

后端服务 高并发架构-后端服务 高并发架构
持续输出技术干货,欢迎关注!
通过本文您将了解:
01 概述
高并发是互联网分布式系统架构设计必须考虑的因素之一。 通常是指通过设计保证系统可以同时并行处理很多请求。
高并发一方面可以提高资源利用率,加快系统响应速度,但同时也会带来安全、分布式事务、死锁等问题。
并发性:处理器同时处理多个任务。
并行性:多个处理器或多核处理器同时处理多个不同的任务。
02 指标
并发指标一般包括QPS、TPS、IOPS、并发用户数、PV、响应时间等。
2.1 QPS
QPS:每秒响应请求数,也就是一台服务器每秒可以响应的查询数。 最大吞吐量。
2.2 每秒
Transactions Per Second,即每秒的事务数。 事务是客户端向服务器发送请求,服务器响应的过程。 客户端在发送请求时开始计时,收到服务器的响应后结束计时,从而计算所用时间和完成的事务数。
QPS与TPS基本类似,不同的是访问一个页面一次就形成一个TPS; 但是一个页面请求可能会向服务器产生多个请求,服务器可以将这些请求计入“QPS”。
2.3 并发用户数
并发用户数:同时承载正常系统功能的用户数。 例如,在即时通信系统中,同时在线用户数在一定程度上代表了系统的并发用户数。
2.4 响应时间
响应时间:系统响应请求所花费的时间。 比如系统处理一个HTTP请求需要200ms,这200ms就是系统的响应时间。 一般来说,一个对用户友好的高并发系统,延迟应该控制在250毫秒以内。
2.5PV
PV(Page View):页面浏览量,即页面浏览量或点击次数,用户每刷新一次就统计一次。 统计服务一天的访问日志就可以得到。
03 设计思路
互联网分布式架构设计和提高系统并发的方法主要有两种:垂直扩展(Scale Up,也叫垂直扩展)和水平扩展(Scale Out,也叫水平扩展)。
1、垂直方向:提升单机能力
单机处理能力的提升可以分为硬件和软件两个方面:
硬件方向,升级服务器硬件,购买多核高频机、大内存、大容量磁盘等。
软件方向,包括使用更快的数据结构(编程语言层面的并发编程)、改进架构、应用多线程、协程(IO多路复用技术如select/poll/epoll),以及各种性能优化手段,但是这种方式容易出现瓶颈。
2.横向方向:分布式集群
为了解决分布式系统的复杂性问题,一般采用架构分层和服务拆分,通过分层隔离,通过微服务解耦。
理论上没有上限。 只要层级和服务划分好,机器扩展就可以满足需求,但实际情况并非如此。 一方面,分布式分发会增加系统的复杂度。 另一方面,集群规模增大后,也会引入一些堆服务发现和服务治理的新问题。
因为纵向的限制,我们通常更注重横向的扩展,而高并发系统的实现主要围绕横向展开。
04 聚类
单机硬件扩容成本高,软件优化容易出现性能瓶颈。 所以用集群来解决高并发问题。 负载均衡是一种常见的解决方案,即将前端流量分配到不同的服务节点。
集群架构下,池化(内存池、连接池、线程池)、分布式缓存、分布式消息队列、流控技术(服务降级、应用拆分、限流)和数据库高并发(分库分表、读取-写分离等)提高并发性。
负载均衡分为三种:
1.DNS负载均衡。 当客户端通过URL发起网络服务请求时,会去DNS服务器进行域名解析。 DNS会按照一定的策略(比如就近策略)将URL转化为IP地址,同一个URL会被解释为不同的IP地址,这就是DNS负载均衡,是一种粗粒度的负载均衡,它只使用了URL的前半部分,因为DNS负载均衡一般采用就近原则,所以通常可以减少延迟,但是DNS有缓存,所以也会出现更新不及时的问题。
2、硬件负载均衡,通过将F5、A10等专用负载均衡设备布置到机房进行负载均衡,性能高,但价格昂贵。
3、软件负载均衡,利用软件实现四层负载均衡(LVS)和七层负载均衡(Nginx)。
05 池化技术 5.1 内存池

内存池创建方法:
1、对用户申请的大块内存使用内存映射
2.对于小块内存,从内存池中合适的链表中取出
注:Linux本身有内存管理方法,但系统级的内存优化技术远远不能满足实际需要。 比较流行的内存优化技术有tcmalloc、ptmalloc、jemalloc等。
内存池的作用:
1.存储大块数据
2.存储数据缓存
5.2 进程/线程池
进程池和线程池的作用:
1.避免动态启动的时间开销
2.让加工更简单
3.充分利用硬件资源
进程池和线程池注意事项:
1、典型的生产者消费者问题
2、注意访问共享资源的竞争
5.3 连接池
连接池是一种创建和管理连接池的技术,连接池可供任何需要它们的线程使用,例如数据库连接池。
连接池创建方法:
1.预分配固定数据连接

2.为每个连接分配相应的资源
连接池的作用:
1.加快新连接的创建
2.可用于集群内部永久连接
06缓存
缓存可以分为本地缓存和分布式缓存。
本地缓存:编程实现(成员变量、局部变量、静态变量)。
分布式缓存:用Redis和Memcache实现。
通常,系统的写请求远小于读请求。 对于写少读多的场景,很适合引入缓存集群。 在写入数据库的时候,同时向缓存集群写入一份数据,然后使用缓存来承载大部分的读请求。 当缓存不存在时,搜索数据库。 这样,缓存集群可以使用更少的机器资源。 承载更高的并发。
缓存命中率一般可以很高,而且速度很快,处理能力也很强(单机可以轻松做到上万并发),是比较理想的方案。
当然,在使用分布式缓存时后端服务 高并发架构,需要特别注意一致性、缓存击穿、缓存穿透、缓存雪崩等问题。
07 Message Queue 7.1 概述
分布式缓存在读多写少的场景下表现非常出色。 对于写操作较多的场景,可以使用消息队列集群,可以对写请求进行异步处理,达到削峰填谷的效果。
消息队列可以解耦,非常适合只需要最终一致性的场景做流控。
业界知名的消息中间件有很多,比如ZeroMQ、rabbitMQ、kafka等。
7.2 特点
1、业务耦合;
2.最终一致性;
3.广播;
4.错峰和流量控制。
08流量控制
在服务中出现
8.1 服务降级
自动降级:超时、失败次数、故障、限流
手动降级:秒杀、双11大促等
服务降级需要考虑的问题:
一、核心服务与非核心服务
2.是否支持降级,降级策略
8.2 应用拆分
应用分裂原则:
1、业务优先;
2.循序渐进;
3.兼顾技术:重构、分层;
4、可靠性测试
8.3 限流
常见的限流处理方式有:计数器、滑动窗口、漏桶、令牌。
1.反法
计数器是一种相对简单的限流算法。 它计数一段时间并将其与阈值进行比较。 当达到时间临界点时,计数器清零。

但是,计数器方法存在时间临界点问题。 比如11:50:00到11:59:59这段时间没有用户请求,那么在12:00:01的瞬间发送了1000个请求,12:00又出现了1000个请求: 59. 临界点可能会承受来自恶意用户的大量请求,甚至超出系统的预期容忍度。
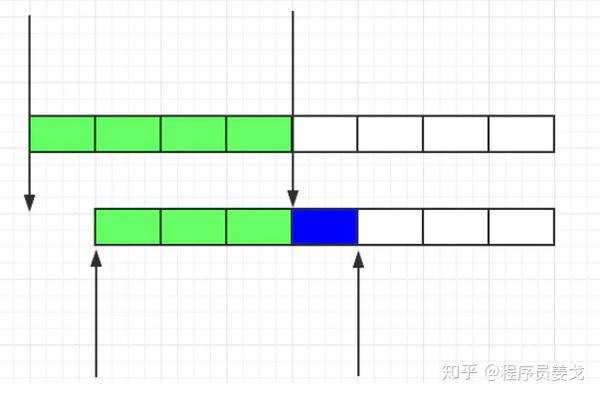
2.滑动窗口
由于计数器的临界点缺陷,出现了滑动窗口算法来解决。
滑动窗口
滑动窗口的意思是将固定的时间片进行划分,随着时间的推移而移动,巧妙的避免了计数器的临界点问题。 也就是说,会统计固定的可以移动的格子个数来确定阈值,所以格子的多少影响了滑动窗口算法的精度。
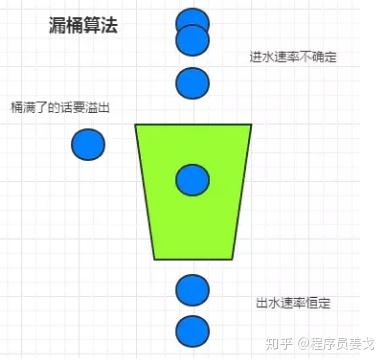
3. 漏桶算法
滑动窗口虽然有效地避免了时间临界点的问题,但是它仍然有时间片的概念,而漏桶算法在这方面比滑动窗口更先进。
漏桶算法
有一个固定的水桶,取水的速度是不确定的,但出水的速度是恒定的,水满了就会溢出来。
4. 令牌桶算法
从某种意义上说后端服务 高并发架构,令牌桶算法是对漏桶算法的改进。 桶算法可以限制请求调用的速率,令牌桶算法可以限制调用的平均速率,同时允许一定程度的突发。 打个电话。
在令牌桶算法中,有一个桶用来存放固定数量的令牌。 算法中有一种机制,以一定的速率将令牌放入桶中。 每次请求调用都需要先获取token。 只有拿到token,才能继续执行。 否则,选择等待可用令牌,或者直接拒绝。
09 数据库高并发
数据库高并发分为单机高并发(主要由存储引擎实现)和集群高并发:
1.单机高并发
InnoDB存储引擎采用多版本并发控制技术(MVCC)实现无锁并发读写,通过事务隔离级别控制并发效率。
2.集群的高并发
数据库集群的高并发主要通过分库分表、主从读写分离等方式实现。
 上一篇
上一篇 








