

java 延迟队列-java 多线程处理队列
前言
延迟消息(定时消息)是指在分布式异步消息场景中,生产者发送一条消息,希望在指定的延迟时间或指定的时间点被消费者消费,而不是立即被消费。
延迟消息适用于广泛的业务场景。 在分布式系统环境中,延迟消息的功能一般会下沉到中间件层。 通常,此功能内置于 MQ 中或内聚形成公共基础服务。
本文旨在探讨常见延迟消息的实现方案及方案设计的优缺点。
实现方案一、基于外存的实现方案
这里所说的外部存储,是指除了MQ本身自带的存储之外,引入的其他存储系统。
基于外部存储的解决方案本质上是一个套路,这是MQ区别于延时模块的地方。 延迟消息模块是一个独立的服务/进程。 延迟消息先保留在其他存储介质中,等消息过期再投递给MQ。 当然,还有一些细节设计,比如消息进入延时消息模块,已经过期,直接投递的逻辑,这里就不展开讨论了。
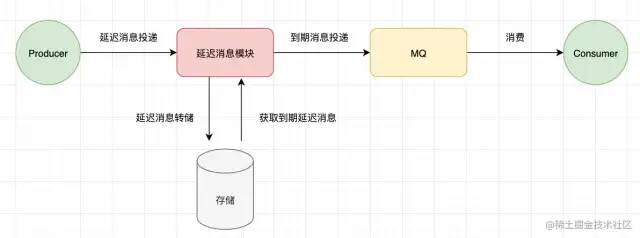
以下解决方案的区别在于使用了不同的存储系统。
基于数据库(如MySQL)
它是基于关系数据库(如MySQL)的延迟消息表实现的。

CREATE TABLE `delay_msg` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT,
`delivery_time` DATETIME NOT NULL COMMENT '投递时间',
`payloads` blob COMMENT '消息内容',
PRIMARY KEY (`id`),
KEY `time_index` (`delivery_time`)
)过期消息通过定时线程定时扫描,然后进行投递。 定时线程的扫描间隔理论上就是你延时消息的最小时间精度。
优势:
缺点:
基于 RocksDB
RocksDB的解决方案其实就是在上述方案的基础上选择更合适的存储介质。
RocksDB在笔者之前的文章中已经讨论过,LSM树更适合写入量大的场景。 滴滴开源的DDMQ中的延时消息模块Chronos就是采用了这种方案。
简单来说,DDMQ项目就是在RocketMQ之外增加一个统一的代理层。 在这个代理层中,可以进行一些功能维度的扩展。 延时消息的逻辑是代理层实现延时消息的转发。 如果是延迟消息,会先投递到RocketMQ中Chronos专用的topic。 延迟消息模块 Chronos 消费延迟消息并转储到 RocksDB 中,其次是类似的逻辑,定时扫描过期消息,然后投递到 RocketMQ。
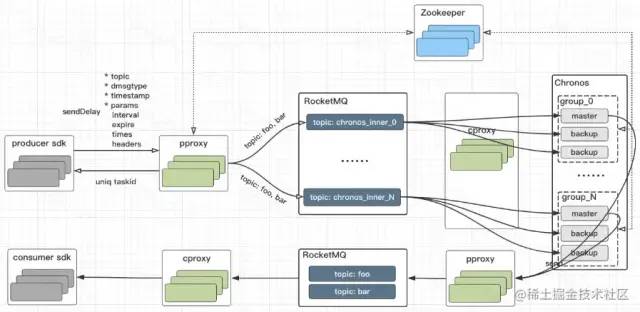
这个程序老实说是一个比较重的程序。 因为如果是基于RocksDB实现的话,从数据可用性的角度来说,还需要自己处理多副本的数据同步等逻辑。
优势:
缺点:
基于Redis
再来说说Redis的方案。 下面是一个更完整的解决方案。
本方案出自:基于Redis实现延迟队列服务
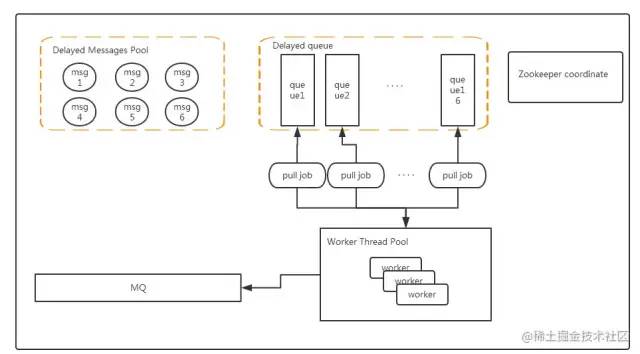
在我看来,为该解决方案选择 Redis 存储有几个考虑因素。
不过,这个方案其实也有一些考虑。 上面的方案通过创建多个Delayed Queue满足了并发性能的要求,但是这也带来了多个Delayed Queue在多节点的情况下是如何均匀分布的,很可能会出现并发重复处理expired的情况消息,是否有必要引入分布式锁等并发控制设计?

在体量不大的场景下,上述方案的架构其实可以转化为主从架构,只允许主节点处理任务,从节点仅用于容灾和备份。 实施难度更小,更可控。
定时线程检查的缺陷与改进
在上述方案中,过期消息是通过线程定时扫描的方案得到的。
定时线程方案在消息量较小时会造成资源浪费,而当消息量很大时,由于扫描间隔设置不合理,会导致延迟时间不准确。 可以利用JDK Timer类中的思路,通过wait-notify来节省CPU资源。
获取最新的延迟消息,然后等待(执行时间-当前时间),这样就不用浪费资源,时间到了自动响应。 如果有新的消息进来,并且比我们等待的消息还小,那么直接notify唤醒,重新获取这个更小的消息,然后再次等待,以此类推。
2.开源MQ中的实现方案
下面说一下目前开源的带有延迟消息功能的MQ,它们是如何实现的
火箭MQ
RocketMQ开源版支持延迟消息,但只支持18级延迟,不支持任意时间。 只不过这个Level在RocketMQ中是可以自定义的,还好对于普通业务来说已经足够了。 默认值为“1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h”,共18级。
通俗的说,设置了delay Level的消息会被暂存到一个名为SCHEDULE_TOPIC_XXXX的topic中,按照level存储到特定的queue中,queueId = delayTimeLevel - 1,**即一个queue只存储相同的消息delay ,保证发送延迟相同的消息可以顺序消费。 **broker会定时消费SCHEDULE_TOPIC_XXXX,将消息写入真实topic。
下面是整个实现方案的示意图。 红色代表投递延迟消息,紫色代表调度时间到期时的延迟消息:
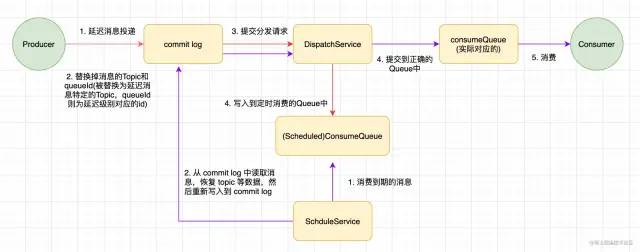

优势:
缺点:
脉冲星
Pulsar支持“任意时间”延迟消息,但实现方式与RocketMQ不同。
通俗地说,Pulsar的延迟消息会直接进入客户端指定的Topic,然后在堆外内存中创建一个基于时间的优先级队列来维护延迟消息的索引信息。 延迟时间最短的会放在头上,延迟时间越长越靠后。 在执行消费逻辑时,判断是否有消息过期需要投递。 如果有则从队列中取出,根据延迟消息的索引查询对应的消息进行消费。
如果一个节点挂了,这个broker节点上的Topic会被转移到其他可用的broker上,上面提到的优先级队列也会被重建。
下面是Pulsar公众号中Pulsar延迟消息的示意图。
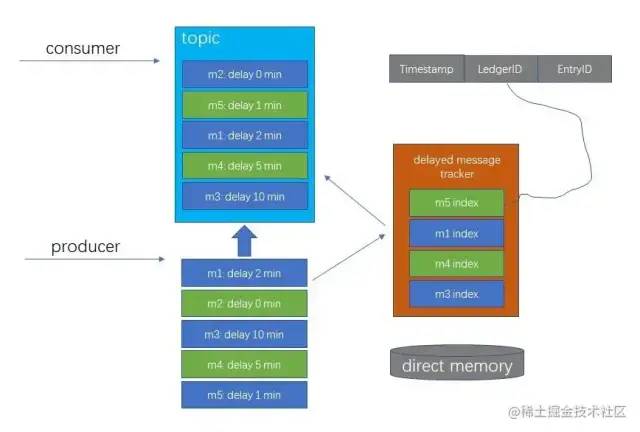
乍一看,你可能会觉得这个方案其实很简单,还可以随时支持消息。但是这个方案有几个大问题
针对上面第一点和第二点的问题,社区也设计了解决方案,在队列中加入时间分区,Broker只将当前时间片比较近的队列加载到内存中,其余时间片分区持久化在磁盘上,如示例图所示 如下图:
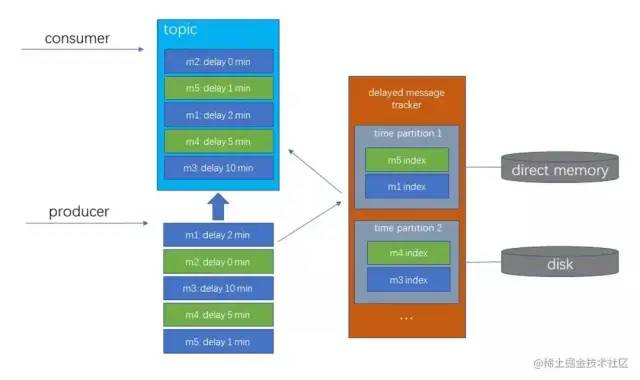
但目前该方案并没有对应的实现版本。 在实际使用中,可以规定只使用时间跨度较小的延迟消息,以减少前两个缺陷的影响。 另外,由于内存中并没有存储全量的延迟消息数据,而只存储了索引,因此可能需要数百万条延迟消息才会对内存产生重大影响。 从这个角度来说,官方还没有完善前两个这个问题也是可以理解的。

至于第三个问题,估计比较难解决。 需要在数据存储层区分延迟消息和正常消息,将延迟消息分开存储。
QMQ
QMQ随时提供延迟/定时的消息,你可以指定在未来两年内的任何时间发送消息(可配置)。
我把QMQ放在最后是因为我觉得QMQ是开源MQ中延迟消息设计最合理的。 里面的设计核心很简单就是多级时间轮+延迟加载+延迟消息单独磁盘存储。
如果对时间轮不熟悉java 延迟队列,可以看作者的文章从Kafka看时间轮算法设计
QMQ的延迟/定时消息是使用两层哈希轮实现的。 第一层位于磁盘上,每个小时为一个刻度(默认为一个小时java 延迟队列,可以根据实际情况在配置中调整),每个刻度会生成一个日志文件(schedule log),因为QMQ支持两年延迟消息(默认支持两年内,可修改配置),那么最多会生成2 * 366 * 24 = 17568个文件(如果要支持的最大延迟时间越短,文件越少生成)。 第二层在内存中。 当消息的投递时间到来时,该小时的消息索引(该索引包括消息在调度日志中的偏移量和大小)将从磁盘文件加载到内存中的哈希轮中。 中的哈希轮是以500ms为尺度的。
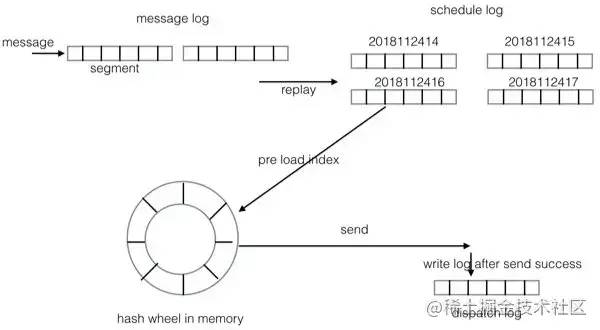
总结设计的亮点:
总结
本文总结了业界常见的延迟消息方案,并讨论了每种方案的优缺点。 希望对读者有所启发。


 上一篇
上一篇 








