

java图片识别技术-java图片验证码识别
ocr是Optical Character Recognition的简写,就是光学字符识别技术。主要是对包含文本资料的图片进行识别,获取文本信息的技术。
目前tesseract-ocr这个工具可以很方便的在Windows、Linux、Mac下安装。
windows下的安装链接:
这个工具安装之后,需要设置环境变量TESSDATA_PREFIX,这个变量是设置tesseract安装目录下tessdata的目录位置。
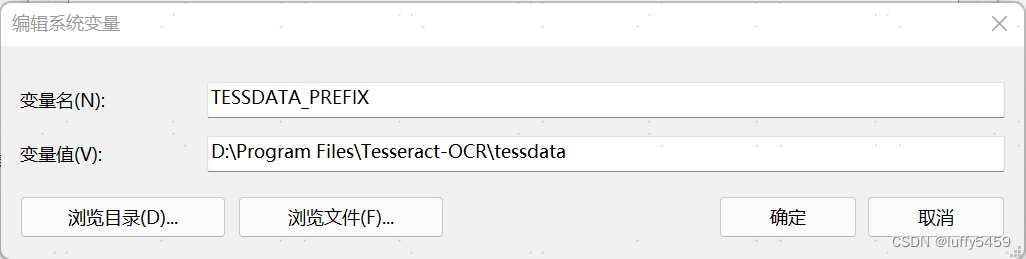
为了在命令行下使用tesseract可执行程序,最好把tesseract-ocr安装路径加入Path环境变量中。
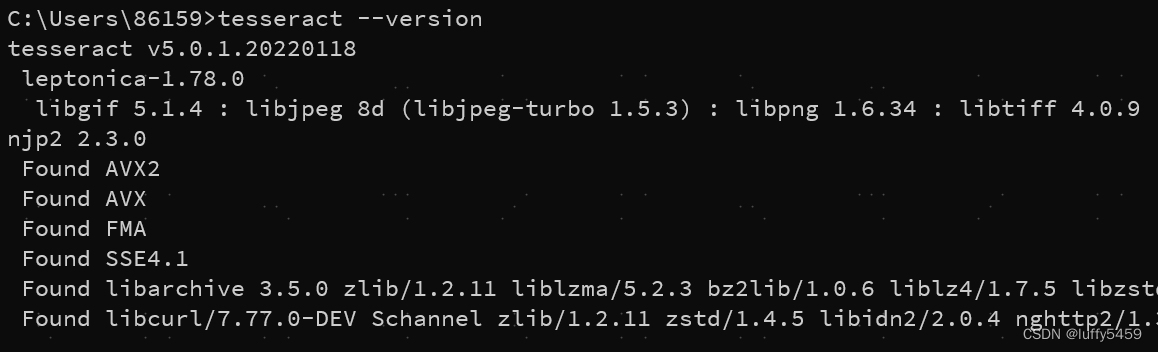
这样,我们在命令行下就可以使用tesseract命令了,如下是检验tesseract安装是否正确:
我们可以使用一个带字符的图片做验证:
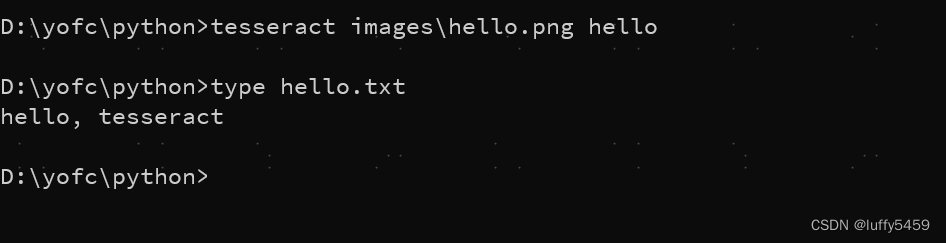
该图片就是hello.png,上面有“hello.tesseract”字样。

命令行下,通过tesseract images\hello.png hello,可以把images目录下的hello.png图片识别,提取的文字保存在hello.txt文件中。
/
以上是通过tesseract-ocr工具直接提取图片中的字符,下面通过程序来提取,这里以java程序为例,加入net.sourceforge.tess4j依赖。
net.sourceforge.tess4j
tess4j
4.6.0
Java代码也是极其简单:
package ocr;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import java.io.File;
public class TestOCR {
public static void main(String[] args) {
Tesseract instance = new Tesseract();
//instance.setDatapath("D:\\Program Files\\Tesseract-OCR\\tessdata");
File imageFile = new File("D:\\yofc\\python\\images\\hello.png");
try {
String result = instance.doOCR(imageFile);
System.out.println(result);
} catch (TesseractException e) {
e.printStackTrace();
}
}
}
运行程序,打印信息如下:
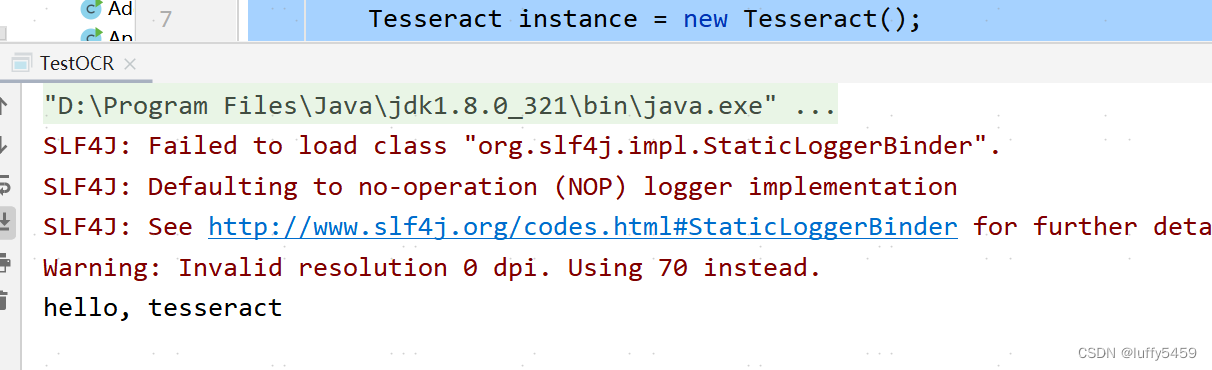
这段代码,就是新建了一个Tesseract实例,然后就开始识别图片文件,仅仅四行代码就完成了识别和打印识别结果在内的功能。其实有的地方提到需要设置训练文件位置,如果我们前面的安装设置了TESSDATA_PREFIX,这里就不用设置了,本例就注释了这行代码:
instance.setDatapath("D:\\Program Files\\Tesseract-OCR\\tessdata");同样可以运行成功,因为在Tesseract实例化的时候,会读取系统变量TESSDATA_PREFIX的值java图片识别技术,并进行设置:
public Tesseract() {
try {
this.datapath = System.getenv("TESSDATA_PREFIX");
} catch (Exception var5) {
} finally {
if (this.datapath == null) {
this.datapath = "./";
}
}
}至此,OCR示例就已经说完了,对于java开发而言,代码极其简单。有的地方,采用执行命令的方式,通过模拟命令行调用tesseract识别图片java图片识别技术,其实没必要,那种代码如果移植,又需要设置linux环境下的安装路劲,非常麻烦。
 上一篇
上一篇 








