

数据库索引使用场景-索引技术 应用场景
前言
面试中我们经常碰到面试官问到数据库索引,问到索引就会问你索引的数据结构。类似这种数据结构对于普通程序员来说记住概念几天就忘了,而且概念不是每个人都能很好都理解,所以针对这一原因,我简单通俗都像大家讲解为什么mysql使用都是B+树,而不用其他的树形结构。
正文
Q1:B+树的查询时间大概多少?
A:跟树的高度有关,是O(log n)。
Q2:hash查找时间大概多少?
A:o(1)。

Q3:hash比B+查找时间更短,为什么索引不用hash?
A:这和业务场景有关,如果只查找一个值的话,hash是一个很好的选择,单数据库经常会选择多条,这时候由于B+树索引有序,并且又有链表相连,它的查询效率比hash就快很多了。而且数据库中的索引一般是在磁盘上,数据量大的情况可能无法一次装入内存,B+树的设计可以允许数据分批加载,同时树的高度较低,提高查找效率。
下面我对第三个问题进行一个解析,让大家更好的记住。
二叉排序树
同一高度下左边跟节点小,右边跟节点大,并且左右子树都是二叉排序的。但是在极端情况下插入的是有序的序列就会变成链表。


所以这时候我们就要对二叉树进行平衡,让插入的时候节点能均匀分布。
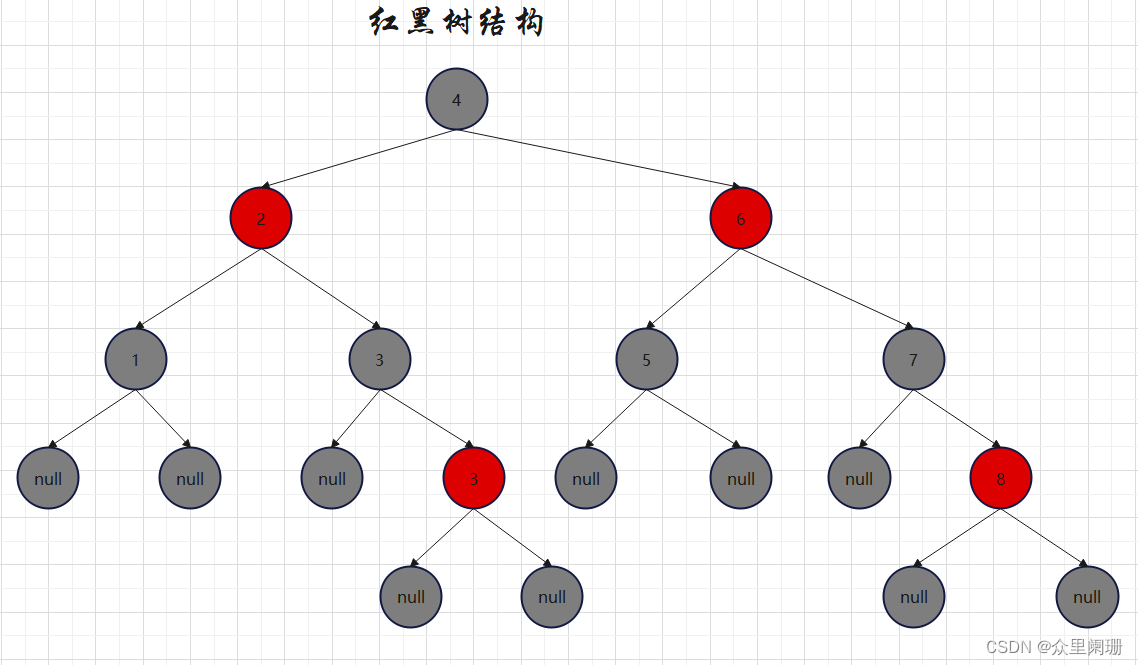
红黑树
所以引入红黑树,红黑树是平衡树的一种,他的复杂规则都是为了保证树的平衡,所以大家在记概念的时候理解不上去。


我们知道,树形结构的数据查找速度跟树的高度有关,所以尽可能让树平衡就是为了降低树的高度,java里有一种s数据结构底层就用的红黑树,就是TreeSet。
B树,也叫B-树,大家千万不要说B减树。
B树是一种多路搜索树,每个节点都可以有多于两个子节点,M路的B树就是有最多有M个子节点。
这就是一个3路B树


多路的结构就是为了尽可能降低树的高度,使查询速度更快,有一种情况就是无限多路,那就变成一个数组了,所以我们树ArrayList适合用来查询,数组结构的数据都有这个特点。

所以我们常常用B树做文件系统的索引,因为我们文件和数据库的索引都是存在硬盘上的,并且如果数据量大的话,不一定能一次性加载到内存中。所以一棵树无法全部加载到内存里我们怎么查找,这时候就用到我们刚才说到的B树了,我们可以每次加载树的每一个节点,然后一步一步往下查找,而且多路B树每个节点会多于两个子节点,速度会更快数据库索引使用场景,所以我们不用红黑树数据库索引使用场景,因为红黑树子节点只有两个。

B+树
B+树是在B树基础上改造的,他的数据都在叶子节点,同时叶子节点还加了指针。
这是一个四路B+树,叶子节点都数据形成了链表

这也是和业务场景相关的,你想想,数据库中select数据,不一定只选一条,很多时候会选多条,比如按照id排序后选10条。如果是多条的话,B树需要做局部的中序遍历,可能要跨层访问。而B+树由于所有数据都在叶子结点,不用跨层,同时由于有链表结构,只需要找到首尾,通过链表就能把所有数据取出来了。
比如我们查找7到19,B+ 都威力看到了吧。所以小伙伴们回到前文都三个问题中,就知道了为什么MySql索引使用B+树了吧。

 上一篇
上一篇 








