

易语言读取数据库字段-c语言读取串口数据
③检索完整个表后,将得到虚表返回给用户。
EXISTS内部有一个子查询语句(SELECT … FROM…), 称为EXIST的内查询语句,其内查询语句返回一个结果集。 EXISTS子句根据其内查询语句的结果集空或者非空,返回一个布尔值(true/false)。
举例:
SELECT * FROM dept a WHERE EXISTS(SELECT 1 FROM employee b WHERE a.deptnu = b.deptnu);
在dept表中遍历每一条数据,同时对每一条数据判断是否输出,输出条件是:遍历表b,如果a中当前条(即a表中的指针在两个语句中是同一个)的deptnu属性与b中有相同的,那么变返回true。
连接系列 外连接:左连接与右连接
1.左连接,把左边的全部查出来,右边有的则匹配,没有则为null
表1:employee
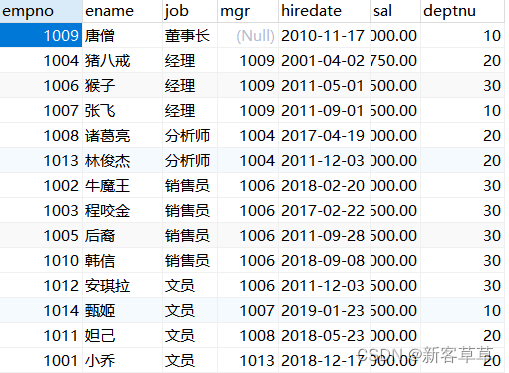
表2:dept
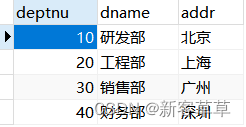
SELECT a.dname,b.* from dept a left join employee b on a.deptnu = b.deptnu;
原理:dept表(左表)中的所有信息都要显示,employee表(右表)中的信息只有匹配到的才放右边。
当左多右少时:
具体参见:left join 基本用法
等值连接
只返回两表相连相等的行
如下代码,在表a和表b中,查找id相等的行,然后返回a表中的name和b表中的class
select a.name,b.class from A a inner join B b on a.id=b.A_id
这个代码等同于
select a.name,b.class from A a,B b where a.id=b.A_id
联合查询
联合查询:就是把多个查询语句的查询结果结合在一起
主要语法1:… UNION … (去除重复) 主要语法2:… UNION ALL …(不去重复)
(select * from employee a where a.job = '销售员' order by a.sal limit 999999 ) union (select * from employee b where b.job = '文员' order by b.sal desc limit 999999);
注意:order by有时会出现排序失效的问题,在后面加上limit 99999即可。
事务
定义:指对数据库进行读或写的一个操作过程。
特性(ACID):
①原子性(Atomicity):事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
②一致性(Consistency):事务前后数据的完整性必须保持一致。
③隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行
④持久性(Durability):持久性是指一个事务一旦提交,对数据库中数据的改变就是永久性的。
引擎:使用事务的话易语言读取数据库字段,表的引擎要为innodb引擎
例如:
alter table account engine = 'MyISAM'; // 更换引擎
发现不用commit就已经修改数据库,事实上,其他引擎都不支持事务操作(无法回滚)。
事务实战
事务的开启与提交
开启:begin;m
提交:commit;
回滚:rooback;
举例:首先在窗口1登录数据库,创建表然后begin,开启事务,之后插入数据
使用select * from account发现插入成功
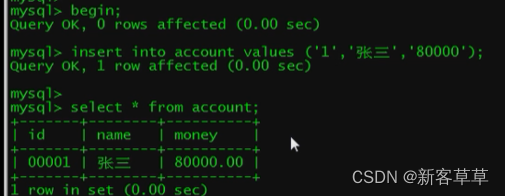
在窗口2登录数据库,然后查询

发现并没有
因为在commit之前,变化只存在于内存中,数据库(磁盘)中并没有变化,commit之后便可以更新到磁盘。从而一个事务在完成之前,是不影响另一个事务读、写数据库的。
注意:如果想要用rollback的话,最好不要设置autocommit = 1;
另一种方法(这种方法是暂时生效的,exit后重新进入又会恢复默认易语言读取数据库字段,默认开启):
如果不使用方法,直接使用语句的话,可以通过开启/关闭autocommit决定是否自动提交
查看是否自动提交
show variable like 'autocommit';
设置自动提交
set autocommit = 1; # 表示输入语句后自动提交,即更新到数据库
如果要永久生效的话,需要修改配置文件
vi /etc/my.cnf
在[mysqld]下面加上:autocommit = 1
视图
查看基表
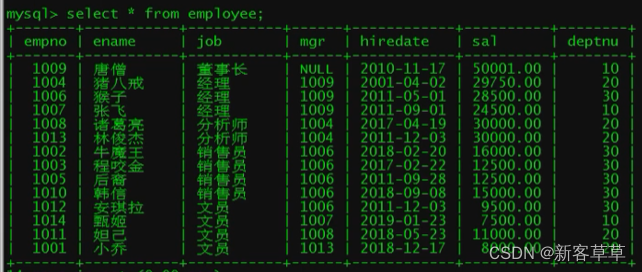
创建视图
create or replace view employ(empno,ename,job,mgr,deptnu) as select empno,ename,job,mgr,deptnu from employee;
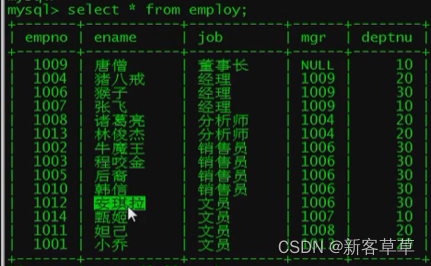
修改基表的话,视图也会修改
update employee set job = '销售员' where empno = '1012';
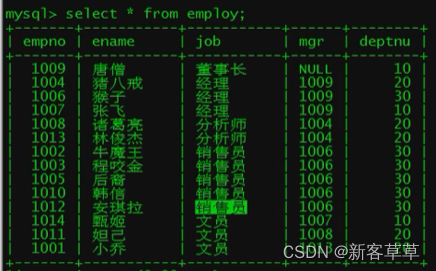
删除视图
drop view employ;
视图是逻辑上的表,内容由查询来定义,并在引用时动态生成。
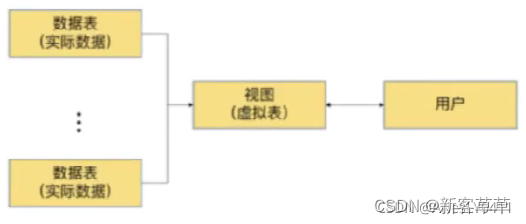
优点:
简单性:不用关心视图是怎么处理数据的(背后的表结构,关联、筛选条件),只需使用即可。
安全性:用户有权去访问某个视图,但是不能访问原表,这样可以保护原表的数据。
数据独立:视图结构确定后,可屏蔽表结构变化(如新增列)对用户的影响
减少冗余:视图是逻辑上的表,不占用数据存储的资源。
缺点:sql server必须把视图转换成对基本表的操作,如果这个视图由复杂的多表查询定义,那么即使是视图的一个简单操作,sql server也要把它变成一个复杂的结合体,需要花费一定时间。
触发器
定义:监视某种情况,并触发某种操作
创建语法:
create trigger 触发器名称 after/before insert/update/delete on 表名
for each row
begin
sql语句;
end
举例:创建一个员工迟到表
create table work_time_delay(
empno int not null comment '雇员编号',
ename varchar(50) comment '雇员姓名',
status int comment '状态'
);
创建触发器:当work_time_delay插入数据后,会更新employee中的sal,new:指的是事件发生before或者after,对应的新表
use xiaohong;
create trigger trig_work after insert on work_time_delay
for EACH ROW
BEGIN
update employee set sal=sal-100 where empno=new.empno;
end
当我们对work_time_delay 进行插入操作后
INSERT into work_time_delay VALUES ('1009','唐僧','1');
会发现他的sal已经执行-100操作
mysql存储引擎
存储引擎:基于表的数据库底层软件组织,数据库管理系统(DBMS)使用数据引擎进行增删改查等操作,不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,还可以获得特定的功能。
(类似于不同用途的车应该使用不同的发动机)
(1)查看数据库支持的引擎
show engines;
(2)建表时指定引擎
create table yinqing(id int,name varchar(20)) engine = 'InnoDB';
(3)修改引擎
alter table yinqing engine = 'MyISam';
当然也可以直接修改配置文件
vi /etc/my.cnf
在[mysqld]下面加入
default-storage-engine = MyISam;
保存后重启即可
索引的使用 创建索引
(1)创建表的时候创建(注意会自动成为主键索引)
如下是创建关于id的唯一索引
create table test (
id int(7) zerofill auto_increment not null,
username varchar(20),
servnumber varchar(30),
password varchar(20),
createtime datetime,
unique (id)
)DEFAULT CHARSET=utf8;
(2)直接为表添加索引
如下,index是普通索引关键字
语法:
alter table 表名 add index 索引名称 (字段名称);
eg:
alter table test add unique unique_username (username);
注意:假如没有指定索引名称时,会以默认的字段名为索引名称
注意:假如没有指定索引名称时,会以默认的字段名为索引名称
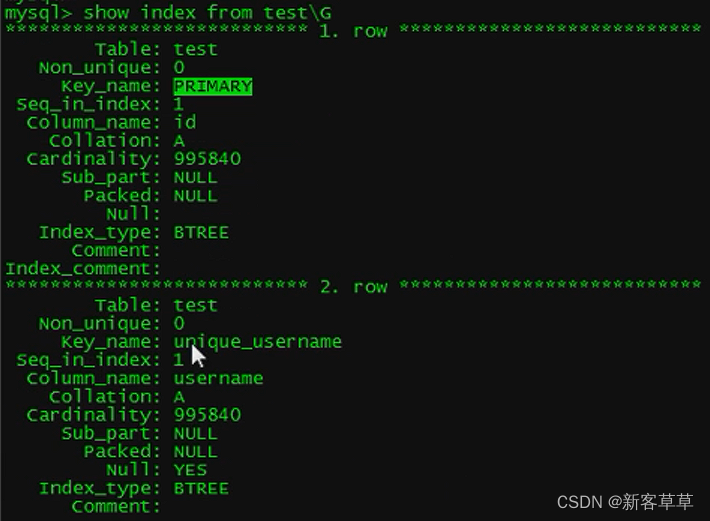
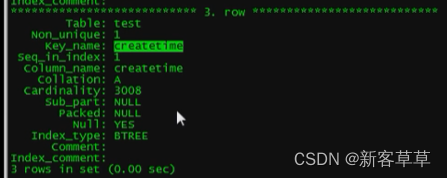
查看索引
语法:show index from 表名\G
eg: show index from test\G
分别表示主键索引、唯一索引、普通索引
删除索引
语法:alter table 表名 drop index 索引名;
eg:alter table test drop index createtime;
eg:alter table test drop primary key;
注意:在有自增的情况下,必须先删除自增,才可以删除主键
创建主键索引
1)创建表的时候创建
2)直接为表添加主键索引
语法:alter table 表名 add primary key (字段名);
eg:alter table test add primary key (id);
全文索引
关键词:fulltext
创建方法:
方法一:创建表的时候创建全文索引
create table command (
id int(5) unsigned primary key auto_increment,
name varchar(10),
instruction varchar(60),
fulltext('instruction')
)engine=MyISAM;
方法二:
通过alter添加
alter table command add fulltext(instruction);
作用:解决字段是否包含的问题,可以极大提高数据的查询速度(必须是文本类型 )
例如:
普通查询
select * from command where instruction like '%sections%';
全文索引查询(速度快很多)
select * from command where match(instruction) against ('sections');
删除全文索引
alter table command drop index instruction;
外键
将一个表的某个字段指向另一个实体的主键。被指向的称之为主,父表。负责指向的称之为从表,子表。
字表中插入元素必须能与从表中的某个元素对应,否则不行
例如表1中插入deptnu为50,由于表2中没有,于是无法插入
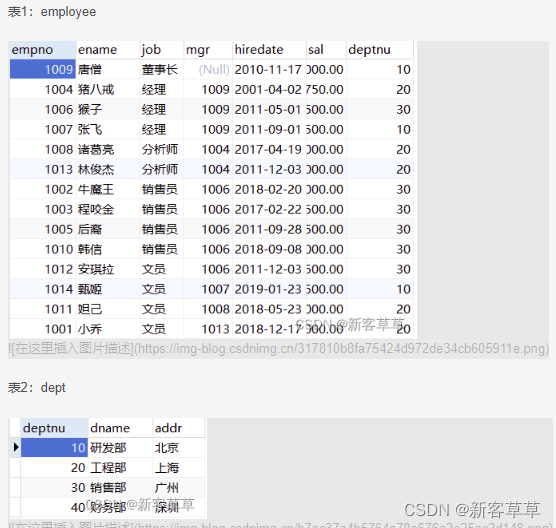
外键的作用:
①为了一张表记录的数据不要太过冗余。
②保持数据的一致性、完整性。
关键词:foreign key
语法:foreign key (字段名) references 关联的表名(关联表的字段名)
方法一:创建表的时候创建外键索引
CREATE TABLE `employee` (
`empno` int(11) NOT NULL COMMENT '雇员编号',
`ename` varchar(50) DEFAULT NULL COMMENT '雇员姓名',
`job` varchar(30) DEFAULT NULL,
`mgr` int(11) DEFAULT NULL COMMENT '雇员上级编号',
`hiredate` date DEFAULT NULL COMMENT '雇佣日期',
`sal` decimal(7,2) DEFAULT NULL COMMENT '薪资',
`deptnu` int(11) DEFAULT NULL COMMENT '部门编号',
PRIMARY KEY (`empno`),
foreign key (deptnu) references dept(deptnu)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
方法二:
alter table employee add foreign key (deptnu) references dept(deptnu);
删除
alter tabel employee drop foreign key 外键名(注意不是字段名);
注意:在删除索引之前必须先把这个索引对应的外键约束删除
联合索引
explain select * from test where username like 'user11%' and servnumber like '137000000%' and password like 'n%'
显示三个索引可用(possible_key),实际使用的是(key)
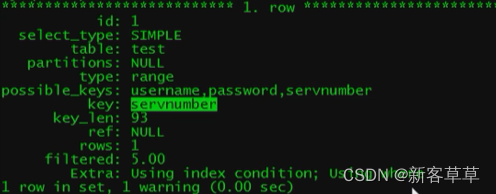
具体过程是:假设原本是100w条数据,那么先使用servnumber索引(由mysql判断该索引的效率最高)先进行检索并找到满足条件的10w条数据,但是剩余的条件在检索过程中是不会使用索引的,这样会很浪费时间
于是提出了联合索引的概念
alter table test add index(username,password,servnumber);
 上一篇
上一篇 








