

如何理解java堆栈-java 堆和堆栈的区别
在计算机术语中,堆和栈代表不同的存储结构:栈-栈; 堆堆
所以java虚拟机(JVM)中的堆和栈是两种内存
堆、栈对比
比较点
堆
堆栈
JVM 中的函数
内存数据区
内存指令区
静态和动态
运行时数据区,动态分配内存大小
存储数据
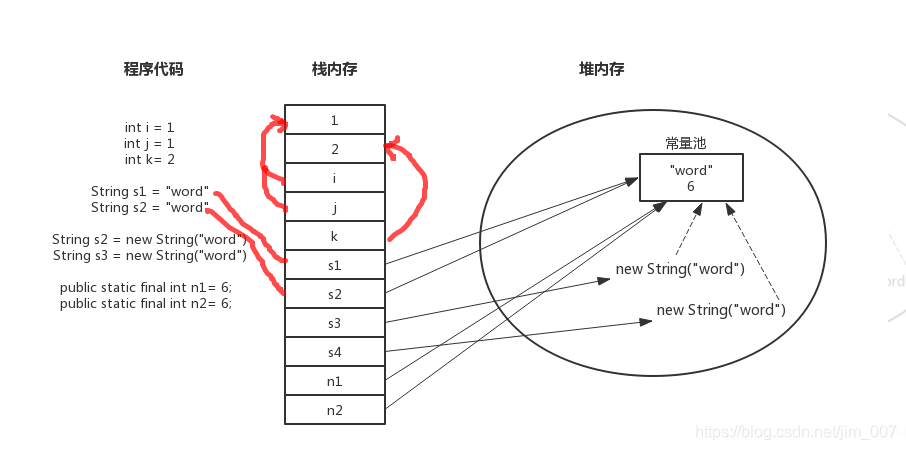
对象实例(保存对象实例,实际保存对象实例的属性值,属性的类型和对象本身的类型标志等,不保存对象的方法(方法是一个指令,保存在栈中)。对象实例在堆中分配后,需要在栈中保存一个4字节的堆内存地址,用于定位对象实例在堆中的位置,方便查找对象实例)
基本数据类型、指令代码、常量、对象引用地址(基本数据类型包括byte、int、char、long、float、double、boolean、short,函数方法属于指令)
回收方式
负责垃圾收集
当超出变量范围时,自动释放
的优点和缺点
好处是可以动态分配内存大小,生存期不需要提前告诉编译器,因为它是在运行时动态分配内存的,Java的垃圾收集器会自动收集这些不再使用的数据。 但缺点是由于运行时动态分配内存,访问速度比较慢。
栈的优点是访问速度比堆快,仅次于寄存器,栈数据可以共享。 但缺点是必须确定栈中存储数据的大小和生存期,缺乏灵活性。
栈:相当于内存指令区,存放基本数据类型、指令代码、常量、对象引用地址(基本数据类型有byte、int、char、long、float、double、boolean、short,函数方法属于指示)。

堆:是运行时数据区,内存数据区,存放对象实例,保存对象实例,实际上保存的是对象实例的属性值,属性的类型和对象本身的类型标记等,并做不保存对象的方法(方法是指令,存储在栈中)。 在堆中分配对象实例后,需要在栈中保存一个4字节的堆内存地址,用于定位对象实例在堆中的位置如何理解java堆栈,以方便查找对象实例。
网上流传的一些栈的说明:
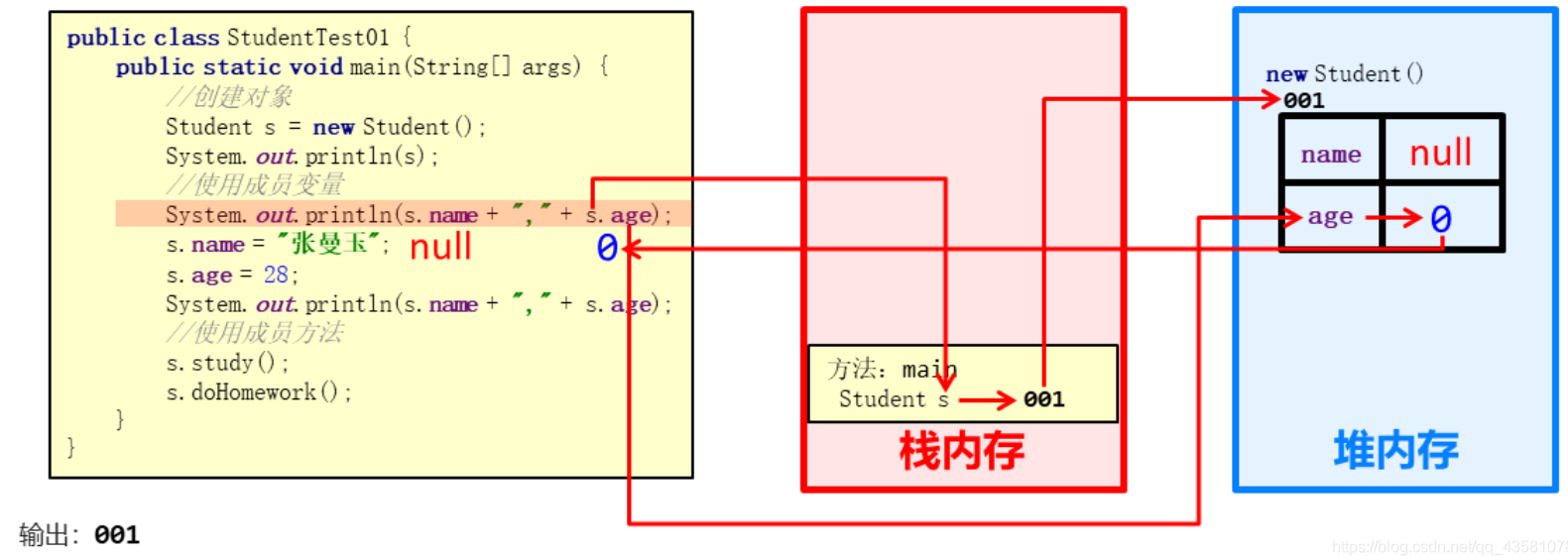
函数中定义的一些基本类型的变量和对象引用变量都分配在函数的栈内存中。 当在代码块中定义一个变量时,java会在栈上为这个变量分配内存空间。 当超出变量的作用域时,java会自动释放为该变量分配的内存空间,该内存空间可以立即用于其他用途。
堆内存用于存放new创建的对象和数组。 堆中分配的内存由java虚拟机自动垃圾收集器管理。 在堆中生成一个数组或对象后,还可以在栈中定义一个特殊的变量。 该变量的值等于数组或对象在堆内存中的首地址。 栈中的这个特殊变量一旦设置了数组或对象的引用变量,程序中就可以使用栈内存中的引用变量来访问堆中的数组或对象。 引用变量相当于数组或对象的别名或代号。
引用变量是一个普通变量,定义时在栈上分配内存,当程序运行出作用域时释放引用变量。 但是,数组和对象本身是在堆中分配的。 即使程序运行在使用new生成数组和对象的语句所在的代码块之外,数组和对象本身占用的堆内存也不会被释放。 到时候就变成垃圾了,不能再用了,但还是会占用内存,在以后不确定的时间被垃圾回收器释放。 这也是java占用内存较多的主要原因。 其实栈中的变量指向堆内存中的变量,也就是Java中的指针!

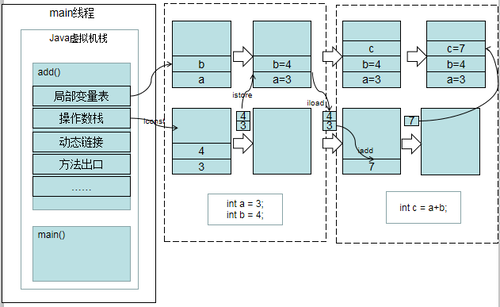
JVM是基于栈的虚拟机,JVM为每一个新创建的线程分配一个栈。 也就是说,对于一个Java程序来说,它的操作是通过对栈的操作来完成的。 栈以帧为单位保存线程的状态。 JVM只对栈进行两种操作:以帧为单位的push和pop操作。
每个Java应用程序唯一对应一个JVM实例,每个实例唯一对应一个堆。 应用程序在运行过程中创建的所有类实例或数组都放在这个堆中如何理解java堆栈,由应用程序的所有线程共享。
Java的堆是一个运行时数据区,类(对象)从中分配空间。 这些对象由new、newarray、anewarray、multiawarray等指令建立,不需要程序代码显式释放。 堆负责垃圾回收 是的,堆的好处是可以动态分配内存大小,而且生命周期不需要提前告诉编译器,因为它是在运行时动态分配内存的,Java的垃圾回收器会自动收集这些不再使用的数据。 但缺点是由于运行时动态分配内存,访问速度较慢。
栈的优点是访问速度比堆快,仅次于寄存器,栈数据可以共享。 但缺点是必须确定栈中存储数据的大小和生存期,缺乏灵活性。 栈主要存放一些基本类型的变量(、int、short、long、byte、float、double、boolean、char)和对象句柄。
栈有一个很重要的特殊性,就是栈中存储的数据是可以共享的。 假设我们同时定义:
整数 = 3; 整数 b = 3;
编译器首先处理 int a = 3; 首先,它会在栈中创建变量a的引用,然后检查栈中是否有值3。 如果没有找到,就把3存进去,然后把a指向3。然后process int b = 3; 在创建了b的引用变量之后,因为栈中已经有了3的值,所以b直接指向了3。这样就出现了a和b同时指向3的情况。 此时如果a=4; 然后编译器会重新查找栈中是否有4的值,如果没有就把4存进去,并指向4; 如果已经存在,直接指向这个地址。 因此,a 值的变化不会影响 b 的值。 需要注意的是,这种数据共享不同于两个对象引用同时指向一个对象的共享,因为这种情况下对a的修改不会影响b,它是由编译器完成的,即有利于节省空间。而且一个对象引用变量修改了这个对象的内部状态,这会影响另一个对象引用变量
 上一篇
上一篇 








