人工智能英语影评-NLP里程碑式突破:首个媲美人类专业译者水平
由微软亚洲研究院与雷德蒙研究院的研究人员组成的团队今天宣布,其研发的机器翻译系统在通用新闻报道的中译英测试集上,达到了人类专业译者水平。这是首个在新闻报道的翻译质量和准确率上媲美人类专业译者的翻译系统。

微软技术院士黄学东
微软技术院士,负责微软语音、自然语言和机器翻译工作的黄学东博士表示,这是自然语言处理领域的一项里程碑式的成就。“这是我们的情怀人工智能英语影评,是非常有意义的工作,”黄学东告诉新智元:“消除语言障碍,让人们能更好地沟通,非常有价值,值得我们多年来不断为此付出努力。”
黄学东骄傲地说,2015年微软率先在图像识别ImageNet数据集达到人类水平,2016年在Switchboard对话语义识别达到人类水平,2017在斯坦福问答数据集SQuAD上达到人类水平,今天又在机器翻译上达到人类水平,一路走来,微软的进步激动人心,“这是我们共同的成就,我们是站在同行的肩膀上往上走”。
黄学东表示,微软语音和NLP组在成立时,便立下了要在两年后将机器翻译做到人类专业水平的目标。如今,这一目标提前实现,“除了计算力的大幅提高,深度学习方法的提高,我们还结合了以前在Switchboard上取得的经验,数据也做了很多整理,比如去除低质量的训练数据,等等。”黄学东说。
“这既是技术上的突破,也是工程上的突破,是技术和工程的完美结合,只有把过程中的每一件事情都做好,才能得到这样的结果。”
NLP里程碑式突破:首个媲美人类专业译者的机器翻译系统
这次微软的翻译系统是在数据集WMT-17的新闻数据集newstest2017上取得了上述成果。WMT是机器翻译领域的国际顶级评测比赛之一。WMT数据集也是机器翻译领域一个公认的主流数据集。其中,newstest2017新闻报道测试集由产业界和学术界的合作伙伴共同开发,包括来自新闻评论语料库的约332K个句子对,来自联合国平行语料库的15.8M个句子对,以及来自CWMT语料库的9M个句子对。

虽然研究人员只进行了汉译英的测试,但黄学东表示,英译汉结果也应该并无不同。“从技术上说,汉译英和英译汉是相同的人工智能英语影评,只要有足够的数据。”
为了确保翻译结果准确且达到人类的翻译水平,微软研究团队还邀请了双语语言顾问,将微软的翻译结果与两个独立的人工翻译结果进行了比较评估(全部盲测)。黄学东告诉新智元:“当机器翻译质量很差的时候,使用BLEU评分还行,但是当机器翻译质量提高以后,就需要靠人类来评价。”
具体说,当100分是标准满分时,微软的系统得分69.9,专业译者68.6,而众包翻译得分为67.6。

人类专家的评估结果(部分):其中,Reference-HT为纯人工翻译;Reference-PE为使用Google Translate加人工后期编辑的翻译;Reference-WMT是WMT原始翻译,包含错误;Online-A-1710是2017年10月16日收集的Microsoft翻译商用系统(production system);Online-B-1710是2017年10月16日收集的谷歌翻译商用系统;Sogou是搜狗NMT翻译系统,这是在2017年WMT中英机器翻译竞赛的冠军。
机器翻译提前7年超越人类译者,人工智能再下一城
机器翻译是科研人员攻坚了数十年的研究领域,曾经很多人都认为机器翻译根本不可能达到人类翻译的水平。
2017年中旬,牛津大学面向机器学习研究人员做了一次大规模调查,调查的内容是他们对 AI 进展的看法。这些研究人员预测,未来10年,AI 将在许多活动中超过人类,具体预测见下表:


微软的这次突破,将机器翻译超越人类业余译者的时间,提前了整整7年,远远超出了众多ML研究人员的预想。
虽然此次突破意义非凡,但微软研究人员也提醒大家,这并不代表人类已经完全解决了机器翻译的问题,只能说明我们离终极目标又更近了一步。微软亚洲研究院副院长、自然语言计算组负责人周明表示,在WMT17测试集上的翻译结果达到人类水平很鼓舞人心,但仍有很多挑战需要解决,比如在实时的新闻报道上测试系统等。
微软机器翻译团队研究经理Arul Menezes表示,团队想要证明的是:当一种语言对(比如中-英)拥有较多的训练数据,且测试集中包含的是常见的大众类新闻词汇时,那么在人工智能技术的加持下,机器翻译系统的表现可以与人类媲美。
突破当前神经机器翻译范式局限,性能再上一个数量级
为了能够取得中-英翻译的里程碑式突破,来自微软亚洲研究院和雷德蒙研究院的三个研究组,进行了跨越中美时区、跨越研究领域的联合创新。
在这篇有24位作者的论文《机器翻译:中英新闻翻译方面达到与人类媲美的水平》(Achieving Human Parity on Automatic Chinese to English News Translation )中,微软研究团队描述了他们为新闻汉英翻译任务在规模数据集上实现人类水平所作的努力。
在论文中,作者表示他们解决了当前NMT范式的一些局限。 他们的研究主要贡献包括:
利用翻译问题的对偶性(duality),使模型能够从源语言到目标语言(Source to Target)和从目标语言到源语言(Target to Source)这两个方向的翻译中学习。同时,这让我们能同时从有监督和无监督的源数据和目标数据中学习。具体而言,我们利用通用的对偶学习(dual learning)方法,并引入联合训练(Joint Training)算法,通过在一个统一的框架中反复提高从源语言到目标语言翻译和从目标语言到源语言翻译的模型,从而增强单语源和目标数据的效果。
NMT系统从左到右自动回归解码,这意味着在按顺序生成输出期间,之前的错误将被放大,并可能误导后续生成的结果。这只能部分通过波束搜索(beam search)进行补救。我们提出了两种方法来缓解这个问题:推敲网络(Deliberation Networks),这是一种基于双路解码来优化翻译的方法;以及在两个Kullback-Leibler(KL)散度正则化项上的新训练目标,鼓励从左到右和从右到左的解码结果变得一致。

由于NMT非常容易受到嘈杂训练数据、数据中的罕见事件以及总体训练数据质量的影响,论文还讨论了数据选择和过滤的方法,包括跨语言句子表示。
最后,我们发现我们的系统是完全互补的,因此可以从系统组合中获益很多,最终实现了机器翻译达到人类水平的目标。
四大技术加持,神经机器翻译将成今后机器翻译绝对主流
其中,微软亚洲研究院机器学习组将他们的最新研究成果——对偶学习(Dual Learning)和推敲网络(Deliberation Networks)应用在了此次取得突破的机器翻译系统中。其中,对偶学习利用的是人工智能任务的天然对称性。当我们把训练集中的一个中文句子翻译成英文之后,系统会将相应的英文结果再翻译回中文,并与原始的中文句子进行比对,进而从这个比对结果中学习有用的反馈信息,对机器翻译模型进行修正。

微软亚洲研究院副院长、机器学习组负责人刘铁岩
而推敲网络则类似于人们写文章时不断推敲、修改的过程。通过多轮翻译,不断地检查、完善翻译的结果,从而使翻译的质量得到大幅提升。“我们在深度学习和自然语言这两者中间找到了一个平衡点,我们想通过对机器翻译的研究,从自然语言的角度对机器学习做进一步的理解,找到一些直觉,再通过这个直觉反过来影响机器学习研究的路线,走出盲目尝试的状态。”微软亚洲研究院副院长、机器学习组负责人刘铁岩说。
那研究人员从推敲网络中获得的直觉是什么呢?他们发现,人在做翻译的时候,在看见或听完源语言后,脑子里会形成一个观点,这其实就是编码的过程。但是,我们真正把这句话当成目标语言讲出来,实际上是三思而后行的。我们不会一个字一个字往出蹦,我们会先酝酿一下要怎么讲,如果是文字翻译,还可能不断地修改,让语句更加通顺或者优美。
“我们常常说,人会做推敲的事情,是‘僧敲月下门’还是‘僧推月下门’,要琢磨琢磨,上下文关系用哪个字更好,如何在一个机器学习的模型中将这种推敲过程体现出来,就是推敲网络所要去尝试的一个点。”刘铁岩告诉新智元。
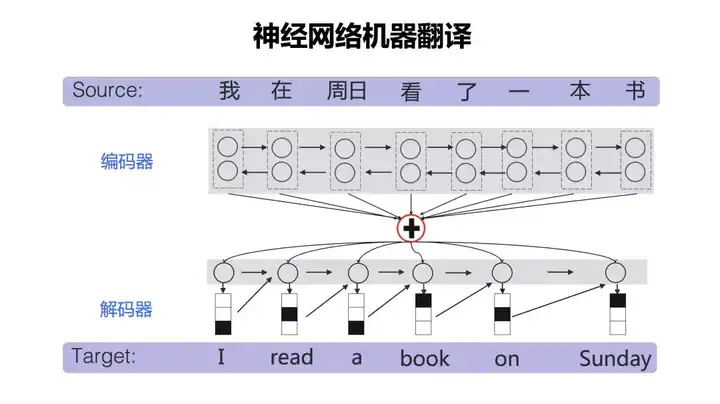

推敲,也就是在解码器,或者说在文本生成的过程多做点文章,把人的一些直觉放进去。“在我们的DeliberationNet里面,解码器是有多层的,解码器先做一遍,可能翻译得不太好,但从头到尾翻译完了,这句翻译会再扔给下一个解码器再做一遍,这个过程可以不断反复,不停地去修改之前翻译的完整结果,这其实就在做推敲。我们发现,这样推敲后的结果比只过一次要好很多,多过一次时间代价会增多,但是结果会更好。”

微软亚洲研究院副院长、自然语言计算组负责人周明
周明带领的自然语言计算组多年来一直致力于攻克机器翻译,这一自然语言处理领域最具挑战性的研究任务。周明表示,“由于翻译没有唯一的标准答案,它更像是一种艺术,因此需要更加复杂的算法和系统去应对。”
基于之前的研究积累,自然语言计算组在此次的系统模型中增加了另外两项新技术:联合训练(Joint Training)和一致性规范(Agreement Regularization),以提高翻译的准确性。联合训练可以理解为用迭代的方式去改进翻译系统,用中英翻译的句子对去补充反向翻译系统的训练数据集,同样的过程也可以反向进行。一致性规范则让翻译可以从左到右进行,也可以从右到左进行,最终让两个过程生成一致的翻译结果。

左边是联合训练:从源语言到目标语言翻译(Source to Target)P(y|x) 与从目标语言到源语言翻译(Target to Source)P(x|y);右边是一致性规范
这次使用的技术,从对偶学习(Dual Learning)、推敲网络(Deliberation Network)到一致性规范(Agreement Regularization),都属于神经机器翻译(NMT)方法。而黄学东也认为,今后的机器翻译领域,NMT也将成为绝对主流。“相比统计机器翻译,神经机器翻译有一个很大的提高,而这次我们新的系统,相比普通的神经机器翻译,又有一个很大的提高。”
黄学东说:“我们这次的系统是把很多不同的机器翻译系统组合到一起,这些系统每一个都能独立工作,输出结果,最终,我们再将这些结果综合起来,输出一个最好的结果。”
深度学习NLP掌握着实现强人工智能的钥匙
对于语音识别等其它人工智能任务来说,判断系统的表现是否可与人类媲美相当简单,因为理想结果对人和机器来说完全相同,研究人员也将这种任务称为模式识别任务。
然而,机器翻译却是另一种类型的人工智能任务,即使是两位专业的翻译人员对于完全相同的句子也会有略微不同的翻译,而且两个人的翻译都不是错的。那是因为表达同一个句子的“正确的”方法不止一种。 周明表示:“这也是为什么机器翻译比纯粹的模式识别任务复杂得多,人们可能用不同的词语来表达完全相同的意思,但未必能准确判断哪一个更好。”
复杂性让机器翻译成为一个极有挑战性的问题,但也是一个极有意义的问题。刘铁岩认为,我们不知道哪一天机器翻译系统才能在翻译任何语言、任何类型的文本时,都能在“信、达、雅”等多个维度上达到专业翻译人员的水准。不过,他对技术的进展表示乐观,因为每年微软的研究团队以及整个学术界都会发明大量的新技术、新模型和新算法,“我们可以预测的是,新技术的应用一定会让机器翻译的结果日臻完善。”
研究团队还表示,他们计划将此次技术突破推广到其他语言上面,同时应用到微软的商用多语言翻译系统产品中。
黄学东认为,神经机器翻译,或者说深度学习,最激动人心的地方在于,它能够学会自然语言内部的embedded feature,把语言的结构,语义结构和语义的表示学习出来,再反馈到系统,从而实现自然语言理解的突破。
“机器学习需要很多数据,NLP没有很多标注的数据,把表示学习出来,还能推广到其他系统。”黄学东说:“NLP掌握着今后实现强人工智能的钥匙。”
(本文首发于微信公众号“新智元:AI-era”,澎湃新闻获授权转发,禁止二次转载)
 上一篇
上一篇