

java 类型占字节数-Java中理论说是一个字符(汉字字母)占用两个字节
这是一个来自知乎上的问题java 类型占字节数, , 提问者问:
Java 中理论说是一个字符(汉字 字母)占用两个字节. 但是在 UTF-8 的时候 new String("字").getBytes().length 返回的是 3 表示 3 个字节 小白求回答. .
严格地讲, 这个问题本身就是有问题的, 因为它缺少了前提, 在我的回答中我也强调了这一点, 回答具体如下:
首先, 你所谓的"字符"具体指什么呢? 如果你说的"字符"就是指 Java 中的 char, 那好, 那它就是 16 位, 2 字节.
如果你说的"字符"是指我们用眼睛看到的那些"抽象的字符", 那么, 谈论它占几个字节是没有意义的.
具体地讲, 脱离具体的编码谈某个字符占几个字节是没有意义的.

就好比有一个抽象的整数"42", 你说它占几个字节? 这得具体看你是用 byte, short, int, 还是 long 来存它:
当然, 如果你用 byte, 受限于它有限的位数, 有些数它是存不了的, 比如 256 就无法放在一个 byte 里了.
字符是同样的道理, 如果你想谈"占几个字节", 就要先把编码说清楚.
同一个字符在不同的编码下可能占不同的字节.
就以你举的 “字” 字为例, “字”:
不同的字符在同一个编码下也可能占不同的字节.
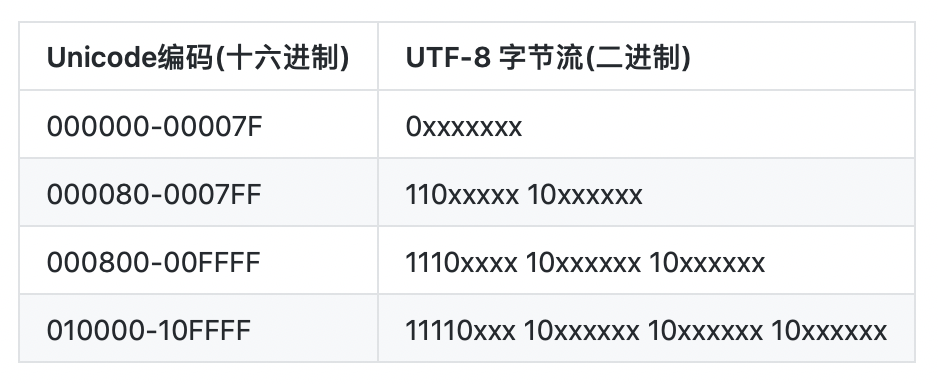
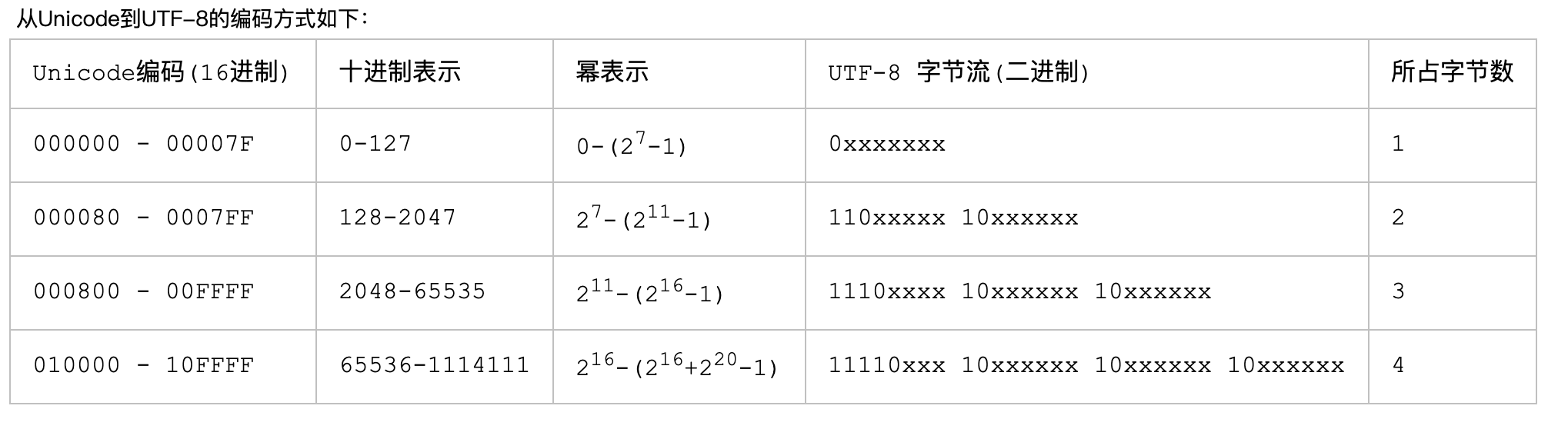
“字” 在 UTF-8 编码下占 3 字节,
而 “A” 在 UTF-8 编码下占 1 字节. (因为 UTF-8 是 变长 编码)

而 Java 中的 char 本质上是 UTF-16 编码. 而 UTF-16 实际上也是一个变长编码(2 字节或 4字节).
如果一个抽象的字符在 UTF-16 编码下占 4 字节, 显然它是不能放到 char 中的. 换言之,char 中只能放 UTF-16 编码下只占 2 字节的那些字符.
而 getBytes 实际是做编码转换java 类型占字节数, 你应该显式传入一个参数来指定编码, 否则它会使用缺省编码来转换.
你说" new String(“字”).getBytes().length 返回的是 3 ", 这说明缺省编码是 UTF-8.
如果你显式地传入一个参数, 比如这样" new String(“字”).getBytes(“GBK”).length ", 那么返回就是 2.
你可以在启动 JVM 时设置一个缺省编码:
假设你的类叫 Main, 那么在命令行中用 java 执行这个类时可以通过 file.encoding 参数设置一个缺省编码.
比如这样: java -Dfile.encoding=GBK Main
这时, 你再执行不带参数的 getBytes() 方法时, new String(“字”).getBytes().length 返回的就是 2 了, 因为现在缺省编码变成 GBK 了.
当然, 如果这时你显式地指定编码, new String(“字”).getBytes(“UTF-8”).length 返回的则依旧是 3.
如果在启动 JVM 时没有设置缺省编码, 则会使用所在操作系统环境下的缺省编码:
通常, Windows 系统下是 GBK, Linux 和 Mac 是 UTF-8.
但有一点要注意, 在 Windows 下使用 IDE 来运行时, 比如 Eclipse, 如果你的工程的缺省编码是 UTF-8, 在 IDE 中运行你的程序时, 会加上上述的 -Dfile.encoding=UTF-8 参数, 这时, 即便你在 Windows 下, 缺省编码也是 UTF-8, 而不是 GBK.
由于受启动参数及所在操作系统环境的影响, 不带参数的 getBytes 方法通常是不建议使用的, 最好是显式地指定参数以此获得稳定的预期行为.
以上回答总体而言也没有展开太多, 更多的了解可以参考 字符集编码与乱码 这个专栏.
 上一篇
上一篇 








