

java 屏蔽敏感词-Javaweb网站敏感词过滤调研结果写出来的参考书
发布时间:2023-06-29 16:14 浏览次数:次 作者:佚名
现在基本上所有的网站都需要设置敏感词过滤,似乎已经成了一个网站的标配,如果你的网站没有,或者你没有做相应的处理,那么小心相关部门请你喝茶哦。
最近在调研Java web网站的敏感词过滤的实现,网上找了相关资料,经过我的验证,把我的调研结果写出来,供大家参考。
一、敏感词过滤工具类
把敏感词词库内容加载到ArrayList集合中,通过双层循环,查找与敏感词列表相匹配的字符串,如果找到以*号替换,最终得到替换后的字符串。
此种方式匹配度较高,匹配速度良好。
初始化敏感词库:
//初始化敏感词库
public void InitializationWork()
{
replaceAll = new StringBuilder(replceSize);
for(int x=0;x < replceSize;x++)
{
replaceAll.append(replceStr);
}
//加载词库
arrayList = new ArrayList();
InputStreamReader read = null;
BufferedReader bufferedReader = null;
try {
read = new InputStreamReader(SensitiveWord.class.getClassLoader().getResourceAsStream(fileName),encoding);
bufferedReader = new BufferedReader(read);
for(String txt = null;(txt = bufferedReader.readLine()) != null;){
if(!arrayList.contains(txt))
arrayList.add(txt);
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
if(null != bufferedReader)
bufferedReader.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if(null != read)
read.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
过滤敏感词信息:
public String filterInfo(String str)
{
sensitiveWordSet = new HashSet();
sensitiveWordList= new ArrayList<>();
StringBuilder buffer = new StringBuilder(str);
HashMap hash = new HashMap(arrayList.size());
String temp;
for(int x = 0; x < arrayList.size();x++)
{
temp = arrayList.get(x);
int findIndexSize = 0;
for(int start = -1;(start=buffer.indexOf(temp,findIndexSize)) > -1;)
{
//System.out.println("###replace="+temp);
findIndexSize = start+temp.length();//从已找到的后面开始找
Integer mapStart = hash.get(start);//起始位置
if(mapStart == null || (mapStart != null && findIndexSize > mapStart))//满足1个,即可更新map
{
hash.put(start, findIndexSize);
//System.out.println("###敏感词:"+buffer.substring(start, findIndexSize));
}
}
}
Collection values = hash.keySet();
for(Integer startIndex : values)
{
Integer endIndex = hash.get(startIndex);
//获取敏感词,并加入列表,用来统计数量
String sensitive = buffer.substring(startIndex, endIndex);
//System.out.println("###敏感词:"+sensitive);
if (!sensitive.contains("*")) {//添加敏感词到集合
sensitiveWordSet.add(sensitive);
sensitiveWordList.add(sensitive);
}
buffer.replace(startIndex, endIndex, replaceAll.substring(0,endIndex-startIndex));
}
hash.clear();
return buffer.toString();
}
下载地址:SensitiveWord

链接: 密码: qmcw (如果失效,请使用文末地址下载)
二、Java关键词过滤
这个方式采用的是正则表达式匹配,速度上比第一种稍慢,匹配度良好。
主要代码:
// 从words.properties初始化正则表达式字符串
private static void initPattern() {
StringBuffer patternBuffer = new StringBuffer();
try {
//words.properties
InputStream in = KeyWordFilter.class.getClassLoader().getResourceAsStream("keywords.properties");
Properties property = new Properties();
property.load(in);
Enumeration enu = property.propertyNames();
patternBuffer.append("(");
while (enu.hasMoreElements()) {
String scontent = (String) enu.nextElement();
patternBuffer.append(scontent + "|");
//System.out.println(scontent);
keywordsCount ++;
}
patternBuffer.deleteCharAt(patternBuffer.length() - 1);
patternBuffer.append(")");
//System.out.println(patternBuffer);
// unix换成UTF-8
// pattern = Pattern.compile(new
// String(patternBuf.toString().getBytes("ISO-8859-1"), "UTF-8"));
// win下换成gb2312
// pattern = Pattern.compile(new String(patternBuf.toString()
// .getBytes("ISO-8859-1"), "gb2312"));
// 装换编码
pattern = Pattern.compile(patternBuffer.toString());
} catch (IOException ioEx) {
ioEx.printStackTrace();
}
}
private static String doFilter(String str) {
Matcher m = pattern.matcher(str);
// while (m.find()) {// 查找符合pattern的字符串
// System.out.println("The result is here :" + m.group());
// }
// 选择替换方式,这里以* 号代替
str = m.replaceAll("*");
return str;
}

下载地址:KeyWordFilter
链接: 密码: xi24 (如果失效,请使用文末地址下载)
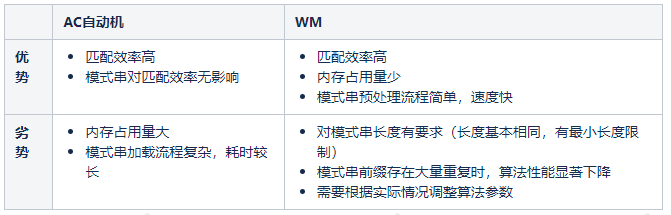
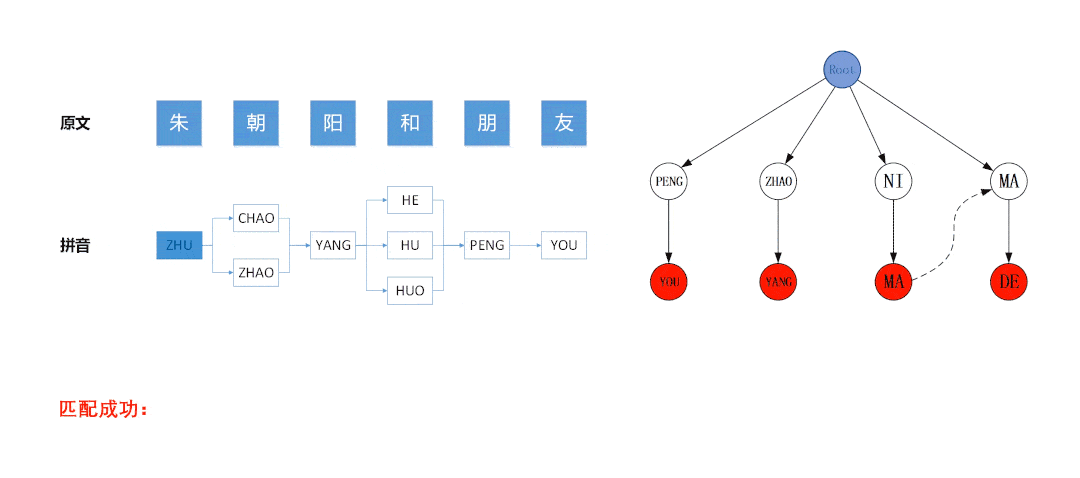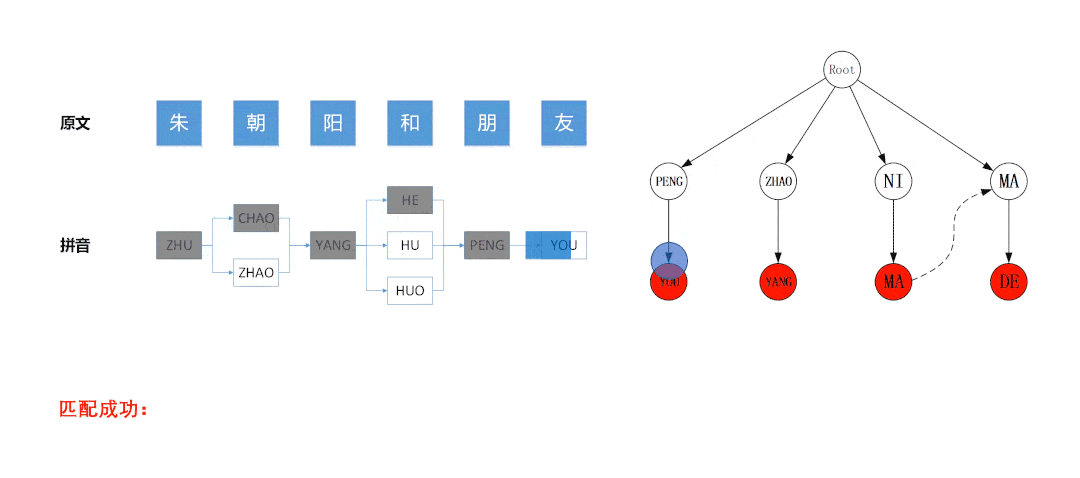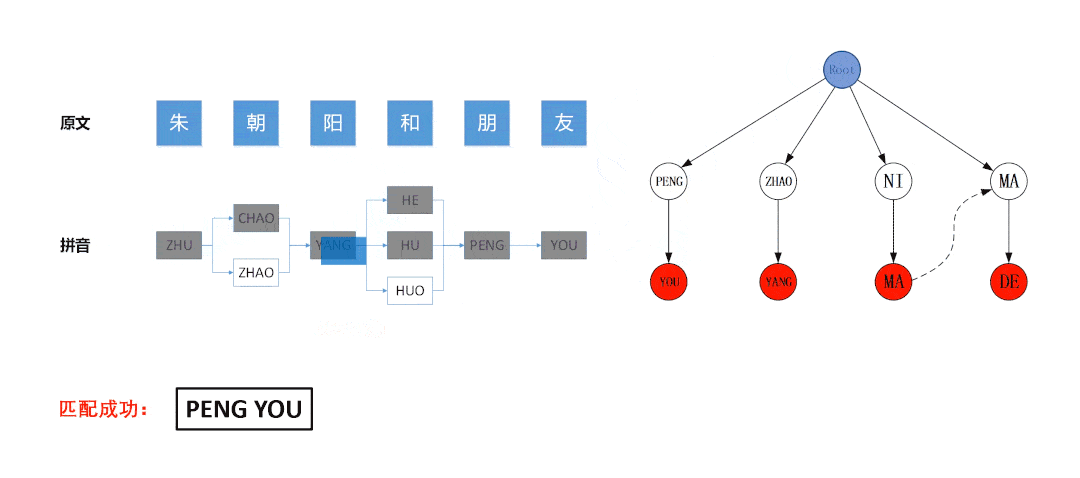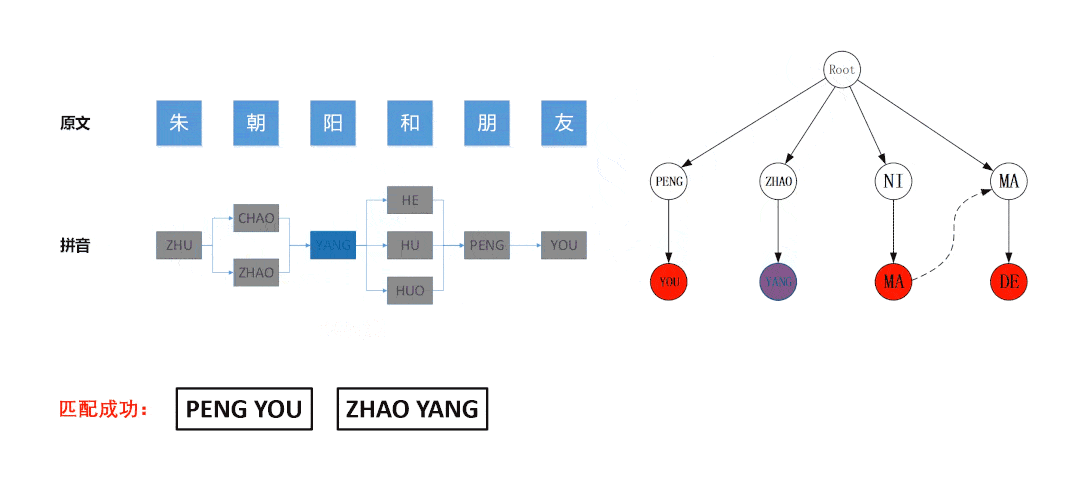
三、DFA算法进行过滤
这种方式听起来高大上,采用DFA算法,这个算法个人不太懂,经测试发现,匹配度不行,速度良好。或许可以改良,还请大神进行改良。
主要有两个文件:SensitivewordFilter.java 和 SensitiveWordInit.java
主要代码:
public int CheckSensitiveWord(String txt,int beginIndex,int matchType){
boolean flag = false; //敏感词结束标识位:用于敏感词只有1位的情况
int matchFlag = 0; //匹配标识数默认为0
char word = 0;
Map nowMap = sensitiveWordMap;
for(int i = beginIndex; i < txt.length() ; i++){
word = txt.charAt(i);
nowMap = (Map) nowMap.get(word); //获取指定key
if(nowMap != null){ //存在,则判断是否为最后一个
matchFlag++; //找到相应key,匹配标识+1
if("1".equals(nowMap.get("isEnd"))){ //如果为最后一个匹配规则,结束循环,返回匹配标识数
flag = true; //结束标志位为true
if(SensitivewordFilter.minMatchTYpe == matchType){ //最小规则,直接返回,最大规则还需继续查找
break;
}
}
}
else{ //不存在,直接返回
break;
}
}
if(matchFlag < 2 || !flag){ //长度必须大于等于1,为词
matchFlag = 0;
}
return matchFlag;
}
下载地址:SensitivewordFilter
链接: 密码: mc1x (如果失效,请使用文末地址下载)
四、多叉树查找算法
这个方式采用了多叉树查找算法,至于这个算法是怎么回事,大家可以去查看数据结构相关内容。提供了jar包,直接调用进行过滤。
经测试,这个方法匹配度良好,速度稍慢。
调用方式:
//敏感词过滤
FilteredResult result = WordFilterUtil.filterText(str, '*');
//获取过滤后的内容
System.out.println("替换后的字符串为:\n"+result.getFilteredContent());
//获取原始字符串
System.out.println("原始字符串为:\n"+result.getOriginalContent());
//获取替换的敏感词
System.out.println("替换的敏感词为:\n"+result.getBadWords());
下载地址:WordFilterUtil
链接: 密码: 5t2h (如果失效java 屏蔽敏感词java 屏蔽敏感词,请使用文末地址下载)
 上一篇
上一篇 







