

java数组length属性-java数组中length
“
本文为掘金社区首发签约文章,未获授权禁止转载。
”序
开新坑了,这次是数据结构与算法专题,保证不鸽,此专题将会分为三部分:
基础数据结构 :除了本章标题中这些还会有哈希表、树、堆等数据结构。
排序算法 :单独介绍一些常用常见算法如,冒泡、选择、插入、归并、快排、堆排序等。
高级数据结构 :高级数据结构不是说它更高级,主要是在前文的基础数据结构上的扩展如,B+树(树中N树的一种)、红黑树(业界常用的自平衡树)和一些改进的散列如布谷鸟之类的。
当然上面这些只是我目前的写作计划,可能会加入更多内容,请大家拭目以待吧。
本章正式开始之前,先聊聊我对数据结构的看法吧,老生常谈的一句话是:
“
程序 = 数据结构 + 算法。
”
学习数据结构与算法对我们写程序的人有多么重要我举几个例子,大家就明白了。
首先大家要知道,数据结构和算法这些东西都是为了解决现实问题而生的,比如我们的数据库中有1000w条数据吧,我想瞬间查询到一个我想要的数据,这能做到吗?
如果你没有学过数据结构与算法,对查询这种事第一时间的反应应该是遍历,但是对1000w 的数据量进行遍历将会极慢极慢。
有更好的办法来解决这个问题吗?
有,可以通过哈希表数据结构组织这些数据,哈希表能够让我们以O(1) 的时间复杂度快速查询到我们任何想要的数据,无论是1000w还是2000w,都能在瞬间查询到任何我们想查询到的数据,这是这么令人惊叹的效果,中间件Redis 和国产数据库新秀TiDB中的查询都是通过哈希表做的。
除了哈希表,我们也可以通过树型数据结构来做这件事,比如关系型数据库中常用的B+索引,它就是一个树型结构,是一个N树,它能以O(logN) 的速度进行查询,虽然速度上比不上哈希表,但是它支持范围查询,这对数据库很重要,所以数据库一般选它为主键索引。
上面我简单举了两个数据结构的例子,那算法呢?很多时候,算法与数据结构是相辅相成的。
就比如树吧,它为什么查询快呢?
它使用的一种分治的算法思想,在数据查询中会使用二分算法不断缩小数据规模,达到一个O(logN) 时间复杂度。
通过树的变形,还催生了堆这一数据结构,堆就是我们常说的优先队列,通过堆这一数据结构的特点,还催生了堆排序这一说法,它在求 topK 的问题上,有着不错的效果。
说了树,那哈希表呢?
哈希表的效果好不好,其实很大程度上取决于它的哈希算法好不好,在基本上所有语言中都内置了哈希表这种数据结构,如Java的HashMap,和一些脚本语言中的字典(Dict),它们都采用哈希表实现,其中Python2.7的字典还因为实现问题,导致过漏洞。
所以,数据结构和算法很重要,虽然我们平常不会直接使用,但是我们接触的很多类库和中间件中都有它们的影子,再从功利的角度讲,进大厂,算法已经是必考了。
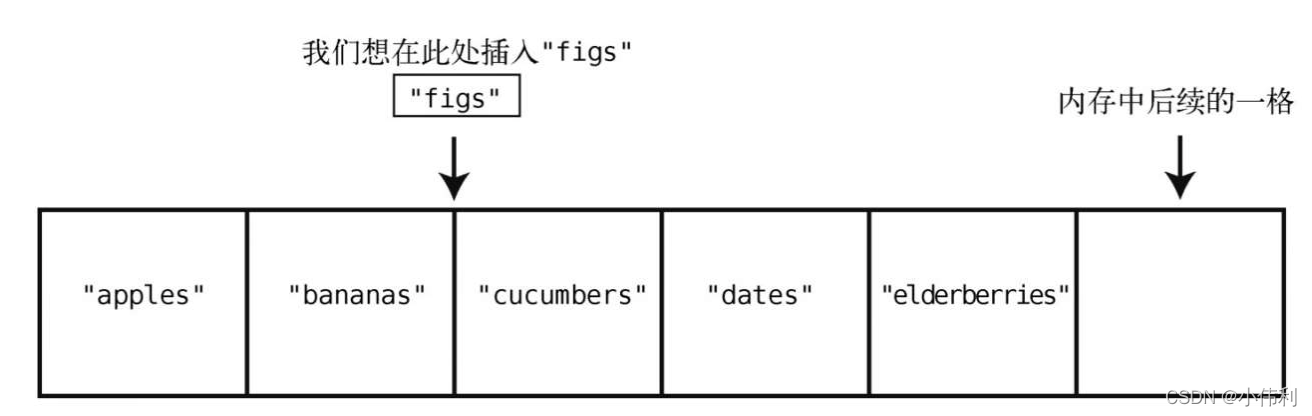
废话不多说,开始吧~
注:在整个数据结构与算法专题中,我都会尽量以实际应用来举例,同时程序实现将会采用Java,相信前端读者们也都能看懂,JS都会了,Java有什么难的呢?
1. 大O 表示法
任何一位开发工程师,哪怕没有科班背景,应该也或多或少的听说过大O 表示法。
这是一种用来衡量时间复杂度与空间复杂度的计数表示,说白了就是衡量算法时间长不长和占用内存多不多,在本文中主要用它来表示时间复杂度,暂不涉及空间复杂度。
比方说,我们要衡量一个算法快不快,那么你的第一反应可能是通过它的运行时间长不长来判断,但是同一段算法在老式奔腾处理器和最新的I9-9700K处理器上,运行时间肯定不同。
所以我们需要一个更精确一点的表示法,就是大O表示法,在大O表示法中,我们通过步数来衡量一个算法的快不快 。
public void test(int[] items) {
}
假设这是一个遍历算法,它需要访问items中的每一个元素,所以如果items的长度为N,那么遍历算法就需要执行N步,它的时间复杂度就是O(N)。
假设这是一个遍历算法,那么有一个输入N,它势必要访问每一个元素,所以它需要执行N步,那么它的时间复杂度就是O(N)。
大O表示法的时间复杂度大致可以分为以下几个级别:
O(1) :常数级别,无论输入多大,它执行的步数都是恒定的,不会因为输入变大而变大,哈希表的查找就是这个级别。
O(N) :线性级别,随着输入变大耗费的步数也正向相关,遍历算法就是这个级别。
O(logN) :对数级别,输入每变大一倍,耗费步骤则增加1,二分查找算法属于这个级别。
O(N²) :平方级别,随着输入的变大所耗费的步数会成倍增加,一般当你的算法使用双层for循环就是这个级别,比如冒泡排序。
此外还有立方级别,就不过多叙述,和平方级别一样,只不过更大。
上面的四种级别除了对数级别其他的应该都很好理解,对数级别涉及到一个数学符号log,它的底数是2,默认省略了。
可以通过一个小例子来理解对数级别:我们有一个排好序的数组,通过二分算法寻找其中一个数字。
假设数组中有16个数字,则需要查找4次,因为2的4次方是4。
假设数组中有2147483647个数字(21亿),则需要查找31次,因为2的31次方是2147483648,这已经是一个相当快的速度了。
所以对数级别你可以理解当规模翻一倍的时候,所需步数只用+1。
关于大O 表示法,我还有一点要强调,它并不像数学一样准确 。
假设你有一个算法每次需要进行2N次的遍历才能执行完,那么它的时间复杂度也是O(N),常数在大O 表示法中会被忽略,因为常数是一定的,不会变化。
再比如O(1),就算你没学过哈希表应该也能明白,不可能有任何算法只执行一个步骤就能查找到某个数字,应该是执行好几步,但是无论是执行5步也好,6步也罢,因为它的步数是恒定的且和输入规模无关,所以它是O(1)。
最后一点,同一段算法在不同输入下可能可能耗费的步数完全不同,所以大O表示法一般取一个一般值来表示,比如某些排序算法在输入逆序和顺序的情况下会呈现完全不同的时间复杂度,一般取耗费更多的那个,这点在排序篇再说吧。
2. 数组
数组 是一种可以快速访问的数据结构,它也是数据结构的基石之一,所有语言都内置支持数组,它在内存中是一块连续的内存地址。
在现代编程语言中,往往使用数组作为一个容器,它可以方便的存储的成百上千个元素,如果没有数组,存储这么多的元素则需要成百上千个引用。
在数组中,每一个数组都有一个地址,同时可以通过数组的下标方便的算出每个元素的内存地址,从而实现快速访问和赋值,所以它通过下标查找的效率是O(1) 级别。
在数组的插入和删除中,如果是在数组尾部插入或删除一个元素则可以直接进行,但如果在其他位置插入或者删除则需要调整其他元素的位置,比如你删除数组的第一个元素之后,需要把后面的所有元素都往前移动一位。
数组还有一个巨大弱点就是当这个数组已经装满的时候,就无法再继续装入元素了。
在高级编程语言中,往往都使用动态数组来解决这个问题,所谓动态数组就是自动会进行数组扩容,当数组容量达到某个临界点的时候,动态数组会开辟一个更大的数组,然后将原来的元素复制过去。
Java中的ArrayList类就是这样做的。
接下来我会简单实现一个动态数组:
public class DiyList<T> {
private Object[] items;
private int size = 0;
public DiyList() {
items = new Object[16];
}
public T get(int index) {
if (index > size) {
throw new NoSuchElementException();
}
return (T) items[index];
}
public boolean add(T item) {
if (Objects.isNull(item)) {
throw new NullPointerException();
}
if (size >= items.length / 2) {
grow();
}
items[size++] = item;
return true;
}
private void grow() {
Object[] newItems = new Object[items.length * 2];
System.arraycopy(items, 0 , newItems, 0 , items.length);
items = newItems;
}
public int size() {
return size;
}
}
由于Java中的范型会有泛型擦除,所以我无法定义一个范型数组,导致只能实现Object数组,在进行get的时候将此元素强转为泛型元素。
在这个例子中,我只实现了基本的get和add方法,动态扩容的最主要方法就是grow方法,它负责了数组的扩容,扩容方式也能简单,建立一个更大的数组,然后把原来的复制过来即可。
动态数组在帮你自动扩容的同时,也带来了复制元素的代价:
当数组需要扩容时,需要进行元素复制。
当删除数组元素时也需要进行元素复制,因为当一删除某一个元素后,数组中间就会有一个空位置,需要把后面的元素都往前挪一格。
所以动态数组比较适合使用下标查询,插入和删除都需要额外的时间消耗和空间消耗。
2.1 课后练习
在上述示例的基础上,补充delete方法,示例已经过自测,可直接copy运行。

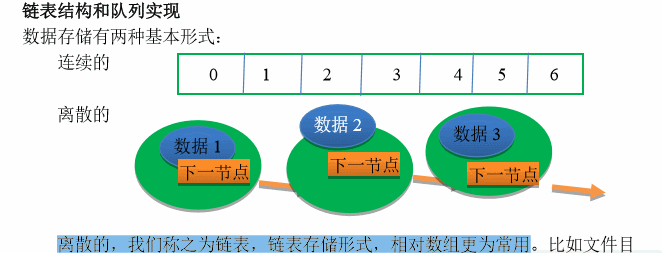
3. 链表
上一节数组是访问元素比较方便,这一节的链表 则是插入与删除更方便。
数组的元素地址是强制连续的,但是链表的元素内存地址可以是不连续的 ,它通过地址引用的方式指向下一个元素的位置,所以链表的数据结构看起来比较像一个串。
链表的代码结构一般是这样的:
public class DiyLinked<T> {
private int size = 0;
private Node item;
private static class Node<T> {
private T item;
private Node next;
public Node(T t) {
item = t;
}
}
}
在Node元素中,除了本身的数据item之外,往往还会持有一个next对象,它用来指向下一个节点的引用。
链表的数据结构也注定了它无法快速的访问某个元素,只能依靠遍历的方式慢慢查找,所以说链表的查询数据是比较慢的,是O(N) 这个级别,但是它在头节点(第一个节点)进行插入和删除比较快,只需要O(1) 就可以了,因为你只需要改变一下第一个元素的引用。
我为什么要特意提到头节点呢, 因为如果你想要在尾节点进行插入和删除,势必需要遍历这个链表,找到最后这个链表节点再进行插入,遍历链表的花费是O(N)。
上面提到的这种只带一有一个next引用的链表叫做单向链表,为了解决尾插的问题,又出现了双向链表。
双向链表,也就是链表中有前后两个指针引用,分别指向前面的元素和后面的元素。
画作逐渐崩坏~
双向链表的代码一般是这样的:
public class DiyLinked<T> {
private int size = 0;
private Node first;
private Node last;
private static class Node<T> {
private T item;
private Node next;
private Node prev;
public Node(T t) {
item = t;
}
}
}
双向链表会同时维护first 和 last 两个节点,所以当你需要尾插的时候,直接通过last节点进行插入或者删除。
Java中的LinkedList就是一个双向链表,实现也很简单,链表是数据结构的另一个基石,很多数据结构都可以在链表的基础上进行变形得来。
3.1 课后练习
实现一个翻转链表,给你一个链表的头节点,将其翻转一遍,返回一个新的链表java数组length属性,新链表的元素顺序相对于原先的来说应当是逆序的。
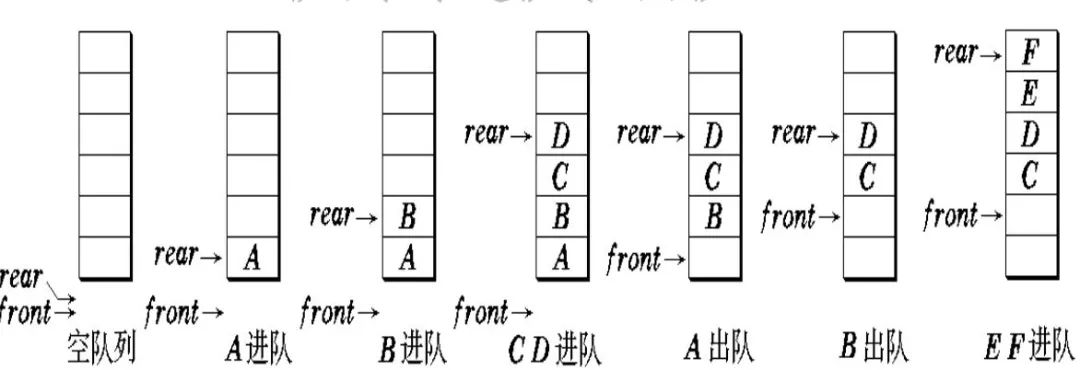
4. 队列
队列 是一个先入先出的数据结构,它在数据结构上可以使用数组或者链表去实现。
队列的特性就像我们日常排队买东西一样,先到先得。
通过图示大家可以看出队列只有两个动作:入队(enqueue)和出队(dequeue),一般呢是在尾部插入,在头部取出。
队列可以分为两种:
有界队列 :能装入的元素有限。
无界队列 :能装入的元素无限,只要内存还有,就能一直装下去。
我将利用数组和链表的特性,分别构造这两种队列。
4.1 数组构造队列
数组在前文中也提到过了,它有两个缺点:
数组是恒定的,想要变大只能使用动态数组。
删除数组元素会迫使其他元素移位。
如果我们想要使用数组构造队列,第一个问题只能通过动态数组来解决,不过实际中很多队列都是恒定的,是不能变大变小的,因为计算机的内存它不是无限的,所以用数组构造有界队列是比较合适的。
第二个问题,在构造队列时要通过复用数组位置来解决,也就是给数组安上两个指针,一个指向尾节点,一个指向头节点,也就是所谓的环形数组。
环形数组队列的两种操作:
出队:出队直接拿first节点的数据即可,然后将first下标元素置为null,并将first指向的下标+1即可。
入队:入队之前需要先判断一下end+1下标上是否有元素,没有才能正常入队,如果有元素则队列已满。
4.2 链表构造队列
使用链表构造队列只需要使用我们上文提到过的双向链表即可,它简直是天生可以作为队列使用,因为它同时维护了头节点和尾节点,而且由于它可以一直链接下去,所以做无界队列正合适。
Java中常用的LinkedList就同时实现了Queue 这个接口,也就是说LinkedList也支持队列操作。
由于链表在上文已经讲过,也很简单,这里我就不实现了~
4.3 课后练习
用数组实现一个有界队列。
5. 栈
栈 ,是一种先入后出/后入先出的数据结构,如果要举一个生活中的例子,我觉得最形象应该就是弹夹了,最先放进去的子弹往往最后被打出。
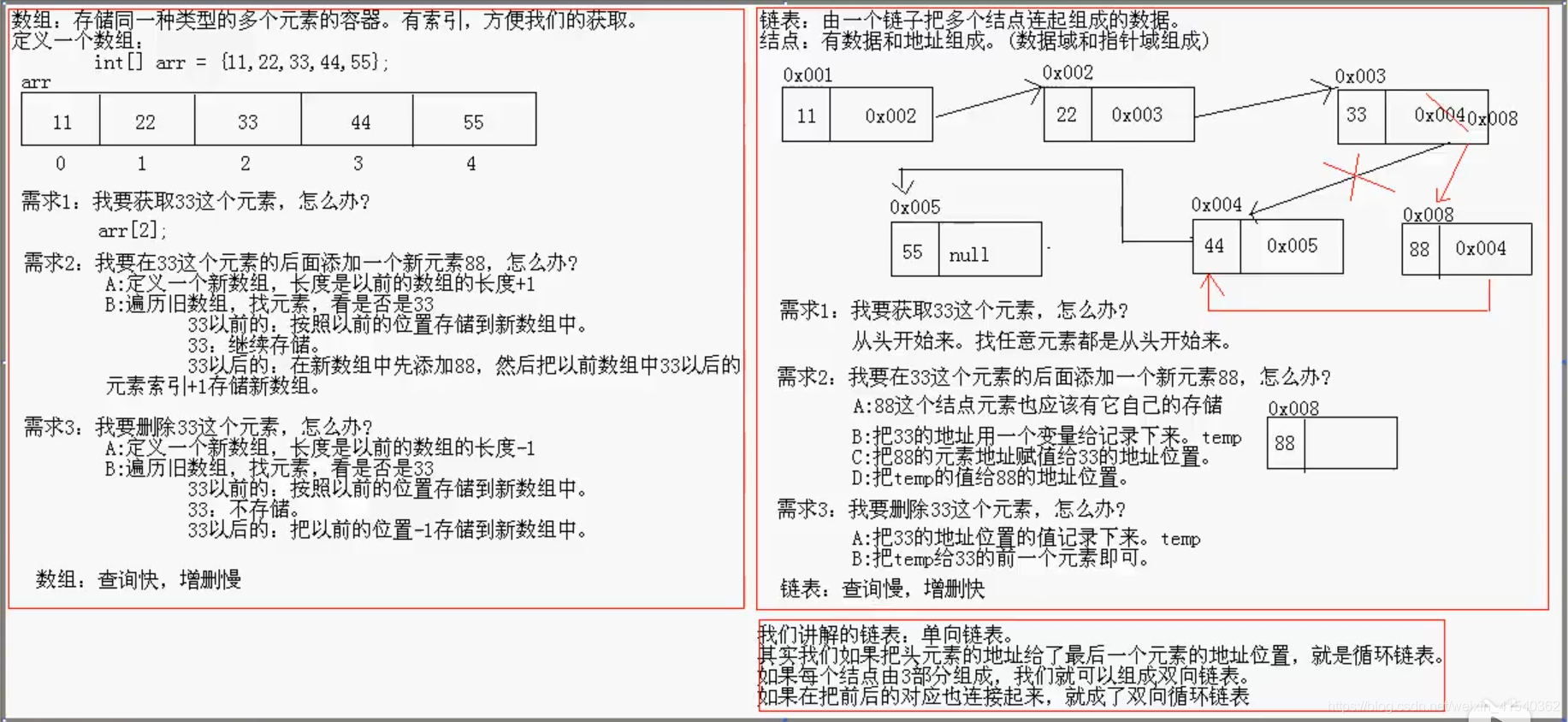
栈,同样也可以使用数组和链表两种方式来构造数据结构,因为其实它会上文中提到过的队列是极其类似的。
在计算机世界中,栈常常被用于程序的调用帧栈,在程序中有时候出现的StackOverFlow异常就是由于程序调用栈用尽了,所以栈一般都是有相对固定的深度,从这点上看用数组构造栈是一个比较好的主意。(栈深往往也被设定的内存影响)
栈使用push插入元素,使用pop读取元素,最后被push的那个元素往往就是第一个被pop的元素。
同样的,栈这个数据结构在Java里面也有,它的名字就叫做Stack,但是它不光具有栈的两个操作,还具有数组的一些可用操作,因为它继承了一个List类,像这样的宽接口设计是类库设计失败的典范,希望大家不要模仿~
5.1 课后练习
用数组实现一个栈。
6. 结语
最后的结语部分,带大家复习一下这四种数据结构:
数组:下标查找快,插入和删除慢。
链表:头尾插入和删除快,查找慢。
队列:尾插和头出,时间复杂度是O(1),非常快。
栈:尾插尾出,时间复杂度是O(1),非常快。
在如今的编程中,更多的是只用到前两种,选用什么容器取决于你的业务属性。
在选用数组时可以预估一下集合规模然后初始化一个比较合适的动态数组,避免多次扩容。
选用链表时可以先问问自己是查询的场景多还是插入的场景多。
使用队列和栈时也可以先了解一下自己使用的类库的底层实现是数组还是链表,当你面对的东西对你来说不再是黑盒时,就可以轻松的作出判断了~
看完本文后,相信读者对这四种基础数据结构的掌握应该已经不在话下了,但是无论是数组做容器还是链表做容器,当我想往容器中间插入的时候都有一次比较大的查找消耗,下一章准备引入新的数据结构:树 。
树的查找插入删除都是O(logN),属于各方面都比较有优势的数据结构,树可以解决在中间插入的效率问题,我会在下一篇里给大家深入讲解一下,包括有些算法书中没讲到的AVL树。
最后,向大家求个点赞,有什么疑问也可以在评论区留言java数组length属性,我都会及时回复。
参考书目 :
算法第四版
数据结构与算法分析
数据结构与算法图解
计算机科学导论
 上一篇
上一篇 








