

人工智能书籍-联通智能人工服务
第1章绪论 1.1AI嵌入式系统的概念与特点
嵌入式系统是指“嵌入”在应用中的计算机系统。嵌入式系统和传统PC的不同之处在于它通常针对特定应用配备专用软硬件接口,在运算速度、存储容量、可靠性、功耗、体积方面的要求和通用PC有明显差别。我们在日常生活中随处可见嵌入式系统,比如智能手机、万用表、无人机控制系统、电信交换机、洗衣机、智能电视、汽车控制系统、医用CT设备等(见图1-1)。
图1-1生活中嵌入式系统的例子及共性结构
通常来说,嵌入式系统具备以下几个特点:1)高可靠性,比如控制电信交换机的嵌入式系统需要24小时不停歇地工作,可靠性达到99.999%或更高;2)低延迟响应,比如车载刹车防抱死系统,需要在紧急刹车时实时判断车速,识别轮胎状态,在规定的时间内输出刹车控制命令;3)低功耗,比如万用表等手持测量设备,可能需要依赖电池使用几个月甚至几年;4)小体积,比如手机、无线降噪耳机等便携设备需要在有限体积内安装嵌入式控制系统,以满足应用场景的要求。
传统的嵌入式系统主要用于控制,即接收传感器信号、分析并输出控制命令。随着应用需求的发展,越来越多的嵌入式系统要求具备“人工智能”,成为“智能嵌入式系统”。和传统的“控制类”嵌入式系统相比,智能嵌入式系统在智能感知、智能交互和智能决策方面有了增强,如图1-2所示。
图1-2智能嵌入式系统
·智能感知
传统嵌入式系统基于固定规律,比如信号均值和方差或者它的频域变换等分析、理解信号,随着应用的拓展,人们需要让嵌入式系统理解更加复杂的或者有变化的场景。比如让智能相机系统识别当前拍摄的场景是自然风景还是室内人物或者城市建筑等;负责机械设备监控的嵌入式系统要能够识别多种异常振动模式,并对这些振动进行故障识别和分类。这一类感知和识别依赖更加复杂的分析和判断模型,通常基于有监督的训练数据得到模型参数,相比之下,传统的基于人工特征选择和信号分析算法难以实现复杂多变的智能感知。
·智能交互
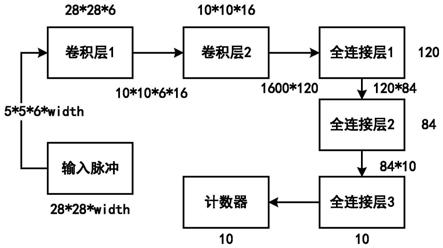
智能嵌入式系统要求和用户有更加“拟人”的双向交互能力,比如通过语音识别获取用户指示并通过“语音”汇报执行结果,或者通过手势识别、人脸表情识别等判断用户意图,并做出正确的响应,这一能力支撑了嵌入式系统实现各类“人机协作”应用。相比之下,传统的嵌入式系统交互方式限制大,通常只通过简单的按钮、显示屏交互,应用场景受限,人机互动效率低。
·智能决策
具备自主决策能力是现代嵌入式智能系统的另一重要特性,比如在自动驾驶系统中,需要车载嵌入式系统根据车速、道路障碍、交通标识信息对当前状态以及趋势进行判断,并在有限时间内发布行驶指令。此外,该系统需要能够“随机应变”,遭遇未知状态时,能够权衡动作收益和风险,给出合适的动作输出。传统的嵌入式系统在智能决策方面往往基于固定且简单的逻辑规则,虽然高效实时,但在灵活性和适应性上无法满足各类复杂应用场景对嵌入式系统的要求。
需要注意的是:机器学习算法涉及训练和推理两部分,其中训练部分需要访问海量训练样本,搜索最优的算法参数,对运算速度、功耗要求高,难以在嵌入式系统中实现,目前主要依靠GPU系统完成。本书侧重机器学习算法的推理运算,即使用训练完成的模型,对输入数据进行处理分析,得到结果。相比机器学习算法的训练,推理过程的运算量小得多,但对于资源有限的嵌入式系统,实现机器学习推理算法仍旧面临挑战,需要从不同层次进行优化。
之前介绍的“智能”型应用需求对嵌入式系统的软硬件带来了挑战,这些挑战主要来自这些应用所需要的算力需求。比如目前常用的图像分析深度卷积神经网络算法,它们的底层运算主要是二维矩阵卷积或者矩阵乘法运算,实现这些算法需要进行大量乘加运算和海量存储。图1-3给出了几种典型的神经网络的运算量[1]。
从图1-3中可以看到,对于嵌入式系统,实现比如10帧/秒的实时视频AI识别,通常需要10×109~150×109次的乘加运算,虽然已有的运算硬件(比如高性能的GPU显卡)实现这一算力并不困难,但对于要同时满足功耗、体积、可靠性、实时性等多项约束条件的嵌入式系统而言,这一运算量带来了巨大挑战。此外,一些AI算法所依赖的参数数据量也给嵌入式系统的存储带来了巨大压力,图1-4是典型的神经网络的参数数据量。
图1-3典型的图像处理卷积神经网络运算量比较
图1-4典型的图像处理卷积神经网络参数存储量比较
从图1-4中可以看到,一般神经网络的参数数据存储量在5×106~140×106之间,使用单精度浮点数存储参数值对应的存储量是20MB~560MB,相比之下,传统的低成本嵌入式系统的RAM存储空间往往不超过16MB。
随着对机器学习研究的深入,很多智能算法在性能上达到了商业应用的要求,并逐步进入我们的生活。这些算法中有不少是以嵌入式系统的形式实现的,比如人脸识别门禁系统、具有语音交互能力的智能音响、基于机器视觉的自动驾驶系统等。虽然有这些机器学习算法在嵌入式系统中的应用案例,但还存在很多待解决的问题。嵌入式系统中实现机器学习算法面临的主要问题和难点包括以下几个方面:
·运算量
在机器学习应用领域,尤其是图像识别中,需要使用二维矩阵或者更高维度的张量运算,核心算法由大量二维卷积和矩阵乘法构成,并且有些应用还需要进行矩阵分解,比如特征值分解、QR分解等,这些都是运算密集型的算法。此外,随着深度学习的兴起,神经网络的规模不断膨胀,给算力有限的嵌入式系统带来了压力。
·存储大小
机器学习算法中有一部分是基于特征数据库的搜索和比较,要求在短时间内访问海量数据,进行特征分析和比对。为满足实时性要求,往往把需要访问的数据全部存于RAM,这给嵌入式系统中有限的存储器资源分配带来了困难。此外,现代的深度神经网络在计算过程中需要访问海量权重系数,神经网络的参数规模超出嵌入式处理器子系统可用内存规模,需要短时间内在片内RAM和相对低速的外部存储器之间进行大量数据交换来完成计算。
·功耗
在嵌入式系统中实现机器学习算法往往需要同时满足运算量和实时性要求,虽然通过不断提升处理器主频和运算硬件资源可以达到要求,但付出的代价是运行功耗的提升,这限制了不少机器学习算法在使用电池供电或者太阳能等绿色能源供电等场景下的应用。
[1] 此处运算量是指神经网络对每一幅图进行推理运算所需要的乘加数量。
1.2机器学习在嵌入式系统中的实现
从1.1节的介绍可以看到,机器学习算法,尤其是神经网络算法需要进行大量的运算和存储,目前要解决这一问题大致有两条技术路线:一条是基于定制化硬件提升嵌入式处理器的运算效率,另一条是基于算法优化来解决问题。其中,在定制化的AI加速运算硬件方面,进一步分为基于通用多处理器的并行化方案和基于专用运算加速引擎的方案。
图1-5给出基于多处理器的方案,比如NVIDIA通过专用的嵌入式GPU实现神经网络运算的加速,这一方案的优点是能够通过软件灵活定义每个处理器的功能,对不同AI算法的兼容性好,但由于每个处理器需要占用大量的电路资源,并且功耗高,因此这一方案主要用于对性能要求高,但对硬件成本和功耗不敏感的领域,比如自动驾驶等。
图1-6给出了基于运算加速引擎的AI嵌入式系统方案。和基于多处理器的方案相比,这里将多处理器替换成多个专用运算引擎,比如矩阵乘法引擎、卷积引擎、数据排序和检索引擎等,由于每个运算加速引擎功能单一并且明确,因此能够充分地优化以提高运算效率并降低功耗。在相同运算量下,这一架构的功耗通常低于多处理器架构。但付出的代价是硬件加速引擎的功能固定、难以改变,损失了灵活性和对不同运算的兼容性。
本书讨论的是基于传统嵌入式处理器的AI实现技术,侧重通过算法改进和软件优化提升嵌入式系统的AI运算能力,这一方案充分利用现有处理器的运算硬件特点,不需要新的专用硬件。由于传统嵌入式处理器在运算能力、存储容量等方面的限制,对很多高性能AI的应用还是有所限制。书中所讨论的很多算法是基于通用嵌入式处理器实现的人工智能书籍,但它们也能应用于多处理器系统,并能够改造成运算加速引擎的形式。

图1-5基于多处理器架构的AI运算加速方案
图1-6基于运算加速引擎的AI嵌入式系统方案
为了能够在资源有限的嵌入式系统中实现机器学习推理算法,需要从不同层次进行优化,图1-7从高到低地给出了各个层次优化的说明。
图1-7机器学习算法在嵌入式系统实现时所使用的优化手段分层
下面具体解释各个层次优化的内容:
·系统方案优化
针对特定机器学习问题考虑使用何种解决方案,比如对于视觉图像分类应用,是通过支持向量机实现,还是通过深度神经网络实现,或是通过随机森林实现。不同的机器学习算法在运算量、内存、分类精度以及训练难度上各有优缺点,需要开发者进行权衡。
·机器学习推理模型结构优化
对于给定的机器学习算法,考虑其运算结构的简化,使用包括近似算法、模型剪枝、特征降维等手段降低运算复杂度。另外,对于给定的机器学习算法运算图,可以通过运算模块的等效变换消除冗余的中间数据计算,比如神经网络中卷积层和BN层的参数融合等。

·算子优化
针对机器学习算法的底层运算模块进行优化,降低运算复杂度,具体方案包括基于近似算法降低运算量,比如通过矩阵的低秩近似分解降低矩阵乘法运算量;基于变换域的快速算法降低运算复杂度,比如通过频域变换将卷积运算转成逐点乘法运算。
·位运算优化
基于数据二进制表示的更底层的优化,比如将常数乘法运算转成加减法实现,对浮点数乘法也可以通过对它的指数域和尾数域分别进行加减实现近似计算等。
·面向CPU硬件特性优化
针对嵌入式系统所使用的特定CPU硬件进行优化,包括使用特定CPU所具备的SIMD指令实现数据向量并行运算,使用高位宽的寄存器同时实现多个低位宽数据并行计算等。这一部分优化和硬件特性紧密相关。
以上给出的优化层级中,每一层通过优化带来的运算效率提升量都与具体问题相关,但大致来说,层级越高,优化带来的提升越大。本书讨论的内容涵盖上述这几个层级。
1.3本书内容概述
本书针对机器学习的推理运算,讨论它在嵌入式系统中的实现方法以及不同层级的优化方法,各章内容概述如下:
·嵌入式软件编程模式和优化
这一章针对嵌入式系统对软件的约束,介绍常见的几种编程模式,包括内存和CPU运行时间的分配方案、无操作系统条件下的多任务软件执行方法。此外,介绍通用的嵌入式软件优化方案,这些优化方案配合嵌入式软件编程模式,保障机器学习算法的高效可靠运行。
·机器学习算法概述

这一章介绍常用的机器学习算法,包括算法原理简介以及利用这些算法实现特定应用的例子。我们会以Python程序的形式给出机器学习算法的训练和推理代码。针对部分算法还介绍了从Python程序生成C语言程序的方法。通过比较这一章给出的不同算法的运算细节,可以发现它们具有共同的底层运算,即矩阵乘法和卷积,在随后的章节中将分别介绍这两个运算的优化。
·数值的表示和运算
机器学习底层实现需要大量的加减乘除运算,在这一章我们讨论数据的不同二进制表示形式及其运算特点,包括机器学习中经常使用的16位浮点数格式、定点数格式、仿射映射量化格式等。通过例子解释如何将高精度浮点数算法转成对嵌入式系统“友好”的定点数运算,以及如何通过简单的整数加减运算替代乘法操作以降低运算复杂度。
·卷积运算优化
卷积运算在图像处理神经网络中得到广泛应用,我们从降低卷积运算的乘法次数的角度讨论几种算法,这些算法基于卷积的多项式表示形式构建得到,不少算法在流行的神经网络框架中得以实现。另外,我们讨论近似卷积算法,通过适当降低运算精度换取运算量的大幅下降。
·矩阵乘法优化
绝大多数机器学习的推理算法能够写成矩阵乘法形式,包括矩阵乘以矩阵、矩阵乘以向量、向量乘以向量等。我们会介绍降低矩阵乘法运算中乘法数目的方法,以及多种能够降低矩阵运算量的近似算法。
·神经网络的实现与优化
在这一章,我们通过神经网络结构优化降低运算复杂度和参数存储量。所讨论的几种神经网络结构优化方案通过修改网络训练过程实现,包括网络参数稀疏化、网络运算层裁剪以及网络参数量化等。
·ARM平台上的机器学习编程
ARM处理器是当前应用最为广泛的嵌入式处理器之一,我们针对几种ARM处理器专用的软件框架介绍机器学习算法的实现,给出具体代码,将之前章节介绍的算法运行在ARM处理器上。另外,这一章也会介绍ARM的SIMD指令集,通过它实现底层运算的并行,进一步提升机器学习算法运行效率。
本书内容会涉及一部分机器学习算法原理介绍,但这些介绍不能取代机器学习专业领域的知识。希望读者能够在阅读之前对机器学习算法所了解,或者结合各章节所给算法参考相关的理论。在撰写本书的同时,出现了多个神经网络推理运算的嵌入式部署和实现框架,在本书的部分内容选取上考虑了这些框架所涉及的技术。基于嵌入式系统的多样性和硬件定制化特性,并不是所有平台都能部署通用的推理框架,需要开发者针对硬件特点手动选择实现方案,通过实践找到合适的优化方案组合。
最后,为方便读者复现书中介绍的算法,我们在华章图书官网()提供了完整的代码,读者可在该网站搜索本书下载相关资源。考虑到代码的简洁性和阅读时的便利性,部分代码以Python形式给出,为了在嵌入式系统中运行人工智能书籍,需要将它们改成C程序。希望读者通过参考并修改本书提供的代码,将其应用到实际的嵌入式系统中去。
 上一篇
上一篇 








