

设置mysql数据库字符集-mysql 替换字段中的部分字符
php创建mysql数据库时如何设置字符集?
让我给你一个全面的解释。
在正常情况下。
PHP 脚本 HTML 有浏览器,然后是数据库。
每个都有自己的字符集。 什么是字符集。 我想如果你真的有兴趣学习 PHP
那么你应该花一定的时间去了解字符集的问题。
因为不管你以后做什么项目,开发什么网站,都会涉及到字符集。
这就像我的第一个项目。 因为人设是你死我活的斗争。
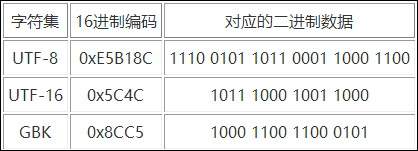
我们开始谈正事吧。 如何解决问题?
1、PHP的字符集。 PHP页面一般都是嵌套在HTML页面中,如果没有冲突就可以使用
标题设置。 例如?php 标头...?
2、HTML的字符集一般是网页的优先字符集。 这个问题涉及到你网站的定位,比如:你的网站只适合国内客户。 然后用gbk或者gb2312。 如果想让老外凑热闹,就用utf-8吧。 至于如何设置这个字符集,可以在meta标签中看到。
3.数据库问题。 mysql_query("设置名称 gbk"); 这句话的意思是在操作数据库的时候使用这个字符集进行读写。 当然这个字符集要和你页面的字符集对应。
4. 浏览器。 浏览器问题最严重,因为每个浏览器默认都是gb2312。 当然,不同的浏览器是不一样的。 所以如果你想成为一名优秀的程序员,就要编写高质量的代码。 您还必须了解每个浏览器之间的差异。 当然目前不需要,当然这道题你慢慢学。 你会在写代码的过程中慢慢学会的。
您所要做的就是设置所有使用的字符集以确保一致性
问题就到这里了,有什么问题可以尽管问。 任何对 PHP 充满热情的人。 我会尽力提供帮助。 哈哈。 因为这个加法,物以类聚。 而且这个内容绝对不是复制粘贴的。

如何调整php的默认字符集
编辑php配置文件php.ini
找到default_charset配置项,然后在下面一行添加你要更改的字符集
default_charset = "utf8"
然后重启apache或者php-fpm服务,现在打开你的网站看看有没有乱码
或者使用编辑工具将文件的字符集转换为UTF-8格式。
希望采纳 Thx
PHP创建mysql数据表,如何选择UTF8字符集

1.转码失败
向表写入数据的过程中转码失败,数据库端没有进行适当的处理,导致表中存储的数据为乱码。
针对这种情况,之前的文章介绍过客户端向服务端发送请求。
任何一个编码不一致设置mysql数据库字符集,都会导致表中的数据以错误的编码存储,产生乱码。
例如下面的简单语句:
set @a = "文本字符串";
插入 t1 值(@a);
变量@a的字符编码由参数CHARACTER_SET_CLIENT决定,假设此时编码为A,即为变量@a的编码。

2、write语句发送到MySQL服务器之前的编码由CHARACTER_SET_CONNECTION决定,假设此时编码为B。
3、经过MySQL的一系列词法语法分析,写入到表t1中,表t1的代码为C。
如果编码A、编码B、编码C不兼容,写入的数据会直接乱码。
2.客户端乱码
表格数据正常,但客户端显示后出现乱码。
这类场景指的是从MySQL表中取出数据返回给客户端。 MySQL本身的数据是没有问题的。 客户端向MySQL发送请求,表的编码为D,将从MySQL中获取的记录结果传给客户端,记录编码为E(CHARACTER_SET_RESULTS)。
如果上面的代码E和D不兼容设置mysql数据库字符集,检索到的数据就会看起来乱码。 但是由于数据本身并没有被破坏,所以可以通过改变一个兼容的编码来获得正确的结果。
该类别进一步分为三个不同的子类别:

1)字段编码与表一致,但客户端是不同的编码
例如下面的例子,表数据的编码是utf8mb4,而SESSION 1发起的连接的编码是gbk。 由于编码不兼容,检索到的数据一定是乱码。
2)表的编码与客户端一致,但记录之间的编码不一致
比如表的编码是utf8mb4,应用的编码也是utf8mb4,但是表中的数据可能一半是utf8mb4编码,另一半可能是gbk。 那么此时表中的数据也是正常的,只是此时没有编码可以读取所有完整的数据。 这样的数据有很多原因。 比如其中一种可能是表代码改了多次,每次改的都不彻底(改不彻底,我在上一章有介绍)。 比如表t3的编码,之前是utf8mb4,现在是gbk,两种编码之间写入的都是正常数据。
3)各字段编码不一致,导致出现乱码,与第二点场景相同。 不同的是:非记录之间的编码不统一,而是各个字段的编码不统一。 例如,表 c1 有字段 a1、a2。 a1编码gbk,a2编码utf8mb4。 每个字段单独读取时数据是完整的,但是如果所有字段一起读取,数据中总会出现一些乱码。
3.拉丁文1
另一种情况是以LATIN1编码存储数据
LATIN1这个字符集估计大家都知道。 LATIN1 将所有字符作为单字节流处理。 当遇到无法处理的字节流时,保持原样。 则可以保证上述两个存储和检索过程中的数据一致性。 因此,长期以来MySQL的默认编码一直是LATIN1。 这样的话,好像没什么问题,数据也没有乱码,为什么还要选择其他编码呢? 原因是字符存储的字节数不同。 比如emoji字符“❤”用utf8mb4存储,占用3个字节,那么varchar(12)可以存储12个字符,但如果换成LATIN1,就只能存储4个字符。
 上一篇
上一篇 








