

mysql数据库导出命令-mysql命令导出数据表
(0)目录
走,是一辈子,不走,也是一辈子(程序猿之路)
Navicat连接mysql出现2003——can't connect to mysql server on localhost(10061)
mysql 数据库导入导出方法总结(是时候总结)
注意:mysqldump 是在 操作系统命令行下运行的。
不是在 mysql 命令行下运行的,进入MySQL目录下的bin文件夹,如:C:\Program Files\MySQL\MySQL Server 5.5\bin>
一般形式:mysqldump -h IP -u 用户名 -p 数据库名 > 导出的文件名
(1)-p 后面不能加password,只能单独输入如1中那样 (2)mysqldump是在cmd下的命令mysql数据库导出命令,不能再mysql下面,即不能进入mysql的(即use dpname下,得exit退出mysql下才可以的。)
一:数据库的导出(备份)
0:(备份数据库即导出所有表以及数据 不加-d)
mysqldump -h localhost -u root -p test > G:\arcgisworkspace\zypdoc\test.sql
1:(备份数据库即导出所有表结构)
C:\Program Files\MySQL\MySQL Server 5.5\bin>mysqldump -h localhost -u root -p -d test > G:\arcgisworkspace\zypdoc\test.sql
ENTER PASSWORD:******
2 :(导出某张表的表结构不含数据)
mysqldump -h localhost -u root -p -d test pollution > G:\arcgisworkspace\zypdoc\test.sql
3:(导出某张表的表结构和数据,不加-d)
mysqldump -h 127.0.0.1 -u root -p test pollution > G:\arcgisworkspace\zypdoc\test.sql
0:备份多个数据库的语法C:\Program Files\MySQL\MySQL Server 5.5\bin>
mysqldump -h 127.0.0.1 -u root -p --databases test bank > G:\arcgisworkspace\zypdoc\test.sql
或 mysqldump -h 127.0.0.1 -u root -p --databases test bank > G:\arcgisworkspace\zypdoc\test.txt 是没有用的,因为仍然是sql的格式。
1:备份所有的数据库的语法C:\Program Files\MySQL\MySQL Server 5.5\bin>
mysqldump -h 127.0.0.1 -u root -p --all -databases > G:\arcgisworkspace\zypdoc\test.sql(暂时没有通过,不知道为什呢)
二:数据库的导入(还原)
0:导入数据库(首先得创建数据mysql数据库导出命令,再导入)C:\Program Files\MySQL\MySQL Server 5.5\bin>
mysql -h localhost -u root -p(进入mysql下面)
create database abc;(创建数据库)
show databases;(就可看到所有已经存在的数据库,以及刚刚创建的数据库abc)
use abc;(进入abc数据库下面)
show tables;(产看abc数据库下面的所有表,空的)
source G:\arcgisworkspace\zypdoc\test.sql(导入数据库表)
show tables;(查看abc数据库下面的所有表,就可以看到表了)
desc pollution;(查看表结构设计)
select * from pollution;
exit(或者ctrl + c)退出mysql
三:MYSQL如何导出文本文件 (备份为csv,txt,等,更加有用)
0:mysql 下导出为指定格式的数据的外部任意文件类型 mysql>
use dbname
Database Changed
select * from pollution into outfile 'G:\\arcgisworkspace\\zypdoc\\text.txt'; (指导出数据的,注意转义字符哦)
select * from pollution into outfile 'G:\\arcgisworkspace\\zypdoc\\text.csv' FIELDS TERMINATED BY '\,'; (输出格式控制)
结果为:
1,汽车尾气,200
2,建筑扬沙,180
3,汽车喷漆,160
4,燃煤,240
5,其它,80
知识补充:
一般形式:select [列名称] from tablename [where]
into outfile '目标文件路径' [option]
其中option参数常用的5个选项
FIELDS TERMINATED BY ‘字符串’:设置字符串为字段的分割符,默认值为 \t;
FIELDS ENCLOSED BY ‘字符’:设置字符串括上char varchar text等字符型字段,默认值为 无任何符号;
FIELDS OPTIONALLY ENCLOSED BY ‘字符’:设置字符串括上字段的值,默认值为 无任何符号;
LINES STARTING BY ‘字符串’:设置每一行开头的字符,默认值为 无任何字符;
FIELDS ESCAPED BY ‘字符’:设置转义字符,默认值为 \;
LINES TERMINATED BY ‘字符串’:设置每行结束符,默认值为 \n;
如:
select * from pollution into outfile 'G:\\arcgisworkspace\\zypdoc\\text2.csv'
FIELDS TERMINATED BY '\,' OPTIONALLY ENCLOSED BY '\"'
LINES STARTING BY '\>' TERMINATED BY '\r\n';
结果为:
>1,"汽车尾气","200"
>2,"建筑扬沙","180"
>3,"汽车喷漆","160"
>4,"燃煤","240"
>5,"其它","80"
1:mysqldump 下导出为指定格式的数据的外部任意文件类型 C:\Program Files\MySQL\MySQL Server 5.5\bin>
mysqldump -u root -p -T G:\arcgisworkspace\zypdoc\ abc pollution "--fields-terminated-by=," (记住不要任何多余的空格,也不用转移字符;-p后面也不用写password;注意目
标目录是文件夹,文件名是表名,后缀是txt文件)
知识补充:
mysqldump -u root -p -T 目标目录 dbname tablename [option]
option 和 上面的mysql的一样,只是更改为
"--fields-terminated-by=字符"(不要任何多余的空格,就是指fields-terminated-by紧密相连的)
四:MYSQL如何导入文本文件 (更加有用)
(1)mysql 下导出为指定格式的数据的外部任意文件类型 mysql>
第一步:创建对应字段的数据表
create table csv_test2(
id int(8) primary key,
name varchar(64),
value int(32)
);(2)插入:加入value的类型开始时设计错了,如何更改:ALTER table csrv_test2 MODIFY column value varchar(32);
(3)第二步:导入外部数据
LOAD DATA INFILE 'D:\\tjdata_metro\\test\\mysql_infile3.csv'
INTO TABLE csv_test2
FIELDS TERMINATED BY '\,'
OPTIONALLY ENCLOSED BY '\"'
LINES TERMINATED by'\r\n'
ignore 1 lines
(id,name,value);上面的 lines terminated by '\r\n' 是 要求换行符号,为 windows的换行
上面的 ignore 1 lines是 忽略第一行的标题行。
五:数据的性能优化
(1) 使用索引优化查询:提高查询的速度;但是一定要避开批量插入之后再创建索引;并且要避免%开头的应用: where name like '%zz'
(2)优化数据库结构:将字段很多的表分解为多个表,某些字段的使用频率非常低,可以拆开;
(3)有些时候会频繁的使用某几个表的某些字段,而联合查询速度会很慢的,这就需要创建中间表或者视图 了
如:做一个购物车,已经做好了一个用户表,一个物品表,具体的字段见图;想建立另一个表shopCar,其中包括goods表中的goodsName,goodsPrice、users表中的username
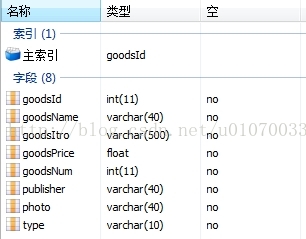
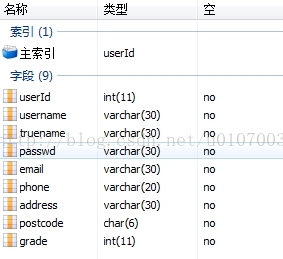
create table shopCar
(
gname varchar(40),
gprice float(),
uname varchar(30),
foreign key (gname) references goods(goodName),
foreign key (gprice) references goods(goodPrice),
foreign key (uname) references users(username)
)(4)数据库中的视图和中间表的比较(不是很了解)
(5)临时表:你做的查询希望几个表关联起来联合查询组成一个新的“虚拟表”时,会用到;最通俗的,就是你做多表连接的时候,多个嵌套子查询看起来会比较乱,分割存入
临时表看着比较清晰,运用也比较灵活
 上一篇
上一篇 








