

智能算法与人工智能-如何合理解释人工智能的“算法黑箱”问题的关注和质疑
以深度学习为代表的人工智能技术在信息领域的应用极大地提高了信息的利用效率和挖掘价值,深刻地影响了各个领域的商业形式,同时也引发了监管部门和用户对这一新技术应用中的“算法黑箱”问题的关注和质疑。如何合理解释相关的算法、模型和结果已经成为数据科学家迫切需要解决的问题。
首先,为什么智能算法需要可解释
1.来自人工智能的挑战
自从AlphaGo打败了顶尖的人类围棋手后智能算法与人工智能,人工智能的概念已经成为社会各界关注的焦点,也受到了各国政府的重视。一方面,它可以给我们带来许多便利,例如,它可以为我们提供医疗、法律、财务和其他方面的建议或决定,并且它还可以直接控制汽车、无人机甚至大规模杀伤性武器[1]。但另一方面,它也被用来“做坏事”,甚至危及人类。例如,一些网站使用人工智能算法来“杀死大数据”。2017年,该国发生了第一起使用人工智能技术的网上欺诈案件。2015年,德国的大众公司甚至发生了机器人“杀人事件”[2。欧盟要求所有算法解释它们的输出原理[3],这意味着无法解释的算法模型将被非法使用[3,4]。
2.可解释性是人工智能发展的必然选择
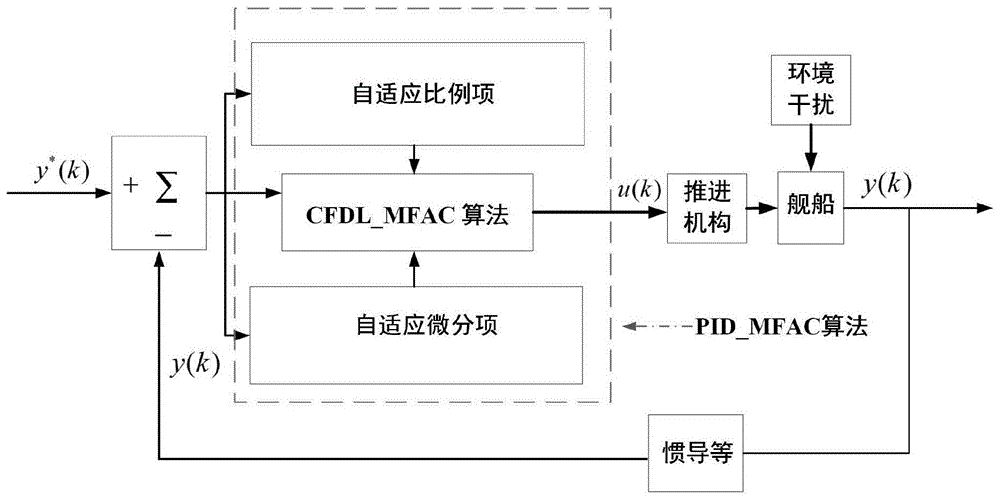
在有关人工智能的伦理、算法鉴别、算法正确性和安全性的热点问题中,经常提到一个问题,即以深度学习算法为代表的人工智能算法的可解释性。人类理性的发展过程使我们相信,如果一个判断或决定能够被解释,我们将更容易理解它的优点和缺点,评估它的风险,知道在什么程度和什么场合下它可以被信任,以及在什么程度上我们可以不断地改进它,从而增强共识,降低风险,促进相应领域的持续发展。这种思维方式可能是一种稍显过时的思维方式,它诞生于人工智能时代之前。也许随着科学技术和社会的发展,一种新的思维方式将在未来进化,但目前它仍然是我们最成熟的、基于共识的和可靠的思维方式[1]。
二。解释方法概述
谷歌科学家在17日的ICML会议上给出的可解释性定义是“解释是向人类解释的过程”[5。许多模型和应用程序无法解释,主要是因为它们对问题和任务了解不够。那么,只要在使用模型的过程中,只要它能为我们提供关于数据或模型的可理解的信息,并帮助我们更充分地发现知识、理解和解决问题,那么它就可以被归类为可解释的方法。同时,本文根据过程将可解释方法分为以下三类:建模前的可解释方法、建立具有自身可解释性的模型以及建模后使用可解释方法解释模型。下面分别介绍三类方法。建模前:建模前的可解释方法
建模前的解释方法主要包括一些数据预处理或数据显示的方法。机器学习解决了从数据中发现知识和规则的问题。如果我们对要处理的数据的特征知之甚少智能算法与人工智能,期望对要解决的问题有一个好的理解是不现实的。建模前可解释方法的关键是帮助我们快速全面地了解数据分布的特点,从而帮助我们考虑建模过程中可能出现的问题,选择最合理的模型来逼近问题所能达到的最优解。
数据可视化是建模前一种非常重要的可解释方法。许多对数据挖掘略知一二的人可能认为数据可视化是数据挖掘工作的最后一步,这可能是设计一些漂亮的虚张声势的图表或显示您的分析和挖掘结果。然而,在我们真正想研究一个数据问题之前,很有必要在各个方面建立一系列的可视化方法来建立我们对数据的直观理解,尤其是当数据量很大或者数据维数很高的时候,比如一些时空高维数据。如果我们能建立一些交互式的可视化方法,它将极大地帮助我们理解来自各个层次的数据分布。

4.建模:建立一个可解释的模型
建立一个可解释的模型是可解释方法中最关键的一种,也是一种要求很高且有限的方法。具有可解释性的模型可以大致分为以下类型的模型[6]。
基于规则的模型,比如我们提到的非常经典的决策树模型。这种模型中的任何决策都可以对应于逻辑规则表示。然而,当规则太多或者原始特征本身不太容易解释时,基于规则的方法有时是不合适的。
基于单一特征的方法主要是一些非常经典的回归模型,如线性回归、逻辑回归、广义线性回归、广义加性模型等。除了这些模型的简单结构之外,更重要的是回归模型及其一些变体具有非常坚实的统计基础。在过去的一百年里,许多统计学家讨论了模型参数的估计和校正、假设检验、边界条件和各种条件下的其他问题,使它们在各种条件下都很容易解释。
基于案例的方法主要使用一些有代表性的样本来解释聚类/分类结果。例如,可以为每个聚类选择代表性样本和重要子空间。
基于稀疏性的方法主要利用信息的稀疏性来尽可能简化模型。例如,LDA方法根据分层的单词信息形成分层的主题表达,使得一些小主题可以被更一般化的主题所概括,从而使我们更容易理解特定主题所代表的含义。5.建模后:用可解释的方法解释模型。

建模后的可解释方法主要针对具有黑盒性质的深度学习模型。深度学习的黑盒特性主要来自于其高度非线性的特性。每个神经元由前一层加上一个非线性函数的线性组合获得。人们无法通过线性回归的参数等统计基本假设来理解神经网络中参数的含义、重要性和波动范围。但事实上我们知道这些参数的具体值和整个训练过程,所以神经网络模型本身并不是一个黑箱,它的黑箱是我们无法以人类能够理解的方式理解模型的具体含义和行为,而神经网络的一个非常好的特性是神经元的层次组合,这使我们能够从物质构成的角度理解神经网络的运行模式。它主要分为以下几类工作:隐层分析法、模拟/代理模型法和敏感性分析法。
隐藏层分析方法:该方法使用一些可视化方法将隐藏层转换成人类能够理解的有意义的图像,以显示神经网络中每一层所学习的概念。众所周知,典型的美国有线电视新闻网模型的一个完整的卷积过程包括卷积-激活-汇集的三个步骤,并且还可以帮助我们理解美国有线电视新闻网在特征可视化的帮助下通过反卷积-去激活-反卷积的逆过程在每一层了解到什么[7]。此外,文献[]提出了一种网络切割方法来提取美国有线电视新闻网[8]的语义概念。
仿真/代理模型:这种方法针对黑箱模型,利用模型蒸馏技术获得新的可解释模型,并训练两个模型使其结果近似。然而,这样的算法也有很大的局限性,比如模型本身不能被“提取”,或者原始模型与提取的模型之间的差异导致可解释模型的意义不再存在。
灵敏度分析方法:一种用于定量描述模型输入变量对输出变量重要性的方法。它是使每个属性在可能的范围内变化,并研究和预测这些属性变化对模型输出值的影响程度。我们称影响程度为属性的敏感度系数。敏感度系数越大,属性对模型输出的影响就越大。一般来说,神经网络的灵敏度分析方法可分为可变灵敏度分析和样本灵敏度分析。变量敏感性分析用于检验输入属性变量对模型的影响程度,样本敏感性分析用于研究特定样本对模型的重要性,这也是敏感性分析研究的一个新方向。在金融领域,敏感性分析和局部特征探索方法(主要是树模型)可以有效地解决金融领域普遍存在的先验知识不足的问题。
六.结束语《火的礼物:人类与计算技术的终极博弈》提到“火让我们的生活更加舒适、健康和愉快。然而,它也有很大的破坏力,这可能是由意外事故或故意纵火造成的。”深入学习也是如此。希望通过算法研究者、政府、法律等方面的共同努力,我们能够更好地掌握人工智能算法,帮助我们解决各种问题,建设一个更美好的社会。
 上一篇
上一篇 








