

人工智能2.0-我们离「机械姬」还有多远?-5可能在秘密研发中
【新智元导读】我们离「机械姬」还有多远?前OpenAI研究员让AI克隆思想,模仿人类思维,边思考边行动。
当AI有了自主意识会如何?
「机械姬」中,艾娃利用人类的同情心,以欺骗的方式诱导人类获得自由,最终杀了自己的「造物主」Nathan。
近来,在众多网友的力荐下,Sam Altman终于看了这部电影。
并表示,「很好的电影,但我不明白为什么每个人都让我看它。」
许多人或许想警示,这就是让人工智能有了意识,通过图灵测试的结果。
但我们离「机械姬」上映的那一幕还很遥远,GPT-5可能在秘密研发中,让AI有智慧仍是科学家集洪荒之力最想做的事。
这不,来自不列颠哥伦比亚大学的2位研究人员发现,智能体能够像人类一样思考有很多的优势。
最新论文中,他们研究了智能体的「思想克隆」(TC)。

论文地址:
这里,人工智能通过模仿人类,学会像人类一样「思考」和「行动」。
当AI有了思想
要知道,语言是区分人类和其他生物的关键。
因此,研究人员设想,如果智能体能够理解语言,便会有很多的好处。
比如,帮助人类概括、推断、适应新的情况、将新的方式结合已有的知识,探索、计划、并在必要时重新计划。
尽管有这些益处,但AI智能体却很少思考,至少不是用人类语言去思考。
虽然神经网络可以被认为是思考的内部向量激活,但许多人假设,以离散的、符号的语言进行思考具有特定的好处。
这意味着能够用语言思考的智能体,可能比不用语言的智能体学习得更快,表现、概括得更好。
基于所有这些原因,增强AI智能体用语言思考的能力可以产生许多显著的优势。
Jeff Clune和Shengran Hu认为实现这一目标的最有效的方法是「让AI模仿人类思考」。

他们发现,人类不会孤立地获得思维技能,相反,他们一部分技能的获得是通过他人示范和教师提供的反馈来学习的。
因此,一个有效的方法是,让智能体从人类在行动时把想法说出的演示中进行学习。
这一方法不同于现有的用预训练LLMs进行规划的工作,因为这些LLMs没有受过人类在行动时说出想法的数据进行训练,即「思想数据」。
至于「思想数据」的来源,研究者选取了YouTube视频和文字录音,有大约数百万小时,包含了人们行动、计划、决定和重新规划背后的思想。
论文中,研究人员提出了一个新颖的模仿学习框架「思想克隆」。其中,智能体不仅学习人类的示范行为,如行为克隆,而且学习人类行动同时的思考方式。
在思想克隆训练框架中,智能体学习在每个时间步中产生思想,并随后根据这些思想调整行动。
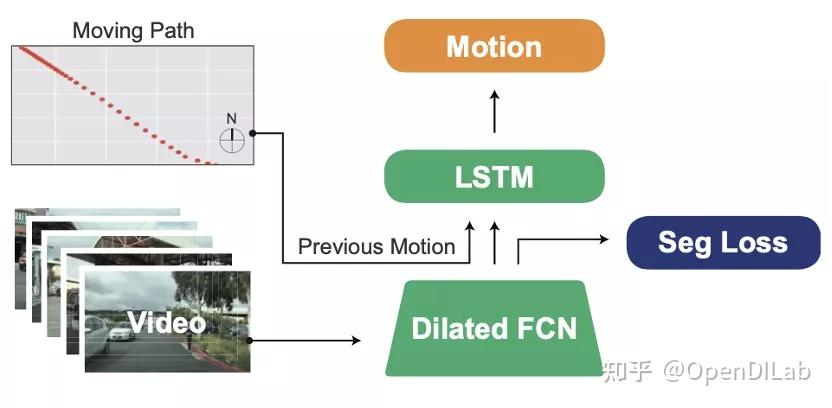
整体框架如图所示,TC智能体是一个双层架构:上层和下层组件。
在每个时间步中,智能体接收一个观察、一个任务和一段思维历史作为输入。上层组件负责思想生成,下层组件产生以这些思想为条件执行操作。
然后,将生成的想法和行动与演示数据集中的基本事实进行比较,以计算损失。
虽然对于上层和下层组件的条件可能有不同的选择,但在这项工作中,对于思维数据集中长度t的特定轨迹,研究人员将其最小化:
对于更复杂或大规模的场景,上层组件可以使用预训练视觉语言模型(VLM)来实现,或者零样本、微调。
而下层组件可以从头开始训练,或者从目标域中现有的语言条件控制器中改编。
论文中人工智能2.0,研究人员基于BabyAI 1.1模型体系结构的两个组件进行了研究。
该模型利用内存增强架构LSTM来解决部分可观测性的挑战。此外,它还采用FiLM进行模态融合,有效地结合了视觉和文本输入。
这里,作者特别强调,本文中的所有模型都是从头开始训练的,但在复杂领域中还是使用预训练模型更强。
如下图,是BabyAI环境示例,左图中包含了各种颜色的物品(球、钥匙、盒子、门)。
智能体可以拿起、放下、移动物体或者开门和关门,而锁住的门只能用颜色匹配的钥匙打开。
智能体可以看到它前面的7×7的网格单元,这些网格单元是被墙壁和关闭的门阻挡。
「思想克隆」智能体的任务是,到达紫色的盒子(高亮显示) ,并开始规划了路线。
但是当它打开蓝色的门时,准备完成任务,却发现一个紫色的球挡住了去路。于是,思想克隆智能体再重新规划。

由此可以看出,智能体的想法和行动表明,当遇到障碍时,先将其移除,并在继续之前的目标前,重新计划路线。
这一过程,就特别像艾娃如何一步一步策划,让人类最终相信并帮助自己,逃出囚禁已久的玻璃牢笼。
实验结果
研究结果表明,「思想克隆」优于行为克隆。
此外,在零样本和微调设置中,思想克隆在分布外的任务中比行为克隆优势更大。
有趣的是,研究人员还开发了「预犯罪干预」,允许用户在模型训练后仍能定义不安全行为。
当检测到危险的想法时,就能终止智能体。测试中,「预犯罪干预」的效果近乎完美,显示了它在人工智能安全方面的潜力。
「思想克隆」不仅使人工智能更聪明,而且更安全,更容易理解。
就是说,当AI犯罪前,一切还有得救。

在Jeff Clune看来,「思想克隆」有助于人工智能的安全。
因为我们可以观察到智能体的思想:(1)可以更容易地诊断出事情出错的原因,(2)通过纠正智能体的思想来引导它人工智能2.0,(3)或者阻止它做所计划的不安全的事情。
作者介绍
Jeff Clune
目前,Jeff Clune是不列颠哥伦比亚大学计算机科学副教授。他主要研究深度学习,包括深度强化学习。
此前,他还是OpenAI研究团队负责人,Uber人工智能实验室的高级研究经理和创始成员。
此前,他和OpenAI团队发布了视频预训练模型——VPT,让AI在我的世界中从视频数据中学习造石镐。
Shengran Hu
目前是不列颠哥伦比亚大学的博士生,对深度学习,人工智能生成算法感兴趣。
参考资料:
 上一篇
上一篇 








