

sql查询数据库版本-2000万开房数据sql 查询
原因
SQL Server数据库查询速度慢的原因有很多,常见的有以下几种:
1.没有索引或者没有使用索引(这是慢查询最常见的问题,是程序设计上的缺陷)
2、I/O吞吐量小,形成瓶颈效应。
3.查询未优化,因为没有创建计算列。
4.内存不足
5.网速慢
6、查询的数据量过大(可以采用多次查询,也可以采用其他方法减少数据量)
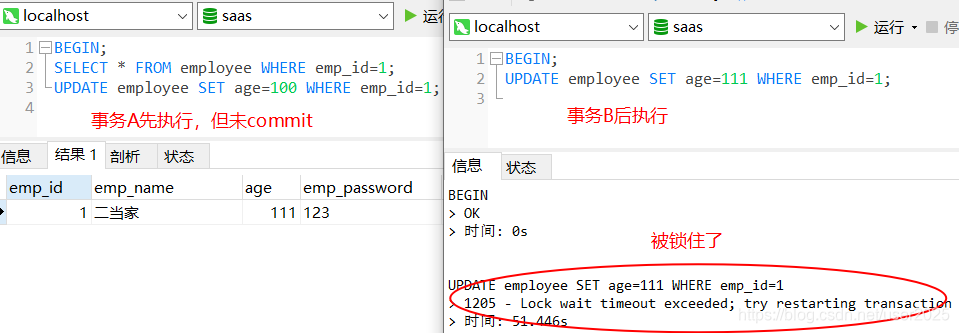
7.锁或死锁(这也是慢查询最常见的问题,是程序设计上的缺陷)

8.sp_lock、sp_who、active users查看,原因是读写竞争资源。
9.返回不需要的行和列
10、查询语句不好,没有优化
可以通过以下方式优化查询:
1.将数据、日志、索引放在不同的I/O设备上,提高读取速度。 以前可以把Tempdb放在RAID0上,但是SQL2000已经不支持了。 数据量(size)越大,提高I/O就越重要。
2. 垂直和水平拆分表以减小表的大小(sp_spaceuse)
3.升级硬件
4、根据查询条件,建立索引,优化索引,优化访问方式,限制结果集的数据量。 注意填充因子要合适(最好使用默认值0)。 索引尽量小,最好用字节数少的列建索引(参考创建索引),不要为取值个数有限的字段单独建索引,比如性别领域。
5.提高网络速度。

6、扩展服务器内存,Windows 2000和SQL server 2000可支持4-8G内存。
配置虚拟内存:虚拟内存大小应根据计算机上并发运行的服务进行配置。 运行 Microsoft SQL Server 时? 2000,考虑将虚拟内存大小设置为计算机中安装的物理内存的 1.5 倍。 如果您额外安装了全文搜索功能,并打算运行微软搜索服务进行全文索引和查询,请考虑:配置虚拟内存大小至少为计算机安装的物理内存的3倍。 将 SQL Server max server memory 服务器配置选项配置为物理内存的 1.5 倍(虚拟内存大小设置的一半)。
7、增加服务器CPU数量; 但必须明白,并行处理和串行处理需要更多的资源,比如内存。 MsSQL 会自动评估是使用并行处理还是串行处理。 单个任务分解为多个任务,可以在处理器上运行。 例如,延迟查询的排序、连接、扫描、GROUP BY 子句是同时执行的。 SQL Server根据系统的负载来决定最佳的并行级别。 消耗大量 CPU 的复杂查询最适合并行处理。 但是更新操作UPDATE、INSERT、DELETE不能并行处理。
8、如果用like查询,单纯用索引是不行的,全文索引很耗空间。 like ''a%'' 使用索引 like ''%a'' 不使用索引而使用 like ''%a%'' 查询,查询时间与字段值的总长度成正比,所以不能使用 CHAR 类型,但可以使用 VARCHAR。 为具有很长值的字段构建全文索引。
9、DB Server和APPlication Server分离; OLTP 和 OLAP 分离
10.分布式分区视图可用于实现数据库服务器复合体。
联合是一组单独管理但协作共享系统处理负载的服务器。 这种通过分区数据形成数据库服务器复合体的机制可以扩展一组服务器,以支持大型多层网站的处理需求。 有关详细信息,请参阅设计联合数据库服务器。 (参考 SQL 帮助文件“分区视图”)
A。 在实现分区视图之前,表必须水平分区
b. 创建成员表后,在每个成员服务器上定义一个分布式分区视图,每个视图同名。 这样,可以在任何成员服务器上运行引用分布式分区视图名称的查询。 系统运行时好像每个成员服务器都有原始表的副本,但实际上每个服务器只有一个成员表和一个分布式分区视图。 数据的位置对应用程序是透明的。
11、重建索引DBCC REINDEX、DBCC INDEXDEFRAG,收缩数据和日志DBCC SHRINKDB、DBCC SHRINKFILE。 设置自动收缩日志。 不要为大型数据库设置自动数据库增长,它会降低服务器性能。
T-sql的写法有很多讲究,共通点列举如下: 一、DBMS处理查询计划的过程如下:
1.检查查询语句的词法和语法
2.将语句提交给DBMS的查询优化器
3.优化器进行访问路径的代数优化和优化
4. 从预编译模块生成查询计划
5.然后在合适的时候提交给系统处理执行
6、最后将执行结果返回给用户。
解决方案

其次,看SQL SERVER的数据存储结构:一页大小为8K(8060)字节,8页为一个磁盘区,按照B树存储。
12、Commit和rollback的区别 Rollback:回滚一切。 提交:提交当前事务。 不必在动态 SQL 中编写事务。 如果要写,请写在外面,如:begin tran exec(@s) commit trans 或将动态SQL写成函数或存储过程。
13、在查询Select语句中,使用Where子句限制返回的行数,避免表扫描。 如果返回不必要的数据,会浪费服务器的I/O资源,增加网络负担,降低性能。 如果表很大,表扫描时表被锁定,其他join禁止访问表,后果很严重。
14.SQL注释语句对执行没有影响
15.游标尽量不要用,占用资源多。 如果需要逐行执行,尽量使用非游标技术,比如客户端循环、使用临时表、Table变量、使用子查询、使用Case语句等。
游标可以根据它支持的提取选项进行分类:只有行必须按从第一行到最后一行的顺序提取。 FETCH NEXT 是唯一允许的提取操作,并且是默认操作。 可滚动性可以随机获取游标中任何位置的任何行。 游标技术在SQL2000下变得非常强大,其目的就是支持循环。
并发选项有四种 READ_ONLY:不允许通过游标定位进行更新,组成结果集的行没有锁。
OPTIMISTIC WITH valueS:乐观并发控制是事务控制理论的标准部分。 开放式并发控制用于以下情况:在打开游标和更新行之间,第二个用户更新行的可能性很小。 使用此选项打开游标时,没有锁控制行,这有助于最大化其处理能力。 如果用户试图修改一行,则将该行的当前值与上次获取该行时获得的值进行比较。 如果任何值发生变化,服务器就会知道其他人更新了该行并返回错误。 如果值相同,服务器执行修改。
选择此并发选项 OPTIMISTIC WITH ROW VERSIONING:此乐观并发控制选项基于行版本控制。 使用行版本控制,表必须具有某种版本标识符,服务器可以使用该标识符来确定该行自读入游标后是否已更改。 在 SQL Server 中,此功能由时间戳数据类型提供,它是一个二进制数,表示数据库中更改的相对顺序。
每个数据库都有一个全局当前时间戳值:@@DBTS。 每次以任何方式更改带有时间戳列的行时,SQL Server 首先将当前@@DBTS 值存储在时间戳列中,然后递增@@DBTS 的值。 如果表有时间戳列,则时间戳记录在行级别。 然后,服务器可以将行的当前时间戳值与上次获取该行时存储的时间戳值进行比较,以确定该行是否已更新。 服务器不必比较所有列的值,只比较时间戳列。 如果应用程序需要基于没有时间戳列的表的行版本控制的乐观并发,则游标默认为基于数字的乐观并发控制。 SCROLL LOCKS 此选项实现悲观并发控制。 在悲观并发控制中sql查询数据库版本,应用程序将在将数据库行读入游标结果集时尝试锁定它们。 使用服务器游标时,更新锁会在行被读入游标时放置在该行上。 如果在一个事务中打开一个游标,事务更新锁将被持有,直到事务被提交或回滚; 当获取下一行时,删除游标锁。 如果游标是在事务外打开的,则在获取下一行时会丢弃锁。
因此,只要用户需要完全悲观并发控制,就应该在事务中打开游标。 更新锁将阻止任何其他任务获取更新或排他锁,从而阻止其他任务更新该行。 但是,更新锁不会阻止共享锁,因此它不会阻止其他任务读取该行,除非第二个任务也要求使用更新锁进行读取。 滚动锁 这些游标并发选项可以根据游标定义的 SELECT 语句中指定的锁提示生成滚动锁。 滚动锁在获取每一行时获取,并一直保持到下一次获取或游标关闭,以先发生者为准。 在下一次提取时,服务器为新提取中的行获取滚动锁,并释放前一次提取中行的滚动锁。 滚动锁独立于事务锁,可以在提交或回滚操作后持有。 如果提交时关闭游标的选项关闭,则 COMMIT 语句不会关闭任何打开的游标,并且滚动锁会保留到提交之后sql查询数据库版本,以保持所获取数据的隔离。 获取的滚动锁类型取决于游标并发选项和游标SELECT语句中的锁提示。锁提示只读乐观值
指定 NOLOCK 提示会使为其指定提示的表在游标内为只读。
16、使用Profiler跟踪查询,获取查询所需时间,找出SQL的问题; 使用索引优化器优化索引
17.注意UNion和UNion all的区别。 UNION 一切都好
18.DISTINCT的使用要注意,没必要的时候不要用,它和UNION一样会拖慢查询速度。重复记录在查询中没有问题
19、查询时不要返回不必要的行和列
20. 使用 sp_configure ''query governor cost limit'' 或 SET QUERY_GOVERNOR_COST_LIMIT 来限制查询消耗的资源。 当评估查询消耗的资源超过限制时,服务器会自动取消查询,在查询被杀死之前将其杀死。 SET LOCKTIME 设置锁定时间
21.使用select top 100 / 10 Percent限制用户返回的行数或SET ROWCOUNT限制操作的行数
22、在SQL2000之前,一般不要使用以下字样:“IS NULL”、“”、“!=”、“!>”、“!
 上一篇
上一篇 








