

java 图像对比 开源-机器之心:Python+Numpy(+)完美适配计算图
选自deeplearning4j.org
机器之心编译
作者:Aäron van den Oord、Heiga Zen、Sander Dieleman
参与:吴攀、李亚洲
近日,Deeplearning4j 在自己的官方网站发表了一篇对比 Deeplearning4j 与 Torch、Theano、Caffe、TensorFlow 的博客文章,同时 Deeplearning4j 在文章中也对自己的框架进行了较为详细的介绍(多有溢美之词)。机器之心对全文进行了编译,文中观点仅代表原作者立场。
目录
Theano 与生态系统
深度学习领域内的很多学术研究人员依赖于 Theano,这个用 Python 编写的框架可谓是深度学习框架的老祖宗。Theano 像 Numpy 一样,是一个处理多维数组的库。与其他库一起使用,Theano 很适合于数据探索和进行研究。
在 Theano 之上,已经有很多的开源的深度库建立起来,包括 Keras、Lasagne 和 Blocks。这些库的建立是为了在 Theano 偶尔的非直觉界面上更简单地使用 API。(截止到 2016 年 3 月,另一个与 Theano 相关的库 Pylearn2 可能即将死亡。)
相反,Deeplearning4j 能在 JVM 语言(比如,Java 和 Scala)下将深度学习带入生产环境中,创造出解决方案。Deeplearning4j 意在以一种可拓展的方式在并行 GPU 或 CPU 上将尽可能多的环节自动化,并能在需要的时候与 Hadoop 和 Spark 进行整合。
优缺点
(+)Python+Numpy
(+)计算图是很好的抽象
(+)RNN 完美适配计算图
(-)原始 Theano 在某种程度上有些低水平
(+)高层次 wrappers(Keras,Lasange)减轻了这种痛苦
(-)错误信息没有帮助

(-)大型模型有较长的编译时间
(-)比 Torch 更「臃肿」
(-)对预训练模型支持不佳
(-)在 AWS 上有很多 bug
Torch
Torch 是一个用 Lua 编写的支持机器学习算法的计算框架。其中的一些版本被 Facebook、Twitter 这样的大型科技公司使用,为内部团队专门化其深度学习平台。Lua 是一种在上世纪 90 年代早期在巴西开发出来的多范式的脚本语言。
Torch 7 虽然强大,却并未被基于 Python 的学术社区和通用语言为 Java 的企业软件工程师普遍使用。Deeplearning4j 使用 Java 编写,这反映了我们对产业和易用性的关注。我们相信可用性的限制给深度学习的广泛使用带来了阻碍。我们认为 Hadoop 和 Spark 这样的开源分布式应该自动具备可扩展性。我们相信一个商业化支撑下的开源框架是保证工具有效并建立一个社区的合适解决方案。
优缺点
(+)很多容易结合的模块碎片
(+)易于编写自己的层类型和在 GPU 上运行
(+)Lua(大部分库代码是 Lua 语言,易于读取)
(+)大量的预训练模型
(-)Lua(小众)
(-)你总是需要编写自己的训练代码(更不能即插即用)
(-)对循环神经网络不太好

(-)没有商业化支持
(-)糟糕的文档支持
TensorFlow
优缺点
(+)Python+Numpy
(+)计算图抽象,如同 Theano
(+)比 Theano 更快的编译速度
(+)进行可视化的 TensorBoard
(+)数据和模型并行
(-)比其它框架慢
(-)比 Torch 更「臃肿」;更神奇;
(-)预训练模型不多
(-)计算图是纯 Python 的,因此更慢
(-)无商业化支持
(-)需要退出到 Python 才能加载每个新的训练 batch
(-)不能进行太大的调整
(-)在大型软件项目上,动态键入易出错
Caffe
Caffe 是一个知名的、被普遍使用的机器视觉库,其将 Matlab 的快速卷积网接口迁移到了 C 和 C++ 中。Caffe 不面向其他深度学习应用,比如文本、声音或时序数据。如同其他框架一样,Caffe 选择 Python 作为 API。
Deeplearning4j 和 Caffe 都能用卷积网络进行图像分类,都展现出了顶尖水平。相比于 Caffe,Deeplearning4j 还提供了任意数量芯片的并行 GPU 支持,以及许多可使得深度学习在多个并行 GPU 集群上运行得更平滑的看起来琐碎的特征。Caffe 主要被用于作为一个托管在其 Model Zoo 网站上的预训练模型的源。Deeplearning4j 正在开发一个能将 Caffe 模型导入到 Spark 的解析器。
优缺点:
(+)在前馈网络和图像处理上较好
(+)在微调已有网络上较好
(+)不写任何代码就可训练模型
(+)Python 接口相当有用
(-)需要为新的 GPU 层编写 C++/CUDA
(-)不擅长循环网络
(-)面对大型网络有点吃力(GoogLeNet,ResNet)
(-)不可扩展
(-)无商业化支持
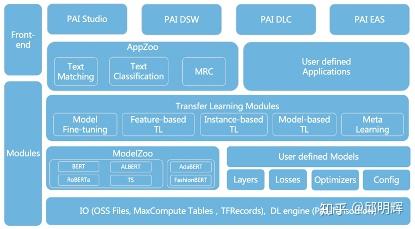
CNTK
CNTK 是微软的开源深度学习框架,是「Computational Network Toolkit(计算网络工具包)」的缩写。这个库包括前馈 DNN、卷积网络和循环网络。CNTK 提供一个 C++ 代码上的 Python API。虽然 CNTK 有一个许可证,但它还未有更多的传统许可,比如 ASF2.0,BSD,或 MIT。
DSSTNE
亚马逊的 Deep Scalable Sparse Tensor Network Engine(DSSTNE)是一个为机器学习、深度学习构建模型的库。它是最近才开源的一个深度学习库,在 TensorFlow 和 CNTK 之后才开源。大部分使用 C++ 编写,DSSTNE 似乎很快,尽管它如今没有其它库那样吸引大量关注。
(+) 处理稀疏的编码
(-) 亚马逊可能不会共享要得到其样本的最好结果所必需的所有信息
Speed
Deeplearning4j 使用 ND4J 执行的线性代数计算展现出了在大型矩阵相乘上的至少比 Numpy 快两倍的速度。这也是为什么我们的 Deeplearning4j 被 NASA 喷气推进实验室里的团队采用的原因之一。此外,Deeplearning4j 在多种芯片上的运行已经被优化,包括 x86、CUDA C 的 GPU。
尽管 Torch7 和 DL4J 都可并行,但 DL4J 的并行是自动化的。也就是说,我们对工作节点和连接进行了自动化,在 Spark、Hadoop 或者与 Akka 和 AWS 上建立大规模并行的时候,能让用户对库进行分流。Deeplearning4j 最适合于解决特定问题,而且速度很快。
为什么要用 JVM(Java 虚拟机)?
我们常被问到我们为什么要为 JVM 实现一个开源深度学习项目,毕竟现在深度学习社区的相当大一部分的重点都是 Python。Python 有很好的句法元素(syntactic elements)让你可以不用创建明确的类就能进行矩阵相加java 图像对比 开源,而 Java 却需要这么做。另外,Python 还有丰富的科学计算环境,带有 Theano 和 Numpy 这样的原生扩展。
但 JVM 及其主要语言(Java 和 Scala)也有一些优势。
首先,大部分主要的企业和大型政府机构严重依赖于 Java 或基于 JVM 的系统。他们已经进行了巨大的投资,他们可以通过基于 JVM 的人工智能利用这些投资。Java 仍然是企业中使用最广泛的语言。Java 是 Hadoop、ElasticSearch、Hive、Lucene 和 Pig 的语言,而这些工具正好对机器学习问题很有用。另一种 JVM 语言 Scala 也是 Spark 和 Kafka 的编程语言。也就是说,许多正在解决真实世界问题的程序员可以从深度学习中受益,但它们却被一些语言上的障碍隔开了。我们想要使深度学习对许多新的受众更有用,让他们可以直接将其拿来使用。在全世界 1000 万开发者中,他们使用得最多的语言就是 Java。
第二java 图像对比 开源,Java 和 Scala 实际上比 Python 更快。任何使用 Python 本身写成的东西——不管其是否依赖 Cython——都会更慢。当然啦,大多数计算成本较高的运算都是使用 C 或 C++ 编写的。(当我们谈论运算时,我们也考虑字符串等涉及到更高层面的机器学习过程的任务。)大多数最初使用 Python 编写的深度学习项目如果要被投入生产,就不得不被重写。Deeplearning4j 可以依靠 JavaCPP 来调用预编译的原生 C++,这能极大地加快训练速度。许多 Python 程序员选择使用 Scala 做深度学习,因为当在一个共享代码基础上与其他人合作时,他们更喜欢静态类型和函数式编程。
第三,虽然 Java 缺乏稳健的科学计算库,但把它们编写出来不就好了,这个我们可以通过 ND4J 完成。ND4J 运行在分布式 GPU 或 CPU 上,可以通过 Java 或 Scala API 接入。

最后,Java 是一种安全的、网络的语言,本身就能在 Linux 服务器、Windows 和 OS X 桌面、安卓手机和使用嵌入式 Java 的物联网的低内存传感器上跨平台工作。尽管 Torch 和 Pylearn2 可以通过 C++ 优化,但其优化和维护却比较困难;而 Java 是一种「一次编程,到处使用」的语言,适合那些需要在许多平台上使用深度学习的公司。
生态系统
Java 的普及只能通过其生态系统加强。Hadoop 是用 Java 实现的;Spark 在 Hadoop 的 Yarn 运行时间内运行;Akka 这样的库使得为 Deeplearning4j 构建分布式系统是可行的。
总的来说,Java 拥有经过了高度检验的基础设施,拥有大量各种各样的应用,而且使用 Java 编写的深度学习网络也能与数据保持紧密,这可以让程序员的工作更简单。Deeplearning4j 可作为一种 YARN 应用而运行和供应。
Java 也可以从 Scala、Clojure、Python 和 Ruby 等流行的语言中被原生地使用。通过选择 Java,我们能尽可能最少地排除主要的编程社区。
尽管 Java 并不如 C/C++ 快,但其比其它语言快得多。而且我们已经构建一种可以通过加入更多节点来进行加速的分布式系统——不管是用 CPU 或是 GPU 都可以。也就是说,如果你想要更快,就加入更多卡吧!
最后,我们正在使用 Java 为 DL4J 开发 Numpy 的基本应用(包括 ND-Array)。我们相信 Java 的许多缺点可以被很快地克服,而它的许多优点也还将继续持续一段时间。
SCALA
在开发 Deeplearning4j 和 ND4J 的过程中,我们对 Scala 给予了特别的关注,因为我们相信 Scala 有望变成数据科学的主导语言。使用 Scala API 为 JVM 编写数值计算、向量化和深度学习库能推动该社区向这一目标迈进。
要真正理解 DL4J 和其它框架之间的差异,你必须真正试一试。
机器学习框架
上面列出的机器学习框架更多是专用框架,而非通用机器学习框架,当然,通用机器学习框架也有很多,下面列出几个主要的:
©本文由机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@almosthuman.cn
投稿或寻求报道:editor@almosthuman.cn
广告&商务合作:bd@almosthuman.cn
 上一篇
上一篇 








