

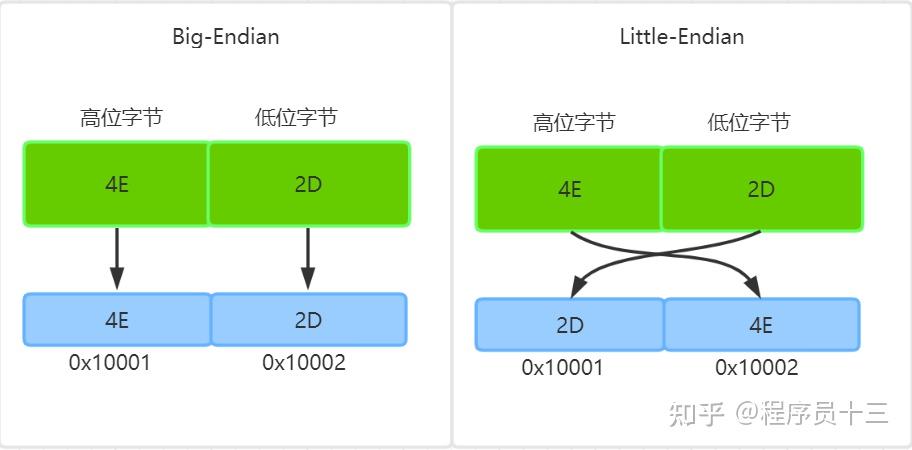
java整数转换成二进制-java 转换进制
这篇《Java基础知识总结》是JavaGuide上阅读量最大的文章。 由于本人已经重构改进,修复了很多小问题,请大家再次同步到公众号!
文章内容比较多,公众号不适合长文阅读。 阅读原文的朋友可以点击在线阅读,体验会更好(附目录)。
整篇文章目录如下:
基本概念和常识 Java语言有哪些特点? 简单易学; 面向对象(封装、继承、多态); 因此,多线程编程必须调用操作系统的多线程函数,而Java语言提供了多线程支持); 可靠性; 安全; 支持网络编程,非常方便(Java语言的诞生本身就是为了简化网络编程,所以Java语言不仅支持网络编程而且非常方便); 编译与解释并存;
更正(参见:issue#544):从C++11(2011年)开始,C++引入了多线程库,std::thread和std::async可用于在windows、linux和苹果系统 。 参考链接:
JVM 对比 JDK 对比 JREJVM
Java 虚拟机 (JVM) 是运行 Java 字节码的虚拟机。 JVM 对不同的系统(Windows、Linux、macOS)有特定的实现,目的是使用相同的字节码,它们都会给出相同的结果。
什么是字节码? 使用字节码有什么好处?
在Java中,JVM能够理解的代码称为字节码(即扩展名为.class的文件),它不面向任何特定的处理器,只面向虚拟机。 Java语言通过字节码在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言的可移植性。 因此,Java程序在运行时效率更高,而且由于字节码不特定于特定机器,Java程序无需重新编译即可在不同操作系统的计算机上运行。
Java程序从源代码到运行一般有以下三个步骤:
Java程序运行过程
需要特别注意的是.class->machine code这一步。 在这一步中,JVM类加载器首先加载字节码文件,然后通过解释器逐行解释执行。 这种方法的执行速度会比较慢。 而且有些方法和代码块经常需要被调用(也就是所谓的热代码),所以后来引入了JIT编译器,JIT属于运行时编译。 当JIT编译器完成第一次编译后,会保存字节码对应的机器码,下次可以直接使用。 而且我们知道,机器码的运行效率肯定是高于Java解释器的。 这也解释了为什么我们常说Java是一门编译和解释并存的语言。
HotSpot采用惰性求值(Lazy Evaluation)的方法。 根据第 28 定律,只有一小部分代码(热代码)会消耗大部分系统资源,而这就是 JIT 需要编译的部分。 JVM会根据每次执行代码的时间来收集信息,并相应地进行一些优化,因此执行的次数越多,速度就越快。 JDK 9引入了一种新的编译模式AOT(Ahead of Time Compilation),直接将字节码编译成机器码,从而避免了JIT预热等方面的开销。 JDK支持分层编译和AOT协同使用。 但是AOT编译器的编译质量肯定不如JIT编译器。
总结:
Java 虚拟机 (JVM) 是运行 Java 字节码的虚拟机。 JVM 对不同的系统(Windows、Linux、macOS)有特定的实现,目的是使用相同的字节码,它们都会给出相同的结果。 不同系统的字节码和JVM实现是Java语言“一次编译,到处运行”的关键。
JDK 和 JRE
JDK是Java Development Kit的缩写,是一个全功能的Java SDK。 它拥有 JRE 所拥有的一切,外加编译器 (javac) 以及 javadoc 和 jdb 等工具。 它能够创建和编译程序。
JRE 是 Java 运行时环境。 它是运行已编译的 Java 程序所需的一切的集合,包括 Java 虚拟机 (JVM)、Java 类库、java 命令和其他基本组件。 但是,它不能用于创建新程序。
如果你只是想运行一个Java程序,那么你只需要安装JRE。 如果你需要做一些Java编程工作,那么你需要安装JDK。 然而,这不是绝对的。 有时,即使您不打算在计算机上进行任何 Java 开发,您仍然需要安装 JDK。 例如,如果您使用 JSP 部署 Web 应用程序,从技术上讲,您只是在应用程序服务器中运行 Java 程序。 那么为什么需要 JDK? 因为应用服务器将JSP转为Java servlet,需要使用JDK编译servlet。
为什么说Java语言“边编译边解释”?
高级程序设计语言根据程序的执行方式分为编译型和解释型两种。 简单来说,编译型语言就是针对特定的操作系统,编译器将源代码翻译成平台一次可以执行的机器码; 解释型语言是指解释器将源程序逐行解释为特定平台的机器代码。 代码并立即执行。 比如你想看英文名著,可以找英文翻译帮你读。 有两种选择。 你可以等翻译者把整篇英文经典(也就是源代码)翻译成中文,然后再去读,或者请翻译者翻译一段,你在旁边读一段,慢慢读完书。
Java语言兼有编译型语言和解释型语言的特点,因为Java程序需要先编译后解释。 Java 编写的程序首先需要编译生成字节码(\*.class 文件),这个字节码必须由Java 解释器解释执行。 因此,我们可以认为Java语言的编译和解释并存。
Oracle JDK 与 OpenJDK 的比较
可能很多人和我一样,在看这道题之前都没有接触和使用过OpenJDK。 那么 Oracle 和 OpenJDK 之间有什么主要区别吗? 下面我通过我搜集到的一些资料来回答这个很多人忽略的问题。
对于 Java 7,没有什么重要的。 OpenJDK 项目主要基于 Sun 捐赠的 HotSpot 源代码。 此外,OpenJDK 被选为 Java 7 的参考实现,由 Oracle 工程师维护。 关于JVM、JDK、JRE和OpenJDK的区别,Oracle 2012年的一篇博文有更详细的回答:
问:OpenJDK 存储库中的源代码与用于构建 Oracle 的 JDK 的代码有何区别?
答:非常接近——我们的 Oracle JDK 发布构建过程建立在 OpenJDK 7 之上,仅添加了一些内容,例如部署代码,其中包括 Oracle 的 Java 插件和 Java WebStart 的实现,以及一些闭源组件,例如图形光栅器,一些开源第 3 方组件(如 Rhino),以及其他文档或第 3 方字体等点点滴滴。 展望未来,我们的目标是开源 Oracle JDK 的所有部分,除了我们认为具有商业功能的部分。
总结:
Oracle JDK 大约每 6 个月发布一次主要版本,而 OpenJDK 大约每三个月发布一次。 但它不是固定的,我认为了解它没有用。 详情请见: 。 OpenJDK是一个参考模型,是完全开源的,而Oracle JDK是OpenJDK的一个实现,不是完全开源的; Oracle JDK 比 OpenJDK 更稳定。 OpenJDK 和 Oracle JDK 的代码几乎相同,但 Oracle JDK 有更多的类和一些错误修复。 所以如果你想开发企业/商业软件,我建议你选择Oracle JDK,因为它经过全面测试并且稳定。 在某些情况下,有人提到在使用 OpenJDK 时可能会遇到很多应用程序崩溃的问题,但是只需切换到 Oracle JDK 就可以解决问题; Oracle JDK 相比 OpenJDK 在响应能力和 JVM 性能方面提供了更好的性能; Oracle JDK 不对即将发布的版本提供长期支持,用户必须每次更新到最新支持的版本以获取最新版本; Oracle JDK 使用 BCL/OTN 协议获得许可,而 OpenJDK 使用 GPL v2 许可获得许可。
展开它:
相关阅读:《Oracle JDK与OpenJDK的区别》
Java 和 C++ 有什么区别?
我知道很多人没有学过C++,但是面试官就是喜欢拿我们的Java和C++来比较! 决不! ! ! 即使你没有学过 C++,也要记住它!
import java 和 javax 有什么区别?
一开始JavaAPI需要的包都是java开头的包,javax只是用来扩展API包。 然而,随着时间的推移,javax 逐渐扩展成为 Java API 的一个组成部分。 但是,将扩展从 javax 包移动到 java 包确实很麻烦,最终会破坏一堆现有代码。 因此,最终决定将 javax 包作为标准 API 的一部分。
所以,实际上 java 和 javax 之间没有区别。 都是一个名字。
基本语法字符常量和字符串常量有什么区别?
格式:字符常量是用单引号括起来的一个字符,字符串常量是用双引号括起来的0个或几个字符
含义:一个字符常量相当于一个整数值(ASCII值),可以参与表达式运算; 一个字符串常量表示一个地址值(字符串在内存中存储的位置)
内存大小:字符常量只占用2个字节; 字符串常量占几个字节(注:Java中char占两个字节),
字符封装类Character有一个成员常量Character.SIZE,值为16,单位为bits。 这个值除以8后(1byte=8bits),可以得到2个字节
Java 编程思想,第四版:第 2.2.2 节
笔记
Java中的注解分为三种:
单行注释
多行注释
文档注释。
我们写代码的时候,如果代码量比较少,我们或者其他团队成员很容易看懂代码,但是当项目结构变得复杂的时候,我们就需要使用注释了。 注释是不会被执行的(编译器在编译代码之前会把代码中的所有注释都清除掉,字节码中不保留注释),是我们程序员给自己写的,注释是你的代码指令,可以帮助人阅读代码的人可以很快理解代码之间的逻辑关系。 因此,在编写程序时随意添加注释是一个非常好的习惯。
《Clean Code》一书明确指出:
代码注释不是越详细越好。 其实好的代码本身就是注释。 我们应该尽量规范和美化我们的代码,减少不必要的注释。
如果编程语言表达力足够,就不用注释了,尽量通过代码来解释。
例如:
摆脱下面复杂的评论,只创建一个函数来做评论所说的同样的事情
// check to see if the employee is eligible for full benefits
if ((employee.flags & HOURLY_FLAG) && (employee.age > 65))
应该替换为
if (employee.isEligibleForFullBenefits())
标识符和关键字有什么区别?
我们在写程序的时候,需要给程序、类、变量、方法等等命名很多,所以就有了标识符。 简单地说,标识符就是一个名称。 但是有一些标识符,Java语言赋予了它们特殊的含义,只能在特定的地方使用。 这个特殊标识符是一个关键字。 因此,关键字是具有特殊含义的标识符。 比如在我们日常生活中,“派出所”这个名字已经被赋予了特殊的含义,所以如果你开店,店名就不能叫“派出所”,“派出所”是我们日常生活的关键词。
Java中常用的关键字有哪些? 访问控制privateprotectedpublic
类、方法和变量修饰符
抽象的
班级
延伸
最终的
工具
界面
本国的
新的
静止的
严格的fp
同步的
短暂的

易挥发的
程序控制
休息
继续
返回
做
尽管
如果
别的
为了
实例
转变
案件
默认
错误处理
尝试
抓住
扔
投掷
最后
包裹相关
进口
包裹
基本型
布尔值
字节
字符
双倍的
漂浮
整数
长的
短的
无效的
真的
错误的
变量引用
极好的
这
空白
保留字
去
常数
递增和递减运算符
在编写代码的过程中,一个常见的情况是一个整型变量需要加1或减1。Java为这种表达式提供了一种特殊的运算符,称为自增运算符(++)和递减运算符 (--)。
++ 和 -- 运算符可以放在变量之前或之后。 当运算符放在变量(前缀)之前时,先自增/自减,再赋值; 当运算符放在变量(后缀)之后时,先赋值,再自增/自减。 比如当b = ++a时,先自增(自增1),再赋值(赋值给b); 当b = a++时,先赋值(赋值给b),然后自增(自增1)。 即++a输出a+1的值,a++输出a的值。 口头禅是:“先加/减符号,在最后加/减符号”。
继续、中断和返回之间有什么区别?
在循环结构中,当不满足循环条件或循环次数达到要求时,循环正常结束。 但是,有时可能需要在循环过程中出现某种情况时提前终止循环,这需要使用以下关键字:
continue:指跳出当前循环,继续下一个循环。 break:指跳出整个循环体,继续执行循环下面的语句。
return用于跳出方法,结束方法的运行。 return 一般有两种用法:
返回; : 直接用return结束方法执行,用于没有返回值函数返回值的方法; : 返回一个特定的值,用于有返回值函数的方法 你了解Java泛型吗? 什么是类型擦除? 说说常用的通配符?
Java泛型(generics)是JDK 5引入的新特性,泛型提供了一种编译时类型安全检测机制,允许程序员在编译时检测非法类型。 泛型的本质是参数化类型,也就是说将被操作的数据类型指定为参数。
Java的泛型是伪泛型,因为在Java编译时所有的泛型信息都会被擦除,也就是通常所说的类型擦除。
List list = new ArrayList<>();
list.add(12);
//这里直接添加会报错
list.add("a");
Class clazz = list.getClass();
Method add = clazz.getDeclaredMethod("add", Object.class);
//但是通过反射添加,是可以的
add.invoke(list, "kl");
System.out.println(list);
泛型的使用一般有三种方式:泛型类、泛型接口和泛型方法。
1.通用类:
//此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型
//在实例化泛型类时,必须指定T的具体类型
public class Generic<T>{
private T key;
public Generic(T key) {
this.key = key;
}
public T getKey(){
return key;
}
}
如何实例化泛型类:
Generic genericInteger = new Generic(123456);
2.通用接口:
public interface Generator<T> {
public T method();
}
在不指定类型的情况下实现通用接口:
class GeneratorImpl<T> implements Generator<T>{
@Override
public T method() {
return null;
}
}
实现通用接口,指定类型:
class GeneratorImpl<T> implements Generator<String>{
@Override
public String method() {
return "hello";
}
}
3.通用方法:
public static < E > void printArray( E[] inputArray )
{
for ( E element : inputArray ){
System.out.printf( "%s ", element );
}
System.out.println();
}
使用:
// 创建不同类型数组:Integer, Double 和 Character
Integer[] intArray = { 1, 2, 3 };
String[] stringArray = { "Hello", "World" };
printArray( intArray );
printArray( stringArray );
常用的通配符有:T、E、K、V、?
== 和 equals 的区别
对于原始数据类型,== 比较值。 对于引用数据类型,==比较对象的内存地址。
因为Java只按值传递,对于==,无论是比较基本数据类型还是引用数据类型的变量,比较的本质都是值,而引用类型变量中存储的值是对象的地址。
equals()函数不能用来判断基本数据类型的变量,只能用来判断两个对象是否相等。 equals()方法存在于所有类的直接或间接父类Object类中。
对象类 equals() 方法:
public boolean equals(Object obj) {
return (this == obj);
}
equals() 方法有两个用例:
例如:
public class test1 {
public static void main(String[] args) {
String a = new String("ab"); // a 为一个引用
String b = new String("ab"); // b为另一个引用,对象的内容一样
String aa = "ab"; // 放在常量池中
String bb = "ab"; // 从常量池中查找
if (aa == bb) // true
System.out.println("aa==bb");
if (a == b) // false,非同一对象
System.out.println("a==b");
if (a.equals(b)) // true
System.out.println("aEQb");
if (42 == 42.0) { // true
System.out.println("true");
}
}
}
阐明:
字符串类 equals() 方法:
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
hashCode() 和 equals()
面试官可能会问你:“你有没有重写hashcode和equals,为什么重写equals的时候还要重写hashCode方法?”
1)hashCode()介绍:
hashCode()的作用是获取哈希码,也就是哈希码; 它实际上返回一个整数。 这个哈希码的作用是确定对象在哈希表中的索引位置。 hashCode()是在JDK的Object类中定义的,也就是说Java中的任何类都包含hashCode()函数。 另外需要注意的是,Object的hashcode方法是一个本地方法,是用c语言或者c++实现的。 该方法通常用于将对象的内存地址转换为整数,然后返回。
public native int hashCode();
哈希表存储的是键值对(key-value),其特点是可以根据“键”快速检索出对应的“值”。 这是使用哈希码的地方! (可以快速找到想要的对象)
2)为什么会有hashCode?
下面以“HashSet如何检查重复”为例来解释为什么会有hashCode?
当你向HashSet中添加一个对象时,HashSet会先计算该对象的hashcode值,以确定添加该对象的位置,同时还会与其他已添加对象的hashcode值进行比较。 如果没有匹配的hashcode,HashSet就会假定对象没有重复出现。 但是如果找到具有相同 hashcode 值的对象,则会调用 equals() 方法来检查具有相同 hashcode 的对象是否真的相同。 如果两者相同,则 HashSet 不会让它的连接操作成功。 如果不同,它将被重新散列到另一个位置。 (摘自我的 Java 入门书“Head First Java”第二版)。 这样一来,我们大大减少了equals的个数,从而大大提高了执行速度。
3)为什么重写equals时一定要重写hashCode方法?
如果两个对象相等,哈希码也必须相同。 两个对象相等,对这两个对象调用 equals 方法返回 true。 但是,具有相同 hashcode 值的两个对象不一定相等。 因此,如果重写了equals方法,那么hashCode方法也必须重写。
hashCode() 的默认行为是为堆上的对象生成唯一值。 如果 hashCode() 没有被覆盖,这个类的两个对象无论如何都不会相等(即使两个对象指向相同的数据)
4)为什么两个对象的hashcode值相同,却不一定相等?
这里解释一下小伙伴的问题。 以下内容摘自《Head First Java》。
因为 hashCode() 使用的哈希算法可能只是导致多个对象返回相同的哈希值。 hash算法越差越容易发生碰撞,但这也和数据值字段分布的特点有关(所谓碰撞就是不同的对象得到相同的hashCode。
刚才我们也提到了HashSet。 如果 HashSet 在比较时有多个对象的 hashcode 相同,它会使用 equals() 来判断它们是否真的相同。 也就是说,hashcode只是用来降低搜索成本的。
有关 hashcode() 和 equals() 的更多信息,请参见:关于 Java hashCode() 和 equals() 的几个问题的回答
Java中的基本数据类型有哪些? 对应的包装类型是什么? 它们占用多少字节?
Java中有8种基本数据类型,分别是:
6 种数值类型:byte、short、int、long、float、double1 字符类型:char1 boolean 类型:boolean。
这8种基本数据类型的默认值和占用空间如下:
基本类型位字节默认值
整数
32
4个
短的
16
2个
长的
64
8个
0升
字节
8个
1个
字符
16
2个
'u0000'
漂浮
32
4个
0f
双倍的
64
8个
0d
布尔值
1个
错误的
另外,对于boolean,官方文档也没有明确定义,具体要看JVM厂商的具体实现。 逻辑上理解为占用1bit,但在实际操作中,会考虑计算机的高效存储因素。
注意:
Java中使用long类型数据时,必须在值后加上L,否则会被解析为整型。 char a = 'h'char:单引号,String a = "hello":双引号。
这八种基本类型都有对应的封装类:Byte、Short、Integer、Long、Float、Double、Character、Boolean。
包装类型如果没有赋值就是Null,而原始类型有默认值不是Null。
另外这个问题建议也可以先从JVM层面分析。
基本数据类型直接存放在Java虚拟机栈中的局部变量表中,而封装类型属于对象类型,我们知道对象实例都存在于堆中。 与对象类型相比,原始数据类型占用的空间非常小。
《深入理解Java虚拟机》:局部变量表主要存放基本数据类型**(boolean、byte、char、short、int、float、long、double)**、对象引用(引用类型、它与对象本身不同的是,它可能是一个指向对象起始地址的引用指针,也可能指向代表该对象的句柄或与该对象相关的其他位置)。
自动装箱和拆箱
例子:
Integer i = 10; //装箱
int n = i; //拆箱
上面两行代码对应的字节码是:
L1
LINENUMBER 8 L1
ALOAD 0
BIPUSH 10
INVOKESTATIC java/lang/Integer.valueOf (I)Ljava/lang/Integer;
PUTFIELD AutoBoxTest.i : Ljava/lang/Integer;
L2
LINENUMBER 9 L2
ALOAD 0
ALOAD 0
GETFIELD AutoBoxTest.i : Ljava/lang/Integer;
INVOKEVIRTUAL java/lang/Integer.intValue ()I
PUTFIELD AutoBoxTest.n : I
RETURN
从字节码中我们发现,装箱实际上是调用了包装类的valueOf()方法,而拆箱实际上是调用了xxxValue()方法。
所以,
8种基本类型的包装类和常量池
大多数 Java 基本类型的包装类都实现了常量池技术。 Byte, Short, Integer, Long 这四个包装类默认创建对应类型的值为[-128, 127]的缓存数据,Character创建值为[0,127]范围内的缓存数据,Boolean直接返回对或错。
整数缓存源代码:
/**
*此方法将始终缓存-128 到 127(包括端点)范围内的值,并可以缓存此范围之外的其他值。
*/
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
}

字符缓存源代码:
public static Character valueOf(char c) {
if (c <= 127) { // must cache
return CharacterCache.cache[(int)c];
}
return new Character(c);
}
private static class CharacterCache {
private CharacterCache(){}
static final Character cache[] = new Character[127 + 1];
static {
for (int i = 0; i < cache.length; i++)
cache[i] = new Character((char)i);
}
}
布尔缓存源代码:
public static Boolean valueOf(boolean b) {
return (b ? TRUE : FALSE);
}
如果超过了相应的范围,仍然会创建一个新的对象。 缓存范围的大小只是性能和资源之间的权衡。
这两种浮点数的包装类Float和Double都没有实现常量池技术。
Integer i1 = 33;
Integer i2 = 33;
System.out.println(i1 == i2);// 输出 true
Float i11 = 333f;
Float i22 = 333f;
System.out.println(i11 == i22);// 输出 false
Double i3 = 1.2;
Double i4 = 1.2;
System.out.println(i3 == i4);// 输出 false
让我们来看看这个问题。 以下代码的输出是真还是假?
Integer i1 = 40;
Integer i2 = new Integer(40);
System.out.println(i1==i2);
Integer i1=40 这行代码会被拆箱,也就是说这行代码相当于Integer i1=Integer.valueOf(40)。 所以i1直接使用了常量池中的对象。 而 Integer i1 = new Integer(40) 会直接创建一个新对象。
因此,答案是错误的。 你做对了吗?
请记住:整数包装类对象之间的所有值比较都使用 equals 方法进行比较。
方法(函数) 方法的返回值是什么?
方法的返回值是指我们得到的方法体中的代码执行的结果! (前提是该方法可能会产生结果)。 返回值的作用是接收结果,以便进行其他操作!
方法的种类有哪些?
1.无参数无返回值的方法
// 无参数无返回值的方法(如果方法没有返回值,不能不写,必须写void,表示没有返回值)
public void f1() {
System.out.println("无参数无返回值的方法");
}
2.有参数无返回值的方法
/**
* 有参数无返回值的方法
* 参数列表由零组到多组“参数类型+形参名”组合而成,多组参数之间以英文逗号(,)隔开,形参类型和形参名之间以英文空格隔开
*/
public void f2(int a, String b, int c) {
System.out.println(a + "-->" + b + "-->" + c);
}
3.有返回值无参数的方法
// 有返回值无参数的方法(返回值可以是任意的类型,在函数里面必须有return关键字返回对应的类型)
public int f3() {
System.out.println("有返回值无参数的方法");
return 2;
}
4.有返回值和参数的方法
// 有返回值有参数的方法
public int f4(int a, int b) {
return a * b;
}
5. return在没有返回值的方法中的特殊使用
// return在无返回值方法的特殊使用
public void f5(int a) {
if (a > 10) {
return;//表示结束所在方法 (f5方法)的执行,下方的输出语句不会执行
}
System.out.println(a);
}
为什么在静态方法中调用非静态成员是非法的?
这个需要结合JVM的相关知识。 静态方法属于类,类加载时会分配内存,可以直接通过类名访问。 非静态成员属于实例对象,只有在对象被实例化后才存在,然后通过类的实例对象访问。 当类的非静态成员不存在时,静态成员已经存在。 这时候调用内存中不存在的非静态成员就是非法操作。
静态方法与实例方法有何不同?
外部调用静态方法时,可以使用“类名.方法名”或“对象名.方法名”的方法。 实例方法只有后一种方法。 换句话说,调用静态方法不需要创建对象。
静态方法访问本类成员时,只允许访问静态成员(即静态成员变量和静态方法),不允许访问实例成员变量和实例方法; 实例方法没有这样的限制。
为什么Java中只有值传递?
首先,让我们回顾一些用于将参数传递给方法(或函数)的编程语言术语。
传值调用是指方法接收调用者提供的值,传引用调用是指方法接收调用者提供的变量地址。 方法可以修改与传引用对应的变量值,但不能修改与传值调用对应的变量值。 它用于描述各种编程语言(不仅仅是Java)中的方法参数传递方法。
Java 编程语言始终使用按值调用。 换句话说,该方法获得了所有参数值的副本,即该方法不能修改传递给它的任何参数变量的内容。
这里有3个例子来说明
示例 1
public static void main(String[] args) {
int num1 = 10;
int num2 = 20;
swap(num1, num2);
System.out.println("num1 = " + num1);
System.out.println("num2 = " + num2);
}
public static void swap(int a, int b) {
int temp = a;
a = b;
b = temp;
System.out.println("a = " + a);
System.out.println("b = " + b);
}
结果:
a = 20
b = 10
num1 = 10
num2 = 20
解析:
示例 1
在swap方法中,交换a和b的值java整数转换成二进制,不影响num1和num2。 因为a和b中的值只是从num1和num2中复制过来的。 也就是说a和b相当于num1和num2的副本,无论副本内容如何修改,都不会影响到原件本身。
通过上面的例子,我们已经知道方法不能修改基本数据类型的参数,但是当使用对象引用作为参数时就不一样了,请看example2。
示例 2
public static void main(String[] args) {
int[] arr = { 1, 2, 3, 4, 5 };
System.out.println(arr[0]);
change(arr);
System.out.println(arr[0]);
}
public static void change(int[] array) {
// 将数组的第一个元素变为0
array[0] = 0;
}
结果:
1
0
解析:
示例 2
array被初始化,arr的副本也是一个对象的引用,也就是说array和arr指向同一个数组对象。 因此,对引用对象的外部更改将反映在相应的对象上。
我们已经在示例 2 中看到,实现一个改变对象参数状态的方法并不是一项艰巨的任务。 原因很简单,方法得到了对象引用的副本,而对象引用和其他副本同时引用同一个对象。
许多编程语言(特别是 C++ 和 Pascal)提供两种传递参数的方式:按值调用和按引用调用。 一些程序员(甚至本书的作者)认为 Java 编程语言对对象使用按引用调用。 其实,这种认识是错误的。 由于这种误解具有一定的普遍性,下面举一个反例对这个问题进行详细阐述。
示例 3
public class Test {
public static void main(String[] args) {
// TODO Auto-generated method stub
Student s1 = new Student("小张");
Student s2 = new Student("小李");
Test.swap(s1, s2);
System.out.println("s1:" + s1.getName());
System.out.println("s2:" + s2.getName());
}
public static void swap(Student x, Student y) {
Student temp = x;
x = y;
y = temp;
System.out.println("x:" + x.getName());
System.out.println("y:" + y.getName());
}
}
结果:
x:小李
y:小张
s1:小张
s2:小李
解析:
交换前:
交换后:
从上面两张图可以清楚的看出,该方法并没有改变变量s1和s2中存储的对象引用。 swap 方法的参数 x 和 y 被初始化为两个对象引用的副本,该方法交换两个副本
总结
Java 编程语言不使用对对象的引用调用。 实际上,对象引用是按值传递的。
下面总结一下Java中方法参数的用法:
参考:
《Java核心技术第一卷》基础知识第十版第四章4.5小节
重载和覆盖的区别
重载就是同一个方法可以根据不同的输入数据做不同的处理。
重写是指当子类从父类继承相同的方法,输入的数据相同,但要做出与父类不同的响应时,就得重写父类的方法
超载
Occurring in the same class (or between the parent class and the subclass), the method name must be the same, the parameter type, number and order are different, and the method return value and access modifier can be different.

The following is an introduction to the concept of overloading in "Java Core Technology":
To sum up: Overloading means that multiple methods with the same name in the same class perform different logical processing according to different parameters.
改写
Rewriting occurs at runtime, and the subclass rewrites the implementation process of the access-allowed methods of the parent class.
The return value type, method name, and parameter list must be the same, the scope of the thrown exception is less than or equal to the parent class, and the scope of the access modifier is greater than or equal to the parent class. If the parent class method access modifier is private/final/static, the subclass cannot override the method, but the method modified by static can be declared again.Constructors cannot be overridden
To sum up: Rewriting is the remodeling of parent class methods by subclasses. The external appearance cannot be changed, but the internal logic can be changed.
The heart-warming Guide brother will come to a chart to summarize at the end!
Difference Overloaded Method Overridden Method
Range of occurrence
the same class
Subclass
parameter list
must be modified
must not be modified
return type
Can be modified
The return value type of the subclass method should be smaller or equal to the return value type of the parent method
异常
Can be modified
The exception class thrown by the subclass method declaration should be smaller or equal to the exception class thrown by the parent class method declaration;
access modifier
Can be modified
Must not be more restrictive (restrictions can be lowered)
Occurrence stage
编译时间
运行
The rewriting of the method should follow the "two same, two small and one big" (the following is excerpted from "Crazy Java Lectures", issue#892):
⭐️ I need to explain more about the return value type of rewriting here. The above statement is not clear and accurate: if the return type of the method is void and the basic data type, the return value cannot be modified when rewriting. But if the return value of the method is a reference type, it can return a subclass of the reference type when rewriting.
public class Hero {
public String name() {
return "超级英雄";
}
}
public class SuperMan extends Hero{
@Override
public String name() {
return "超人";
}
public Hero hero() {
return new Hero();
}
}
public class SuperSuperMan extends SuperMan {
public String name() {
return "超级超级英雄";
}
@Override
public SuperMan hero() {
return new SuperMan();
}
}
Deep copy vs shallow copy Shallow copy: Pass by value for basic data types, copy by reference for reference data types, this is shallow copy. Deep copy: transfer the value of the basic data type, and create a new object for the reference data type, and copy its content. This is a deep copy.
The difference between deep and shallow copyJava object-oriented object-oriented and process-oriented
See issue: Process-oriented: Process-oriented performance is higher than object-oriented? ?
This is not the root cause. Process-oriented also needs to allocate memory and calculate memory offsets. The main reason for Java's poor performance is not because it is an object-oriented language, but because Java is a semi-compiled language, and the final execution code cannot be directly executed. Binary machine code executed by the CPU.
Most of the process-oriented languages are directly compiled into machine codes and executed on the computer, and the performance of other process-oriented scripting languages is not necessarily better than Java.
What is the difference between member variables and local variables? From the grammatical point of view, member variables belong to the class, while local variables are variables defined in code blocks or methods or parameters of methods; member variables can be modified by public, private, static and other modifiers, while local variables Cannot be modified by access control modifiers and static; however, member variables and local variables can be modified by final. From the storage method of variables in memory, if the member variable is modified with static, then the member variable belongs to the class; if it is not modified with static, the member variable belongs to the instance. While objects exist in heap memory, local variables exist in stack memory. From the perspective of the lifetime of variables in memory, member variables are part of the object and exist with the creation of the object, while local variables disappear automatically with the method call. From the perspective of whether the variable has a default value, if the member variable is not initialized, it will be automatically assigned the default value of the type (exception: the member variable modified by final must also be explicitly assigned), and the local variable will not be assigned automatically. What operator is used to create an object? How is an object entity different from an object reference?
new 运算符,new 创建对象实例(对象实例在堆内存中),对象引用指向对象实例(对象引用存放在栈内存中)。
一个对象引用可以指向0 个或1 个对象(一根绳子可以不系气球,也可以系一个气球);一个对象可以有n 个引用指向它(可以用n 条绳子系住一个气球)。
对象的相等与指向他们的引用相等,两者有什么不同?
对象的相等,比的是内存中存放的内容是否相等。而引用相等,比较的是他们指向的内存地址是否相等。
一个类的构造方法的作用是什么?若一个类没有声明构造方法,该程序能正确执行吗?为什么?
构造方法主要作用是完成对类对象的初始化工作。
如果一个类没有声明构造方法,也可以执行!因为一个类即使没有声明构造方法也会有默认的不带参数的构造方法。如果我们自己添加了类的构造方法(无论是否有参),Java 就不会再添加默认的无参数的构造方法了,这时候,就不能直接new 一个对象而不传递参数了,所以我们一直在不知不觉地使用构造方法,这也是为什么我们在创建对象的时候后面要加一个括号(因为要调用无参的构造方法)。如果我们重载了有参的构造方法,记得都要把无参的构造方法也写出来(无论是否用到),因为这可以帮助我们在创建对象的时候少踩坑。
构造方法有哪些特点?是否可被override?
特征:
名字与类名相同。没有返回值,但不能用void 声明构造函数。生成类的对象时自动执行,无需调用。
构造方法不能被override(重写),但是可以overload(重载),所以你可以看到一个类中有多个构造函数的情况。
面向对象三大特征封装
封装是指把一个对象的状态信息(也就是属性)隐藏在对象内部,不允许外部对象直接访问对象的内部信息。但是可以提供一些可以被外界访问的方法来操作属性。就好像我们看不到挂在墙上的空调的内部的零件信息(也就是属性),但是可以通过遥控器(方法)来控制空调。如果属性不想被外界访问,我们大可不必提供方法给外界访问。但是如果一个类没有提供给外界访问的方法,那么这个类也没有什么意义了。就好像如果没有空调遥控器,那么我们就无法操控空凋制冷,空调本身就没有意义了(当然现在还有很多其他方法,这里只是为了举例子)。
public class Student {
private int id;//id属性私有化
private String name;//name属性私有化
//获取id的方法
public int getId() {
return id;
}
//设置id的方法
public void setId(int id) {
this.id = id;
}
//获取name的方法
public String getName() {
return name;
}
//设置name的方法
public void setName(String name) {
this.name = name;
}
}
继承
不同类型的对象,相互之间经常有一定数量的共同点。例如,小明同学、小红同学、小李同学,都共享学生的特性(班级、学号等)。同时,每一个对象还定义了额外的特性使得他们与众不同。例如小明的数学比较好,小红的性格惹人喜爱;小李的力气比较大。继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。通过使用继承,可以快速地创建新的类,可以提高代码的重用,程序的可维护性,节省大量创建新类的时间,提高我们的开发效率。
关于继承如下3 点请记住:
子类拥有父类对象所有的属性和方法(包括私有属性和私有方法),但是父类中的私有属性和方法子类是无法访问,只是拥有。子类可以拥有自己属性和方法,即子类可以对父类进行扩展。子类可以用自己的方式实现父类的方法。(以后介绍)。多态
多态,顾名思义,表示一个对象具有多种的状态。具体表现为父类的引用指向子类的实例。
多态的特点:
String StringBuffer 和StringBuilder 的区别是什么? String 为什么是不可变的?
可变性
简单的来说:String 类中使用final 关键字修饰字符数组来保存字符串,private final char value[],所以String 对象是不可变的。
补充(来自issue 675):在Java 9 之后,String 、StringBuilder 与StringBuffer 的实现改用byte 数组存储字符串private final byte[] value
而StringBuilder 与StringBuffer 都继承自AbstractStringBuilder 类,在AbstractStringBuilder 中也是使用字符数组保存字符串char[]value 但是没有用final 关键字修饰,所以这两种对象都是可变的。
StringBuilder 与StringBuffer 的构造方法都是调用父类构造方法也就是AbstractStringBuilder 实现的,大家可以自行查阅源码。
AbstractStringBuilder.java
abstract class AbstractStringBuilder implements Appendable, CharSequence {
/**
* The value is used for character storage.
*/
char[] value;
/**
* The count is the number of characters used.
*/
int count;
AbstractStringBuilder(int capacity) {
value = new char[capacity];
}}
线程安全性
String 中的对象是不可变的,也就可以理解为常量,线程安全。AbstractStringBuilder 是StringBuilder 与StringBuffer 的公共父类,定义了一些字符串的基本操作,如expandCapacity、append、insert、indexOf 等公共方法。StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder 并没有对方法进行加同步锁,所以是非线程安全的。
表现
每次对String 类型进行改变的时候,都会生成一个新的String 对象,然后将指针指向新的String 对象。StringBuffer 每次都会对StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用StringBuilder 相比使用StringBuffer 仅能获得10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
对于三者使用的总结:
操作少量的数据: 适用String单线程操作字符串缓冲区下操作大量数据: 适用StringBuilder多线程操作字符串缓冲区下操作大量数据: 适用StringBufferObject 类的常见方法总结
Object 类是一个特殊的类,是所有类的父类。它主要提供了以下11 个方法:
public final native Class getClass()//native方法,用于返回当前运行时对象的Class对象,使用了final关键字修饰,故不允许子类重写。
public native int hashCode() //native方法,用于返回对象的哈希码,主要使用在哈希表中,比如JDK中的HashMap。
public boolean equals(Object obj)//用于比较2个对象的内存地址是否相等,String类对该方法进行了重写用户比较字符串的值是否相等。
protected native Object clone() throws CloneNotSupportedException//naitive方法,用于创建并返回当前对象的一份拷贝。一般情况下,对于任何对象 x,表达式 x.clone() != x 为true,x.clone().getClass() == x.getClass() 为true。Object本身没有实现Cloneable接口,所以不重写clone方法并且进行调用的话会发生CloneNotSupportedException异常。
public String toString()//返回类的名字@实例的哈希码的16进制的字符串。建议Object所有的子类都重写这个方法。
public final native void notify()//native方法,并且不能重写。唤醒一个在此对象监视器上等待的线程(监视器相当于就是锁的概念)。如果有多个线程在等待只会任意唤醒一个。
public final native void notifyAll()//native方法,并且不能重写。跟notify一样,唯一的区别就是会唤醒在此对象监视器上等待的所有线程,而不是一个线程。
public final native void wait(long timeout) throws InterruptedException//native方法,并且不能重写。暂停线程的执行。注意:sleep方法没有释放锁,而wait方法释放了锁 。timeout是等待时间。
public final void wait(long timeout, int nanos) throws InterruptedException//多了nanos参数,这个参数表示额外时间(以毫微秒为单位,范围是 0-999999)。 所以超时的时间还需要加上nanos毫秒。
public final void wait() throws InterruptedException//跟之前的2个wait方法一样,只不过该方法一直等待,没有超时时间这个概念
protected void finalize() throws Throwable { }//实例被垃圾回收器回收的时候触发的操作
反射何为反射?
如果说大家研究过框架的底层原理或者咱们自己写过框架的话,一定对反射这个概念不陌生。

反射之所以被称为框架的灵魂,主要是因为它赋予了我们在运行时分析类以及执行类中方法的能力。
通过反射你可以获取任意一个类的所有属性和方法,你还可以调用这些方法和属性。
反射机制优缺点反射的应用场景
像咱们平时大部分时候都是在写业务代码,很少会接触到直接使用反射机制的场景。
但是,这并不代表反射没有用。相反,正是因为反射,你才能这么轻松地使用各种框架。像Spring/Spring Boot、MyBatis 等等框架中都大量使用了反射机制。
这些框架中也大量使用了动态代理,而动态代理的实现也依赖反射。
比如下面是通过JDK 实现动态代理的示例代码,其中就使用了反射类Method 来调用指定的方法。
public class DebugInvocationHandler implements InvocationHandler {
/**
* 代理类中的真实对象
*/
private final Object target;
public DebugInvocationHandler(Object target) {
this.target = target;
}
public Object invoke(Object proxy, Method method, Object[] args) throws InvocationTargetException, IllegalAccessException {
System.out.println("before method " + method.getName());
Object result = method.invoke(target, args);
System.out.println("after method " + method.getName());
return result;
}
}
另外java整数转换成二进制,像Java 中的一大利器注解的实现也用到了反射。
为什么你使用Spring 的时候,一个@Component注解就声明了一个类为Spring Bean 呢?为什么你通过一个@Value注解就读取到配置文件中的值呢?究竟是怎么起作用的呢?
这些都是因为你可以基于反射分析类,然后获取到类/属性/方法/方法的参数上的注解。你获取到注解之后,就可以做进一步的处理。
异常Java 异常类层次结构图
图片来自:
图片来自:
在Java 中,所有的异常都有一个共同的祖先java.lang 包中的Throwable 类。Throwable 类有两个重要的子类Exception(异常)和Error(错误)。Exception 能被程序本身处理(try-catch), Error 是无法处理的(只能尽量避免)。
Exception 和Error 二者都是Java 异常处理的重要子类,各自都包含大量子类。
受检查异常
Java 代码在编译过程中,如果受检查异常没有被catch/throw 处理的话,就没办法通过编译。比如下面这段IO 操作的代码。
check-exception
除了RuntimeException及其子类以外,其他的Exception类及其子类都属于受检查异常。常见的受检查异常有:IO 相关的异常、ClassNotFoundException 、SQLException...。
不受检查异常
Java 代码在编译过程中,我们即使不处理不受检查异常也可以正常通过编译。
RuntimeException 及其子类都统称为非受检查异常,例如:NullPointerException、NumberFormatException(字符串转换为数字)、ArrayIndexOutOfBoundsException(数组越界)、ClassCastException(类型转换错误)、ArithmeticException(算术错误)等。
Throwable 类常用方法try-catch-finally
在以下3 种特殊情况下,finally 块不会被执行:
在try 或finally块中用了System.exit(int)退出程序。但是,如果System.exit(int) 在异常语句之后,finally 还是会被执行程序所在的线程死亡。关闭CPU。
下面这部分内容来自issue:。
注意: 当try 语句和finally 语句中都有return 语句时,在方法返回之前,finally 语句的内容将被执行,并且finally 语句的返回值将会覆盖原始的返回值。如下:
public class Test {
public static int f(int value) {
try {
return value * value;
} finally {
if (value == 2) {
return 0;
}
}
}
}
如果调用f(2),返回值将是0,因为finally 语句的返回值覆盖了try 语句块的返回值。
使用try-with-resources 来代替try-catch-finally适用范围(资源的定义): 任何实现java.lang.AutoCloseable或者java.io.Closeable 的对象关闭资源和finally 块的执行顺序: 在try-with-resources 语句中,任何catch 或finally 块在声明的资源关闭后运行
《Effecitve Java》中明确指出:
面对必须要关闭的资源,我们总是应该优先使用try-with-resources 而不是try-finally。随之产生的代码更简短,更清晰,产生的异常对我们也更有用。try-with-resources语句让我们更容易编写必须要关闭的资源的代码,若采用try-finally则几乎做不到这点。
Java 中类似于InputStream、OutputStream 、Scanner 、PrintWriter等的资源都需要我们调用close()方法来手动关闭,一般情况下我们都是通过try-catch-finally语句来实现这个需求,如下:
//读取文本文件的内容
Scanner scanner = null;
try {
scanner = new Scanner(new File("D://read.txt"));
while (scanner.hasNext()) {
System.out.println(scanner.nextLine());
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
if (scanner != null) {
scanner.close();
}
}
使用Java 7 之后的try-with-resources 语句改造上面的代码:
try (Scanner scanner = new Scanner(new File("test.txt"))) {
while (scanner.hasNext()) {
System.out.println(scanner.nextLine());
}
} catch (FileNotFoundException fnfe) {
fnfe.printStackTrace();
}
当然多个资源需要关闭的时候,使用try-with-resources 实现起来也非常简单,如果你还是用try-catch-finally可能会带来很多问题。
通过使用分号分隔,可以在try-with-resources块中声明多个资源。
try (BufferedInputStream bin = new BufferedInputStream(new FileInputStream(new File("test.txt")));
BufferedOutputStream bout = new BufferedOutputStream(new FileOutputStream(new File("out.txt")))) {
int b;
while ((b = bin.read()) != -1) {
bout.write(b);
}
}
catch (IOException e) {
e.printStackTrace();
}
I\O 流什么是序列化?什么是反序列化?
如果我们需要持久化Java 对象比如将Java 对象保存在文件中,或者在网络传输Java 对象,这些场景都需要用到序列化。
简单来说:
对于Java 这种面向对象编程语言来说,我们序列化的都是对象(Object)也就是实例化后的类(Class),但是在C++这种半面向对象的语言中,struct(结构体)定义的是数据结构类型,而class 对应的是对象类型。
维基百科是如是介绍序列化的:
序列化(serialization)在计算机科学的数据处理中,是指将数据结构或对象状态转换成可取用格式(例如存成文件,存于缓冲,或经由网络中发送),以留待后续在相同或另一台计算机环境中,能恢复原先状态的过程。依照序列化格式重新获取字节的结果时,可以利用它来产生与原始对象相同语义的副本。对于许多对象,像是使用大量引用的复杂对象,这种序列化重建的过程并不容易。面向对象中的对象序列化,并不概括之前原始对象所关系的函数。这种过程也称为对象编组(marshalling)。从一系列字节提取数据结构的反向操作,是反序列化(也称为解编组、deserialization、unmarshalling)。
综上:序列化的主要目的是通过网络传输对象或者说是将对象存储到文件系统、数据库、内存中。
Java 序列化中如果有些字段不想进行序列化,怎么办?
对于不想进行序列化的变量,使用transient关键字修饰。
transient 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被transient 修饰的变量值不会被持久化和恢复。transient 只能修饰变量,不能修饰类和方法。
获取用键盘输入常用的两种方法
方法1:通过Scanner
Scanner input = new Scanner(System.in);
String s = input.nextLine();
input.close();
方法2:通过BufferedReader
BufferedReader input = new BufferedReader(new InputStreamReader(System.in));
String s = input.readLine();
Java 中IO 流分为几种?
Java Io 流共涉及40 多个类,这些类看上去很杂乱,但实际上很有规则,而且彼此之间存在非常紧密的联系, Java I0 流的40 多个类都是从如下4 个抽象类基类中派生出来的。
按操作方式分类结构图:
IO-操作方式分类
按操作对象分类结构图:
IO-操作对象分类既然有了字节流,为什么还要有字符流?
问题本质想问:不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么I/O 流操作要分为字节流操作和字符流操作呢?
回答:字符流是由Java 虚拟机将字节转换得到的,问题就出在这个过程还算是非常耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。
4. 参考
欢迎准备面试的朋友加入我的星球,。目前星球已经更新3个原创小册:《Java面试进阶指北》、《从零开始写一个RPC 框架》、《程序员副业赚钱之路》。累计帮助520+位球友提供了免费的简历修改服务,回答了500+个问题,产出了1300+个主题。
推荐:
推荐:
推荐:
我是Guide哥,拥抱开源,喜欢烹饪。 Github 接近10w 点赞的开源项目JavaGuide 的作者。未来几年,希望持续完善JavaGuide,争取能够帮助更多学习Java 的小伙伴! mutual encouragement!凎!原创不易,欢迎点赞分享。咱们下期再会!
 上一篇
上一篇 








