

什么是数据库中的事物-中昌数据是国企
什么是数据库?
数据库是以某种有组织的方式存储的数据集合。 即:一个容器,其中包含有组织的数据(一个文件或一组文件)
为什么我们需要数据库?
毫无疑问,数据库是用来存储数据的。 excel我们当然不陌生,excel也是用来存储数据的。 那么既然有excel这样一个非常好用的软件,为什么还需要数据库呢? ?
数据库解决了以上问题,数据库以一种特殊的机制管理数据文件,对数据具有极高的读写速度,大大超过了操作系统对常规文件的读写速度。
数据库系统的组成部分
数据库系统由三层组成:
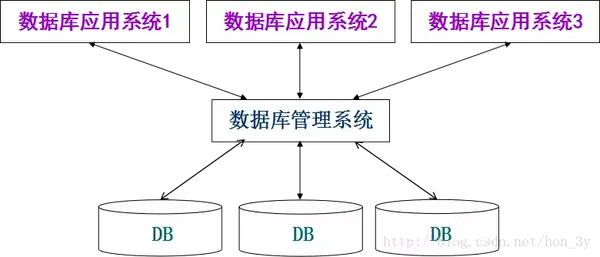
数据描述和数据模型理解数据描述
我们在现实生活中描述一个事物是很简单的。 当我们看到“一棵树”时,我们说它是“一棵树”。
但是如何在计算机中描述“一棵树”呢? ? 电脑只认0和1,“一棵树”不能直接存入电脑!
于是乎,我们把“一棵树”抽象出来,形成信息世界的概念模型。 然后将概念模型形式化为DBMS支持的数据模型,存储在计算机中。
简单地说:数据描述就是将现实世界中的对象抽象出来,形成一个概念模型。 将概念模型的形式转换成DBMS支持的类型,然后存入计算机!
了解数据模型
**数据模型主要是用来描述数据的! **如前所述,当我们要将真实事物的数据存储在计算机上时,需要先将其抽象成一个概念模型。 把概念模型转化为DBMS支持的数据模型,就可以把东西存到电脑里了!
一个数据模型一般由三部分组成:
数据模型也经历了一个发展阶段:
①:层次模型,是一种将数据组织成树状(层次)结构的数据模型。
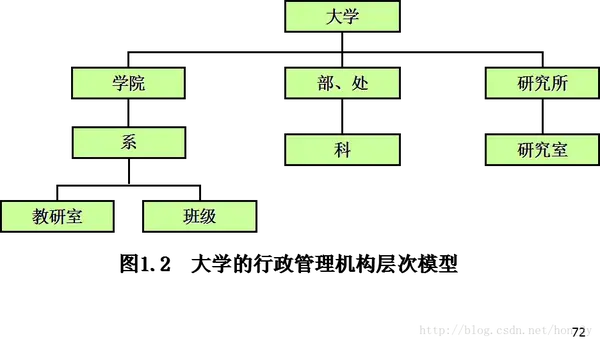
优势:
缺点:
②:网络模型,是一种使用有向图结构组织数据的数据模型
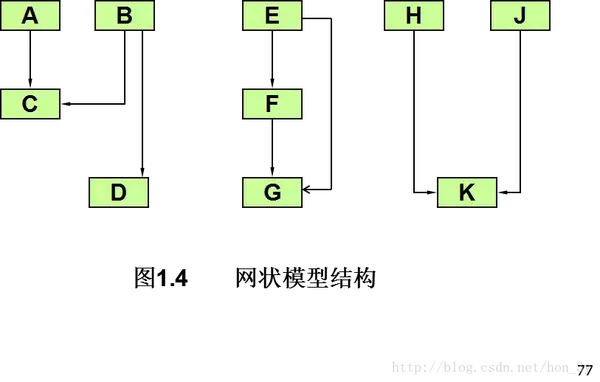
优势:
缺点:
③:关系模型,是一种用二维表结构来表示数据和数据之间关系的数据模型。

关系模型是我们现在使用最多的数据模型。
优势:
缺点:
术语(基本概念)
我们对照课程关系表来解释一下:
实体
客观存在并可以相互区分的事物称为实体。可以看成是Java类
示例:(课程关系表)是一个实体。
属性
实体所具有的特征称为属性。 可以看成是Java类的成员变量。 属性在数据库中也称为字段(或列)
示例:(课程名称)、(课程编号)、(课时)是属性名称。
元组
包含属性名称的行以外的行称为元组。
下面每一行数据称为一个元组(C401001数据结构70)(C401002操作系统80)(C402001计算机原理60)
密码(钥匙)
代码也称为关键字。 它可以唯一标识一个实体。
候选键和主键:
示例:邮寄地址(城市名称、街道名称、邮政编码、单位名称、收件人)
它有两个候选键:{cityname, streetname} 和 {streetname, zipcode}
如果我选择{城市名称,街道名称}作为唯一标识实体的属性,那么{城市名称,街道名称}就是主键
关系模式
关系名称及其属性集的组合称为关系模式。
关系模式示例:课程关系表(课程编号、课程名称、课时)
提示:关系模型是关系模式的集合
区域
关系模型要求元组的每个组成部分都是原子的,即必须属于某种元素类型,如Integer、String等,不能是列、集合、记录、数组!
域表示元组中每个组件的类型。 从上图中我们可以看出它的域是这样的:课程编号:string,课程名称:string,课时:int
数据库系统的内部结构
数据库系统的内部结构可以分为三层:
三级模型的位置:
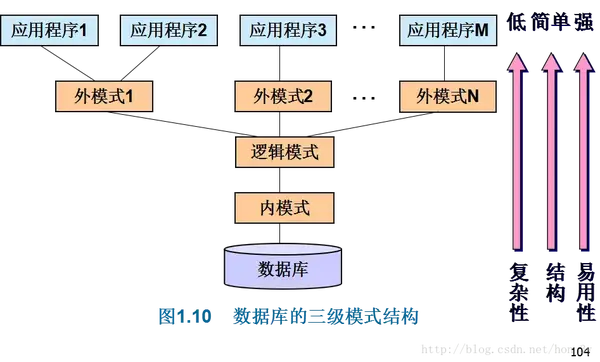
三级模型的作用:
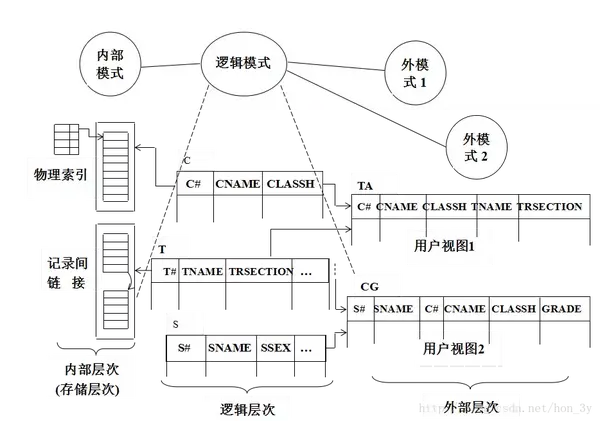
逻辑模式

逻辑模式是对数据库中所有数据的整体逻辑结构的描述。
例子:现在我有一个数据库,操作权限、角色、用户的关系
所以我们有下面的关系模型
数据库中所有关系模式的集合构成了一个逻辑模式!
外模
外部模式是对数据库用户可以看到和使用的本地数据逻辑结构的描述,是与应用程序相关的数据的逻辑表示。
可以有多种外部模式。 外部模式是用户和DBAS之间的接口,是对本地逻辑结构的描述!
当用户应用只需要显示用户名和密码时:
在数据库中操作本地的逻辑结构,就叫做外部模式!
内部模式
内部模式是对数据库表的物理存储结构的描述。它定义了数据的内部记录类型、记录寻址技术、索引和文件组织以及数据控制方面
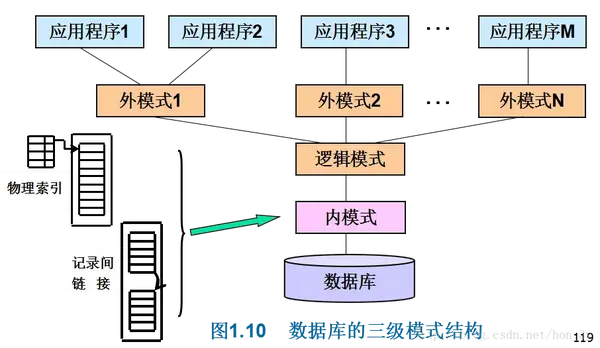
数据库内部架构的两层图像
二级图像是:
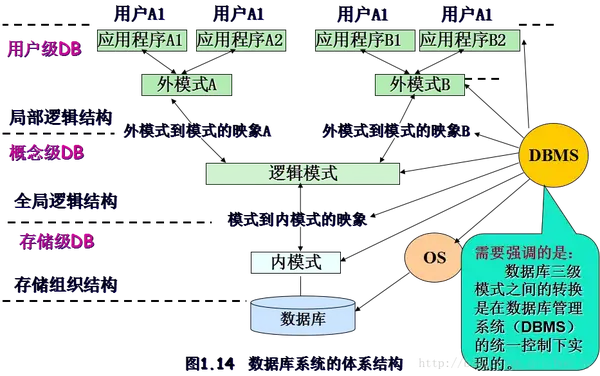
提出二级映射的概念有什么用? 为什么我们需要有这两个层次的图像呢? ?
也就是说:改变内部结构时,只要不触动外部数据,就不需要改变外部数据。 二级图像概念的提出,也是程序中的耦合问题!
为什么要学习数据库关系操作?
学习和理解关系操作的机制对于理解关系数据库中的数据查询机制非常重要。
我们可能知道查询多张表时要剔除冗余数据,那么冗余数据是如何产生的呢? ? WHERE 子句如何过滤数据? ? 我们可以在关系操作中找到这些问题的答案。
学习数据库的关系操作,可以让我们了解SQL语句是如何执行的,通过什么方式可以得到我们想要的结果。
教学大纲

笛卡尔积 什么是笛卡尔积?
笛卡尔积只是两个集合相乘的结果。
为什么查询数据库会出现笛卡尔积?
上一篇博文已经说过,关系模型是关系模式的集合。
数据库中的两张表相当于两个集合。 当我们使用 SELECT 语句查询数据时,DBMS 内部通过集合相乘得到结果。
笛卡尔积的产生过程
我们发现:笛卡尔积的基数是每组元组的乘积!


获取的数据内容很难符合现实中的实际情况
为了更好的看到效果,我会用实际的SQL语句来看效果,然后再说明问题。
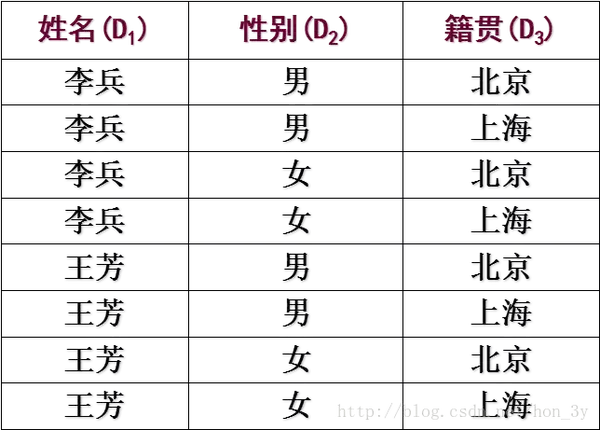
emp表中有14条记录:
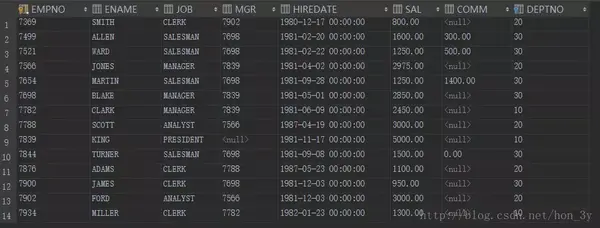
dept表有4条记录:
我们看一下SMITH,在emp表中,他只在20个部门。

但是查询了两张表,他在10、20、30、40部门! ! 我们又观察了56条数据,发现每个人有4个部门。 这样的数据不合理! !
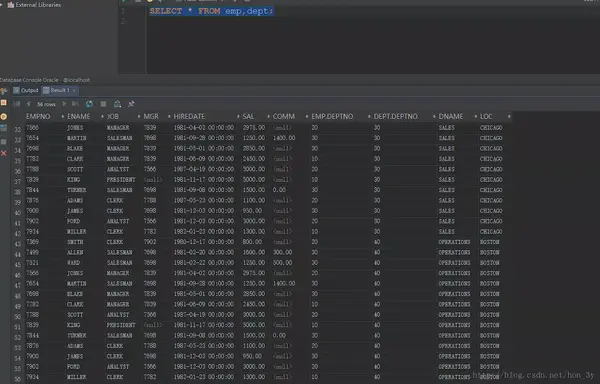
回到初衷,我们查询两张表的目的是什么? ? **在查询员工信息的同时,还可以知道员工的部门名称是什么! ! ! **因此,我们查询的记录数应该不会有56条那么多。。 我们查询的记录数应该是employee表的记录数,才14条!
我们再分析一下:emp表中有deptno字段,dept表中也有deptno字段! 并且发现emp表中deptno字段的取值范围是由dept表中的deptno字段决定的! ! !
因此,我们可以使用等价连接(emp.deptno=dept.deptno)来消去笛卡尔积,这样就达到了我们的目的!
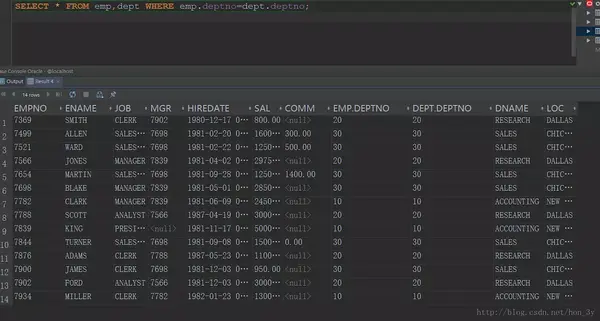
基于传统集合论的关系运算
在 Oracle 上什么是数据库中的事物,操作集合的语法提供了四个关键字:
和
显示查询结果的所有信息,剔除重复元组

查询所有文员和经理信息
SELECT *
FROM emp
WHERE job = 'MANAGER'
UNION
SELECT *
FROM emp

WHERE job = 'CLERK';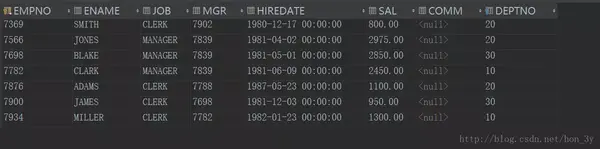
注意:使用UNION运算比使用关键字OR的性能要好!
支付
返回查询结果的相同部分

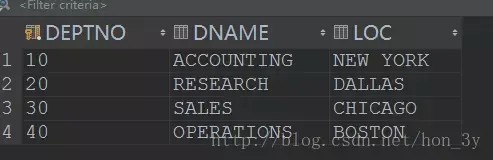
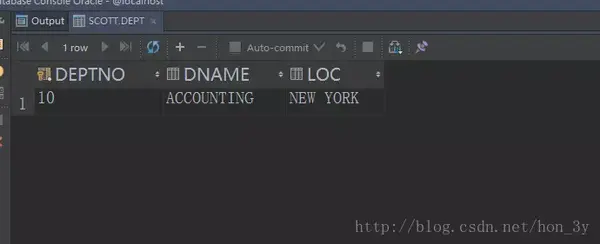
查询10个部门信息
SELECT *
FROM dept
INTERSECT
SELECT *
FROM dept
WHERE deptno = 10;(所有部门和部门10只有部门10相同,所以最后返回部门10的结果)
不同之处
返回的查询结果为
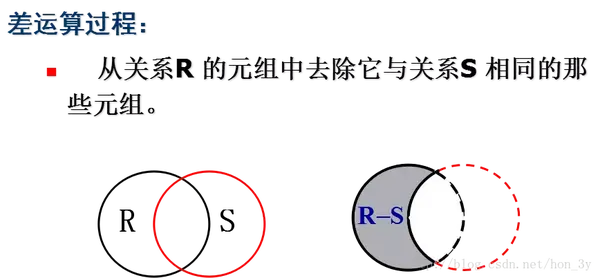

SELECT *
FROM dept
MINUS
SELECT *
FROM dept
WHERE deptno = 10;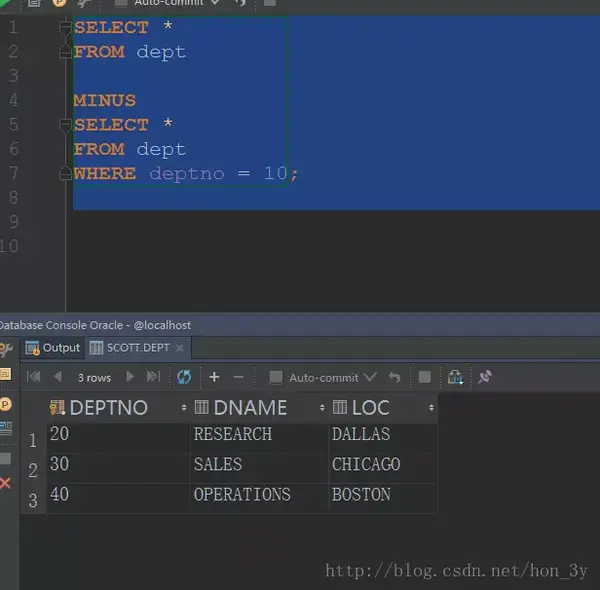
关系代数特有的关系运算的投影
投影的操作过程:
首先按照j1,j2,...,jk的顺序,取出列号为j1,j2,...,jk的k列(或者属性名顺序为Aj1,Aj2,...,Ajk ) 从关系 R 中取出 Repeat 元组,形成以 Aj1, Aj2, ..., Ajk 为属性顺序的 k-item 关系。
简单来说就是:在查询结果中取出某列,剔除重复数据。 这是投影!
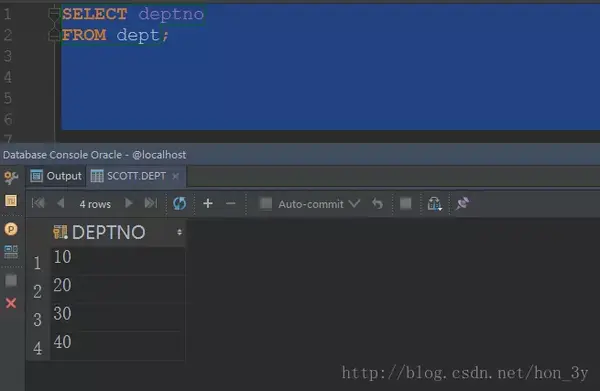
查询所有部门的人数
SELECT deptno
FROM dept;
查询的过程:首先查询dept表的所有结果,然后通过投影操作只提取“deptno”的列数据。 如果“*”后面跟着 SELECT,那么所有的数据都会被投影!
选择
使用比较运算符和逻辑运算符挑选出满足条件的元组并计算结果!
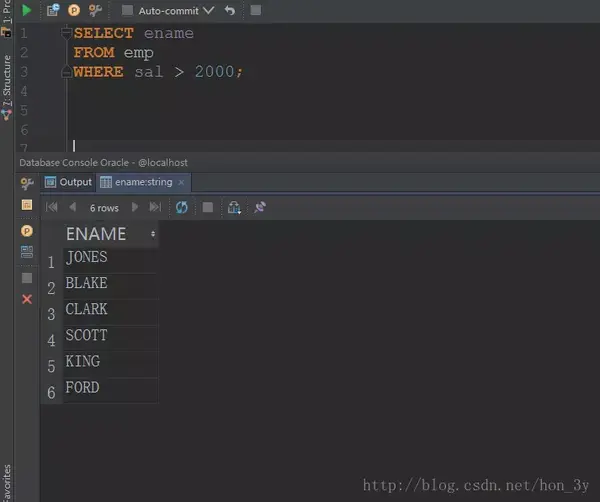
查询工资大于2000的员工姓名
SELECT ename
FROM emp
WHERE sal > 2000;
过程:首先查询emp表的所有结果什么是数据库中的事物,使用selection操作过滤出薪水大于2000的结果,最后使用projection操作获取薪水大于2000的员工姓名!
分配
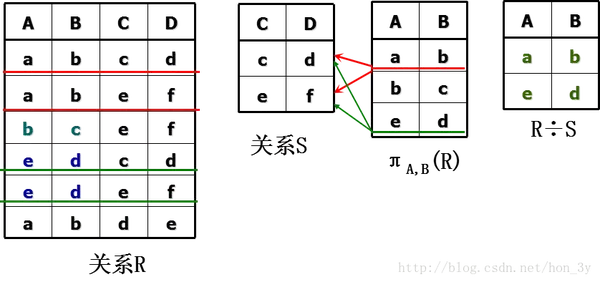
除法运算的实际应用我还没弄明白~~~ 如果谁知道数据库中哪里可以用到除法运算,请告诉我。 .
我们也来了解一下除法运算的过程:关系R有ABCD,关系S有CD。 首先对AB进行投影(因为S有CD),然后对AB和关系S进行投影的结果进行笛卡尔积运算。 如果在R关系中找到笛卡尔积运算记录找到对应的记录,那么投影的AB就是结果!
联营
连接运算实际上是在笛卡尔乘积运算的基础上限制条件(某列大于、小于或等于某列),只匹配满足条件的条件,从而得到结果!
自然联系
自然连接是一种特殊的连接操作,其限定条件为【某列等于某列】。 我们经常使用自然联系。 消去笛卡尔积其实是天然的联系!
SELECT *
FROM emp, dept
WHERE dept.deptno = emp.deptno;设置dept表的deptno列和emp的deptno列相同【这就是天然的联系】
文中如有不妥之处,欢迎指正,多多交流。 习惯在微信上看技术文章,想获取更多Java资源的同学可以关注微信公众号:Java3y
 上一篇
上一篇 








