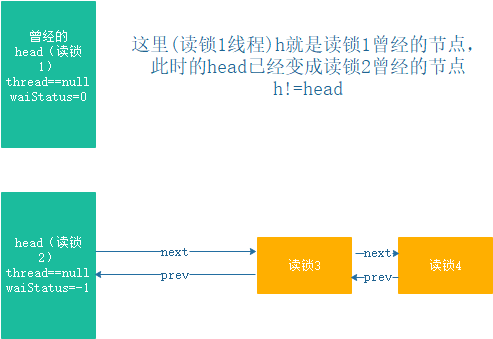
锁降级指的是线程持有较高级别的锁(例如写锁),之后又获取较低级别的锁(例如读锁)的场景。对于 ReentrantLock 来说,这会带来一些问题:
无法实现锁降级:ReentrantLock 自身并不支持锁降级功能。如果一个线程持有写锁,之后再获取读锁,这两个操作是互斥的,所以无法实现锁降级。可能导致死锁:如果实现锁降级,必须严格遵守加锁与解锁的顺序。否则很容易产生加锁顺序错误,导致死锁。例如:
线程1获取写锁 -> 线程2获取读锁 -> 线程1尝试获取读锁,等待线程2释放读锁
线程2尝试获取写锁,等待线程1释放写锁 -> 死锁
需要额外的读写状态标记:要实现锁降级,需要维护读写状态,以判断线程是否可以从写锁降级到读锁。这会增加实现的复杂度。锁消除带来的并发问题:锁降级其实是一种锁消除的手段,它可以提高并发度。但是,并不一定是越高的并发度越好。过高的并发也会带来令人难以应对的并发问题。
所以,对 ReentrantLock 来说,锁降级是一个比较复杂的特性,它需要解决许多并发方面的困难才能实现。通常只有在读写锁中才会提供锁降级的功能,而唯独会要求使用者遵守一定的加锁顺序与规则,避免死锁等问题的发生。
对于一般使用 ReentrantLock 的场景,不建议去实现锁降级。ReentrantLock 本身支持可重入,但这仅限于同一种锁(写锁或读锁)。如果我们需要锁降级功能,可以选择 JDK 中的 ReadWriteLock 等并发工具。
在并发领域,锁降级是一个比较高级的功能,建议我们在熟练掌握 ReentrantLock 的基本使用后才去尝试实现。
自旋锁和互斥锁的区别与适用场景?
自旋锁:
互斥锁:
所以,两者适用的场景也不同:
自旋锁:适用于锁被占用时间极短的场景,这时自旋可以避免上下文切换带来的开销,获得更好的性能。
互斥锁:适用于锁被占用时间较长,同步段较长的场景。这时互斥锁可以避免自旋消耗过多 CPU 资源的问题。
实际上,我们很难准确判断锁被占用的时间,所以两种锁都采取一定的自适应策略:
ReentrantLock 就采用了自适应的策略,它会在一定次数的自旋后采用互斥锁阻塞线程。所以,我们使用 ReentrantLock就无需过于关注自旋锁与互斥锁的区别,ReentrantLock 会根据当前情况选择最优的策略。
总之,自旋锁与互斥锁各有优缺点,我们需要根据锁被占用的时间长短选择最合适的同步手段。但在实际开发中,很难准确判断这个时间,所以 ReentrantLock 等并发工具采用自适应策略,这也是它们性能强劲的原因之一。
CountDownLatch与CyclicBarrier的区别?
CountDownLatch 和 CyclicBarrier 都是用于线程协作的工具类,但有以下主要区别:
CountDownLatch:
CyclicBarrier:
所以主要区别在于:
CountDownLatch 是一次性的,主要用于一个线程等待多个线程。
CyclicBarrier 可循环使用,主要用于多个线程相互等待。
示例代码:
CountDownLatch:
CountDownLatch countDownLatch = new CountDownLatch(3);
new Thread(() -> {
System.out.println("子线程1执行完毕");
countDownLatch.countDown();
}).start();
new Thread(() -> {
System.out.println("子线程2执行完毕");
countDownLatch.countDown();
}).start();
countDownLatch.await();
System.out.println("所有子线程执行完毕"); // 等待子线程执行完,然后打印复制
CyclicBarrier:
CyclicBarrier cyclicBarrier = new CyclicBarrier(3);
new Thread(() -> {
System.out.println("子线程1到达栅栏");
cyclicBarrier.await();
}).start();
new Thread(() -> {
System.out.println("子线程2到达栅栏");
cyclicBarrier.await();
}).start();
cyclicBarrier.await();
System.out.println("所有子线程到达栅栏"); // 等待所有子线程到达,然后同时继续复制
所以根据实际需要,选择使用 CountDownLatch 还是 CyclicBarrier。它们是 JDK 中实现线程协作的两个很有用的工具。
Java中的阻塞队列你了解哪些?各自的特点是什么?
Java 中提供了以下几种阻塞队列:

ArrayBlockingQueue:基于数组的阻塞队列,遵循FIFO原则。LinkedBlockingQueue:基于链表的阻塞队列,遵循FIFO原则。PriorityBlockingQueue:具有优先级的阻塞队列。DelayQueue:具有延时性的阻塞队列。SynchronousQueue:不存储元素的阻塞队列。
除此之外,还有LinkedTransferQueue、LinkedBlockingDeque等。
阻塞队列提供了阻塞的插入、移除操作,它们在并发编程中非常有用。我们可以根据实际场景选择合适的阻塞队列。它们有各自的特点,需要权衡吞吐量、排序、延时等因素来决定用哪个队列。
CountDownLatch和Semaphore的区别与应用场景?
CountDownLatch 和 Semaphore 都是用于控制线程并发访问的工具类,但有以下主要区别:
CountDownLatch:
Semaphore:
主要应用场景:
CountDownLatch:
使一个线程等待多个线程完成各自工作后再继续执行。例如,主线程等待多个子线程完成初始化工作。
Semaphore:
示例代码:
CountDownLatch:
CountDownLatch countDownLatch = new CountDownLatch(3);
new Thread(() -> { // 子线程1
System.out.println("子线程1开始执行");
countDownLatch.countDown();
System.out.println("子线程1执行完毕");
}).start();
new Thread(() -> { // 子线程2
System.out.println("子线程2开始执行");
countDownLatch.countDown();
System.out.println("子线程2执行完毕");
}).start();
countDownLatch.await(); // 主线程等待
System.out.println("所有子线程执行完毕");复制
Semaphore:
Semaphore semaphore = new Semaphore(2); // 许可证数量为2
new Thread(() -> {
try {
semaphore.acquire(); // 获取一个许可证
System.out.println(Thread.currentThread().getName() + "获取到许可证");
TimeUnit.SECONDS.sleep(2);
semaphore.release(); // 释放许可证
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
new Thread(() -> { // 其他线程也申请许可证
try {
semaphore.acquire();
System.out.println(Thread.currentThread().getName() + "获取到许可证");
TimeUnit.SECONDS.sleep(2);
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start(); 复制
所以根据需要控制线程启动顺序还是资源访问,选择使用 CountDownLatch 或 Semaphore。它们都是 Java 并发包中比较基本但非常有用的工具。
Java中的阻塞算法你了解哪些?
Java 中提供了几种常见的阻塞算法:
互斥锁(Mutual Exclusion Lock):用于保证同一时间只有一个线程可以访问共享资源。例如 ReentrantLock。读写锁(Read-Write Lock):用于解决读写操作的互斥问题。在同一时间可以允许多个读线程或一个写线程访问数据。例如 ReadWriteLock。信号量(Semaphore):用于控制可以访问某组资源的线程数量。它内部维护一个计数器,每调用一次 acquire() 方法计数器减 1,调用 release() 方法计数器加 1。屏障(Barrier):用于使多个线程相互等待,只有当所有线程都到达屏障点时才可以继续执行。例如 CyclicBarrier。栅栏(Latch):用于使一个或多个线程等待其他线程完成工作后才可以继续执行。区别于 Barrier,栅栏是一次性的。例如 CountDownLatch。 阻塞队列(Blocking Queue):用于不同线程之间通过队列进行数据传递,当队列为空或满时会使生产者或消费者线程等待。选择器(Selector):基于事件驱动的 I/O 复用模型。用于监听多个网络连接的就绪事件,包括连接就绪、读就绪和写就绪等。线程池(ThreadPoolExecutor):用于创建一定数量的线程,重复使用以便需要时创建新线程。它内部维护着一组线程,等待监督管理者分派可执行的任务。
这些都是 Java 并发包中比较基本与常用的阻塞算法与工具。通过它们,我们可以实现各种线程间的协作与并发控制。
互斥锁用于独占资源,读写锁用于读多写独占,信号量用于资源池,屏障与栅栏用于线程协调,阻塞队列用于生产者消费者,选择器用于 I/O 多路复用,线程池用于线程复用。掌握它们的原理与用法,是成为并发编程高手的基础。
阻塞算法虽然会使线程等待,但通过 Thread.sleep() 等方式实现的等待不属于阻塞,因为它会释放 CPU 使用权。阻塞算法会使线程在等待过程中保持活跃状态,这是一个重要的区别。
常见的并发容器与并发集合?
Java 提供了几种并发容器与集合,主要有:
ConcurrentHashMap: 线程安全的 HashMap,通过分段锁实现高效并发。CopyOnWriteArrayList: 读写分离的线程安全 List,采用写入时复制的思想实现。BlockingQueue: 线程安全的队列,常用于生产者消费者场景。例如 ArrayBlockingQueue,LinkedBlockingQueue 等。ConcurrentSkipListMap: 线程安全的有序 Map,通过跳表数据结构实现。CopyOnWriteArraySet: 与 CopyOnWriteArrayList 类似,采用写入时复制的 Set。读多写少场景,迭代时快照数据,不会抛出并发修改异常。不支持条件操作,添加、删除单个元素操作时需要遍历并复制数据。
理解并发容器与集合的特性,选择合适的集合来解决问题,这些都是并发编程的重要技能。它们可以有效解决多线程环境下的线程安全问题,并且性能较好。并发程序设计的难点在于处理好同步与互斥,选择高效的同步手段与数据结构。并发集合正是在这方面提供了很好的支持。
Java 8中新增的并发API有哪些?StampedLock:乐观读锁与悲观写锁相结合的锁算法。它可以提高读操作的效率,适用于读多写少的场景。LongAdder:高并发场景下统计值的累加器,比 AtomicLong 性能更好。CompletableFuture:代表异步计算结果的完整的 Future。它提供了很丰富的 API 来组合(thenCombine() 等)执行多个 Future,对它们的结果进行处理(thenApply() 等)。CompletionStage:与 CompletableFuture 差不多,但 API 更简单。常与 Stream 搭配使用。
这些 API 使异步编程变得更简单,也为我们提供更多的并发工具。虽然学习成本也有所提高,但使用它们可以轻松编写出高性能的并发程序。Java 一直在着力丰富其并发支持与工具。理解并熟练使用这些 API 有助于我们编写出更高效的多线程程序。这也是成为并发编程高手必须掌握的技能。
JDK 中的并发工具类有哪些?你最常用的有哪些?
JDK 中提供了许多并发工具类,主要有:
Executor 和 ExecutorService:用于线程池与任务执行。这是我使用最频繁的工具类之一。CountDownLatch 和 CyclicBarrier:用于线程同步协作。CountDownLatch 更常用。Semaphore:用于控制对某组资源的访问权限。用来实现资源池等机制。BlockingQueue:线程安全的队列,常用于生产者消费者场景。ArrayBlockingQueue 和 LinkedBlockingQueue 使用较多。Lock 和 ReentrantLock:用于显式锁定,替代 synchronized。ReentrantLock 是我最常使用的锁实现。Atomic 系列类:用于原子操作,线程安全。AtomicInteger,AtomicBoolean 和 AtomicReference 使用较频繁。ConcurrentHashMap:线程安全的 HashMap。这可能是我使用最多的并发集合了。CopyOnWriteArrayList:读写分离的线程安全 List,适用于读多写少的场景。偶尔会使用。 CompletableFuture:代表异步计算结果的 Future,可以串行执行任务和处理计算结果。Java 8 中使用较频繁。ForkJoinPool:Java 7 加入的分治框架,用来并行执行任务。适用于可以分治的 CPU 密集型计算。
除此之外,还有 ConcurrentSkipListMap、CopyOnWriteArraySet、StampedLock 等并发类。
这些并发工具类和集合覆盖了并发编程中最主要与常用的功能。掌握它们的特性与用法,可以有效编写出高效与正确的多线程程序。
这些类可以解决线程池、线程同步、互斥与协作、资源控制、原子操作、线程安全集合与异步编程等方面的问题。所以对我来说,它们是最重要与不可或缺的并发工具。
 上一篇
上一篇 








