

java线程池最大线程数-java线程池原理
前言
创建新线程可以通过继承 Thread 类或实现 Runnable 接口来实现,用这两种方式创建的线程在运行后会被虚拟机销毁,并进行垃圾回收,如果线程数量太大,频繁创建和销毁线程会浪费资源,降低效率。线程池的引入很好地解决了上述问题,线程池可以更好的创建、维护、管理线程的生命周期,实现复用,提高资源使用效率,同时也避免了开发者滥用new关键字创建线程的不规范行为。
注意:《阿里巴巴开发手册》明确指出,在实际生产中,线程资源必须通过线程池提供,不允许在应用中显式创建线程。如果不使用线程池,可能会导致系统创建大量同构线程,导致内存消耗或“过度切换”问题。
接下来,
主要讲解线程池核心实现类 ThreadPoolExecutor 核心参数和 Java 中的工作原理,并讲解 Executors 工具类。
ThreadPoolExecutor
ThreadPoolExecutor 是线程池的核心实现类,在 java.util.current 包的 JDK 1.5 中引入,由 Doug Lea 完成。
执行程序接口
Executor 是线程池的顶级接口,在 java.util.并发包中的 JDK 1.5 中引入。
public interface Executor {
// 该接口中只定义了一个Runnable作为入参的execute方法
void execute(Runnable command);
}
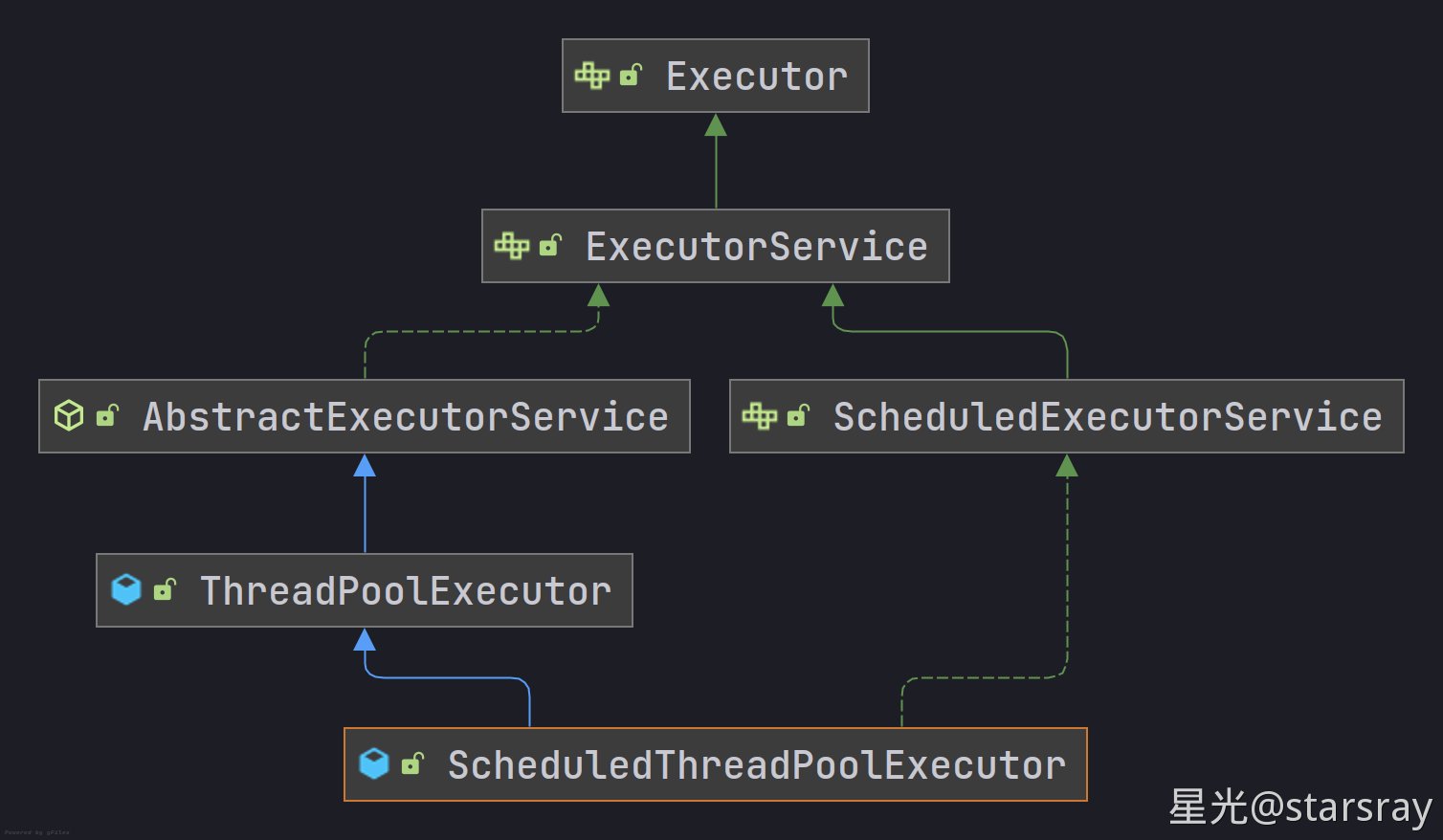
请参阅执行器接口的实现类图
生命周期
线程有生命周期,
线程池也有生命周期,源代码中定义了五种状态。
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
下图显示了线程池状态转换的下图

构造 函数
方法
如何使用 ThreadPoolExecutor 创建线程池,看看它是如何构造的
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
ThreadPoolExecutor 包含 7 个核心参数,参数含义:
核心参数
ThreadPoolExecutor 包含七个核心参数,如果需要自定义线程池,则需要对其中核心的参数有一定程度的了解。
核心池大小
ThreadPoolExecutor 根据构造函数中 corePoolSize 和 maximumPoolSize 设置的边界值自动调整池大小,也可以使用 setCorePoolSize 和 setMaximumPoolSize 动态更改
当一个新的
任务在线程池中提交,并且运行的线程数少于 corePoolSize,即使其他工作线程处于空闲状态,也会创建一个新线程来处理请求。
如果正在运行的线程数多于 corePoolSize 但小于 maxumPoolSize,则仅当队列已满时,才会创建新线程。
如果 corePoolSize 和 maxumPoolSize 相同,则可以创建固定大小的线程池。如果 maximumPoolSize 设置为 Integer.MAX_VALUE,则意味着在资源允许的情况下,允许线程池容纳任意数量的并发任务。
默认情况下,当新任务到达时,即使是核心线程也会开始创建和启动,如果使用非空队列创建线程池池,则可以通过重写 prestartCoreThread 或 prestartAllCoreThreads 方法动态覆盖线程预启动。
在实际开发中,如果需要自定义线程数,可以参考以下公式:

这些参数具有以下含义:
保持活动时间
keepAliveTime 参数用于设置空闲时间。如果池当前有多个 corePoolSize 线程,则冗余线程在空闲时间较长时将被终止,从而在任务数较少时减少线程池资源消耗。如果在给定时间需要处理的任务数增加,则会构造一个新线程。使用 setKeepAliveTime 方法动态更改参数值。
默认情况下,保持活动状态策略仅在超出 corePoolSize 线程时才有效,但方法allowThreadTimeOut 也可用于将此超时策略应用于核心线程,只要 keepAliveTime 值不为零。
工作队列
workQueue 参数用于指定存储已提交任务的队列,任何 BlockingQueue 都可用于传输和保存提交的任务。关于队列大小和线程数之间的关系:
线程池中常用的阻塞队列一般有 SyncQueue、LinkedBlockingQueue、ArrayBlockingQueue,它们都是 BlockingQueue 的实现类,下面简单介绍一下。
同步队列
同步队列不是一个真正的队列,虽然它实现了 BlockingQueue 接口,但它没有存储任务的能力。只需维护一组线程,等待在队列中添加或删除元素,就相当于直接将任务交给执行任务的线程。
如果没有立即可用的线程来运行任务,则尝试对任务进行排队将失败,因此会构造一个新线程。此策略可避免在处理可能具有内部依赖项的请求集时锁定。这种排队方式通常需要无限的最大池大小,以避免拒绝新提交的任务。当任务提交的平均到达速度快于线程处理速度时,就有可能出现无限的线程增长,CachedThreadPool 正式采用了这种形式。
链接阻塞队列
链接阻塞队列
是用链表实现的无界队列,如果使用没有预定义容量的 LinkedBlockingQueue,当所有 corePoolSize 线程都在处理任务时,会导致新任务在队列中等待,并且不会创建超过 corePoolSize 的线程。在这种情况下,最大池大小的值对线程数没有影响。
这种基于队列的处理任务的方式与 SynchronousQueue 处理线程上任务的方式相反。
ArrayBlockingQueue
ArrayBlockingQueue 是通过数组实现的有界队列。当与有限的 maxumPoolSize 一起使用时,有界队列有助于防止资源耗尽,但可能更难调整和控制。使用ArrayBlockingQueue根据应用场景提前估算池和队列的容量,并相互权衡队列大小和最大池大小
螺纹工厂
此参数提供线程池中的线程的创建方式,其中新线程是使用工厂模式 ThreadFactory 创建的,默认情况下,使用 Executors.defaultThreadFactory,这将创建全部位于同一 ThreadGroup 中且具有相同NORM_PRIORITY优先级和非守护程序状态的线程。
您还可以根据
实际场景,可以更改线程名称、线程组、优先级、守护进程状态等,在自定义的情况下,需要注意的是,如果 ThreadFactory 在从 newThread 返回 null 时创建线程失败,执行器会继续,但可能无法执行任何任务。线程应该具有“modifyThread”运行时权限。如果使用池的工作线程或其他线程没有此权限,则服务可能会降级:配置更改可能无法及时生效,并且池的关闭可能会保持可以终止但未完成的状态。
处理器
如果线程池是
饱和且没有足够的线程计数或队列空间来处理提交的任务,或者如果线程池已关闭但仍在处理正在进行的任务,则继续提交的任务将根据线程池的拒绝策略进行处理。
在任一情况下,execute 方法都会调用其 RejectedExecutionHandler 的 rejectedExecution 方法。线程池中提供了四个预定义的处理程序策略:
这些预定义的策略实现 RejectedExecutionHandler 接口,您还可以定义实现类覆盖拒绝策略。
中止策略
查看 AbortPolicy 的源代码,处理程序在拒绝时抛出运行时异常 RejectedExecutionException。
public static class AbortPolicy implements RejectedExecutionHandler {
/**
* Creates an {@code AbortPolicy}.
*/
public AbortPolicy() { }
/**
* Always throws RejectedExecutionException.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
* @throws RejectedExecutionException always
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
丢弃策略
查看源代码,无法执行的任务被简单地丢弃而不进行任何处理。
public static class DiscardPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code DiscardPolicy}.
*/
public DiscardPolicy() { }
/**
* Does nothing, which has the effect of discarding task r.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
丢弃最旧的策略
看着
源代码中java线程池最大线程数,如果未关闭执行程序,则会丢弃工作队列头部的任务并重试执行(可能会再次失败,从而导致此重复。
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code DiscardOldestPolicy} for the given executor.
*/
public DiscardOldestPolicy() { }
/**
* Obtains and ignores the next task that the executor
* would otherwise execute, if one is immediately available,
* and then retries execution of task r, unless the executor
* is shut down, in which case task r is instead discarded.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}
调用者运行策略
查看源代码,此策略调用执行自己正在运行的任务的线程,这也提供了一个简单的反馈控制机制,可以减慢新任务的提交速度。
public static class CallerRunsPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code CallerRunsPolicy}.
*/
public CallerRunsPolicy() { }
/**
* Executes task r in the caller's thread, unless the executor
* has been shut down, in which case the task is discarded.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
挂钩功能
ThreadPoolExecutor 为线程池中的线程提供受保护的可重写钩子函数,以便在初始化或执行任务后执行特殊处理,以及在线程池终止时可以覆盖的终止方法。
之前执行
在线程执行 Runnable 之前调用的方法。此方法由将执行任务 r 的线程调用,可用于重新初始化 ThreadLocals 或执行日志记录。此实现不执行任何操作,但可以在子类中自定义。重要的是要注意java线程池最大线程数,要正确嵌套多个覆盖,子类通常应该在此方法结束时调用super.beforeExecute。查看源代码:
protected void beforeExecute(Thread t, Runnable r) { }
后执行完成
给定的 Runnable 任务时调用的方法,由执行该任务的线程调用。请注意,要正确嵌套多个覆盖,子类通常应在此方法的开头调用 super.afterExecute。查看源代码:
protected void afterExecute(Runnable r, Throwable t) { }
终止
执行程序终止时调用的方法。请注意,在此方法中,子类通常应调用super.terminated。查看源代码:
protected void terminated() { }
核心源代码分析
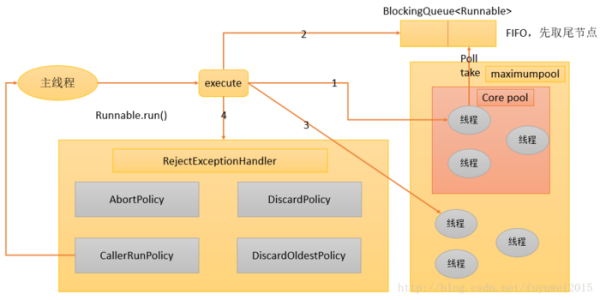
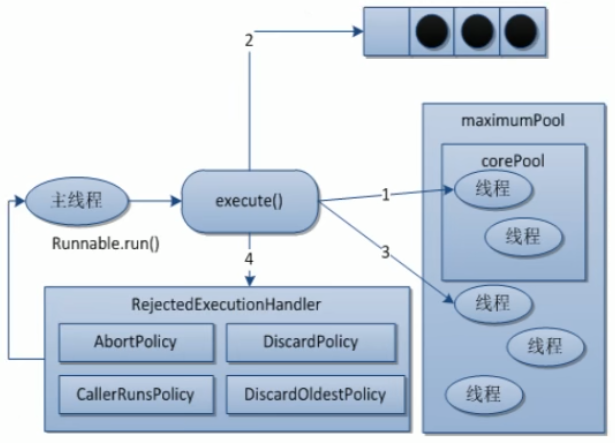
线程池的整体工作流程如下图所示:
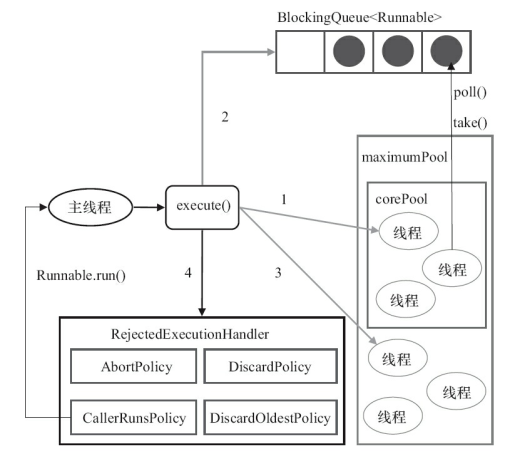
ThreadPoolExecutor 执行方法分为以下四种情况。
如果当前运行的线程少于 corePoolSize,则会创建一个新线程来执行任务(请注意,此步骤需要获取全局锁)。如果正在运行的线程等于或大于 corePoolSize,则该任务将添加到 BlockingQueue。如果无法将任务添加到 BlockingQueue(队列已满),则会创建一个新线程来处理该任务(请注意,此步骤需要获取全局锁)。如果创建新线程将导致当前正在运行的线程超过 maxumPoolSize,则该任务将被拒绝,并且将调用 RejectedExecutionHandler.rejectedExecution() 方法。
ThreadPoolExecutor 采取上述步骤的总体设计思想是在执行 execute() 方法时尽可能避免获取全局锁(这将是一个严重的可伸缩性瓶颈)。在 ThreadPoolExecutor 完成预热(当前运行的线程数大于或等于 corePoolSize)后,几乎所有的 execute() 方法调用都会执行步骤 2,这不需要获取全局锁。
任务单元工作人员
ThreadPoolExecutor 中的核心任务单元由定义两个重要方法的 worker 内部类实现:runWorker 方法和 addWorker 方法。
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
/**
* This class will never be serialized, but we provide a
* serialVersionUID to suppress a javac warning.
*/
private static final long serialVersionUID = 6138294804551838833L;
/** Thread this worker is running in. Null if factory fails. */
final Thread thread;
/** Initial task to run. Possibly null. */
Runnable firstTask;
/** Per-thread task counter */
volatile long completedTasks;
/**
* Creates with given first task and thread from ThreadFactory.
* @param firstTask the first task (null if none)
*/
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
// 这儿是Worker的关键所在,使用了线程工厂创建了一个线程。传入的参数为当前worker
this.thread = getThreadFactory().newThread(this);
}
/** Delegates main run loop to outer runWorker */
public void run() {
runWorker(this);
}
// 省略代码...
}
addWorker 和 runWorker 提交并执行
ThreadPoolExecutor 有两个方法,submit 和 execute,这两种方法的区别是
下面我们简单介绍一下提交和执行的用法
提交方法在执行器服务中定义
接口,抽象类 AbstractExecutorService 在 ExecutorService 中实现了 submit 方法。

public Future submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
/**
* @throws RejectedExecutionException {@inheritDoc}
* @throws NullPointerException {@inheritDoc}
*/
public Future submit(Runnable task, T result) {
if (task == null) throw new NullPointerException();
RunnableFuture ftask = newTaskFor(task, result);
execute(ftask);
return ftask;
}
/**
* @throws RejectedExecutionException {@inheritDoc}
* @throws NullPointerException {@inheritDoc}
*/
public Future submit(Callable task) {
if (task == null) throw new NullPointerException();
RunnableFuture ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
当提交方法传递给 Runnable 对象时,Future 对象的 get 方法是
使用 null 返回值调用,当传入 Callable 对象时,返回 get 自定义的值,主线程块在返回结果之前等待结果返回,然后再执行,然后再返回结果。
class RunnableDemo implements Runnable{
@Override
public void run() {
System.out.println("RunableDemo is execute");
}
}
class CallableDemo implements Callable{
@Override
public String call() throws Exception {
return "Call is Done";
}
}
public class Test {
public static void main(String[] args) throws Exception{
ExecutorService executorService = Executors.newSingleThreadExecutor();
Future call = executorService.submit(new CallableDemo());
System.out.println("Callable'S Result:"+call.get());
Future run = executorService.submit(new RunnableDemo());
System.out.println("Runnable'S Result:"+run.get());
System.out.println("Current Thread:"+Thread.currentThread().getName());
}
}
输出结果
Callable'S Result:Call is Done
RunableDemo is execute
Runnable'S Result:null
Current Thread:main

submit 方法处理任务执行结果的成败,或执行过程中抛出的异常,暂停其他任务的处理,使用执行及时处理处理程序操作过程中发生的异常情况。
class CallableDemo implements Callable{
@Override
public String call() throws Exception {
return "Call is Done";
}
}
public class Test {
public static void main(String[] args) {
ExecutorService executorService = Executors.newSingleThreadExecutor();
Future call = executorService.submit(new CallableDemo());
try {
call.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
我们可以根据具体的业务场景来考虑可能的异常,实现 Callable 的接口抛出,然后由 ThreadPoolExecutor 调用方处理,以提高多线程场景下的容错率。
执行程序类
Executors 是 Executor 框架的一个实用程序类,它提供了几种创建线程池的方法,以及线程池中默认配置(如线程工厂)的处理,然后描述了几种常用的创建线程池的方法。
newSingleThreadExecutor
** 单线程执行器
使用 Executors.newSingleThreadExecutor() 创建,查看源代码
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue()));
}
哪里:
因此,newSingleThreadExecutor 可用于处理任务量不大的场景,但不希望频繁创建和销毁需要与虚拟机处于同一周期的场景。
newFixedThreadPool
FixedThreadPool 是使用 Executors.newFixedThreadPool() 创建的,用于查看源代码
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
}
哪里:
FixedThreadPool 和 SingleThreadExecutor 一样,如果 nThreads 的值设置得太小,在任务太多的场景下,可能会因为线程太少而造成 OOM,导致任务堆积在队列中,导致 OOM,相对的好处是可以多线程,处理效率得到一定程度的提高。
newCachedThreadPool
CachedThreadPool 是使用 Executors.newCachedThreadPool() 创建的,用于查看源代码
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
}
哪里:
在 CachedThreadPool 中,如果主线程提交任务的速度比 maximumPool 中的线程快,则将继续创建新线程,最终导致创建过多线程并耗尽 CPU 和内存资源。忽略 CPU 和内存消耗,在一定程度上 CachedThreadPool 可以快速解决短期并发的问题,因为核心线程数为 0 并且设置了生存时间,这些临时打开的线程会在任务处理后被回收。
执行者是
提供是为了屏蔽线程池,避免过多的参数设置影响易用性,实际上这些参数并不需要一一设置,Executors 也是在源代码中推荐使用的方式,但需要熟悉它们各自的特性。
总结
执行器框架主要由三部分组成,任务,
任务执行器、执行结果、ThreadPoolExecutor 和 ScheduledThreadPoolExecutor 的设计思想也是将这三个关键元素解耦,将任务的提交和执行分开。
参考:__Java并发Programming__Concurrent Programming.com 的艺术:并发编程网络 – ifeve.com |让没有难学的技术
先介绍一下自己,小编13年从交通大学毕业,曾经待过小公司,去了华为OPPO等大厂,18年进入阿里,一直到现在。我知道,大多数初中级Java工程师,如果想提升自己的技能,往往需要探索自己的成长或者报课,但对于培训机构近万元的学费来说,实在是压力很大。自学效率低下且耗时长,很容易碰到天花板和技术停止。因此,我收集了一本《Java开发完整学习资料》送给大家,初衷也很简单,就是帮助想自学但不知道从哪里入手的朋友,同时减轻大家的负担。添加下面的名片以获取全套学习材料
 上一篇
上一篇 








