

mysql数据库直接拷贝-直接初始化和拷贝初始化
嗯? 这是什么技术(What)?
为什么会有这项技术? 我们已经有了那么多的解决方案(Method),为什么还要用它(Why)呢?
如果这个技术这么好,我们恰好有一个场景可以用到这个技术,我们的系统可以被乐观优化,那我们怎么用(How)呢?
想必有些同学已经觉得这些问题很眼熟了。 是的,这就是黄金法则提出的三个问题。 对于每一个新事物,我们先从这三个问题出发去理解它,这样更有利于理清事情的本质,进而改正。 理解的态度,不是因为新,因为大家都认同,所以要理解…… 说了这么多前奏,我们可以开始了。 今天我们就带着黄金圈法则提出的三个问题来了解一下这个领域的MySQL数据库复制技术mysql数据库直接拷贝,再结合实际应用展开一些问题。 本文只是结合我们自己熟悉的皮毛,以抛砖引玉的态度分享给大家。
什么?
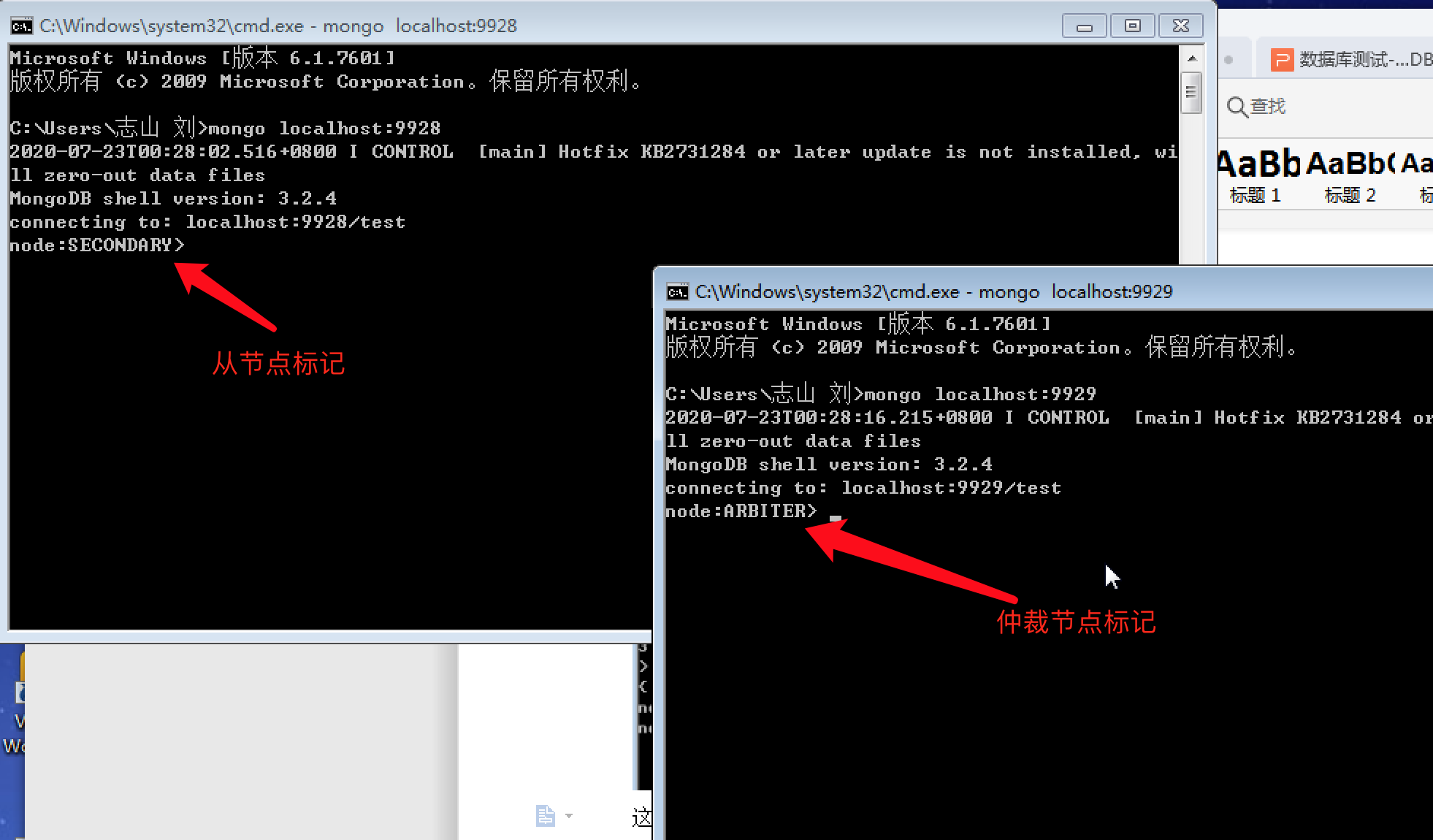
MySQL 复制可以将一台 MySQL 数据库服务器的数据复制到一台或多台其他数据库服务器。 前者通常称为Master,后者通常称为Slave。
MySQL复制示意图
复制的结果是集群中所有数据库服务器得到的数据理论上是一样的,都是同一份数据,只是存在多份。 MySQL 的默认内置复制策略是异步的。 基于不同的配置,Slave不一定非要和Master保持连接才能持续复制或者等待复制。 我们指定复制所有数据库,部分数据库mysql数据库直接拷贝,甚至是某个数据库的某个部分。 桌子。
MySQL复制支持多种不同的复制策略,包括同步、半同步、异步和延迟策略。
同步策略:Master等待所有Slave响应后再提交(MySql提交DB操作通常是先将操作事件写入二进制日志文件再提交)。
半同步策略:Master在commit前至少等待一个Slave的响应。
异步策略:Master无需等待Slave响应即可提交。
延时策略:Slave至少要滞后Master指定的时间。
MySQL复制同时支持几种不同的复制模式:
基于语句的复制,Statement Based Replication (SBR)。
基于行的复制 (RBR)。
混合副本(Mixed)。

这个问题其实就是MySQL复制有什么好处。 我们可以将复制的好处归因于以下几类:
性能方面:MySQL复制是一种scale-out的解决方案,即“横向扩展”,将原来的单点负载分散到多台slave机器上,从而提高整体的服务性能。 这样,所有的写操作,包括UPDATE操作,都必须发生在Master服务器上。 读取操作发生在一台或多台 Slave 机器上。 这种模式可以在一定程度上提高整体服务性能。 Master服务器专注于写入和更新操作,Slave服务器专注于读取操作。 同时,我们可以通过增加Slave服务器的数量来提高读取服务的性能。
防腐蚀:由于数据被复制到Slave,Slave可以暂停复制过程,进行数据备份,从而防止数据损坏。
故障恢复:如果其中一个slave同时挂掉了,我们仍然可以从其他slave上读取。 如果配置了主从切换,我们可以选择一个slave作为master,在master挂掉后继续提供写服务。 这大大提高了应用程序的可靠性。
数据分析:Master可以存储实时数据,从Slave读取数据分析,不会影响Master的性能。
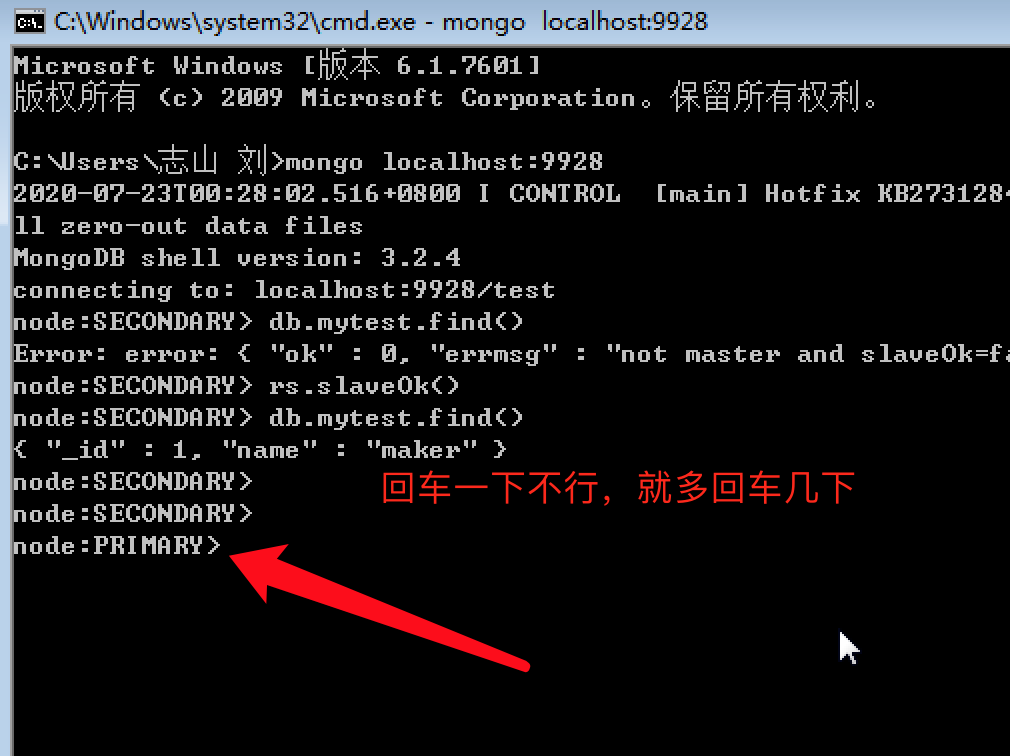
这里只介绍MySQL复制是如何工作的。 至于配置,网上有很多相关介绍。 具体应用请读者参考。 让我们以最常用的基于二进制的复制为例。
MySQL复制工作示意图
请点击输入图片描述
请点击输入图片描述
MySQL复制过程大致如下:
首先,主库会在每个准备提交的事务完成数据更新操作之前,将数据更改操作记录在二进制日志中,这些日志以二进制形式记录数据更改事件。 值得一提的是,二进制日志中记录的顺序实际上是事务提交的顺序,而不是SQL执行语句的顺序。 主库记录二进制日志后,会告诉存储引擎事务可以提交了。
然后,备库会启动一个IO线程,之所以称为IO线程,是因为这个线程专门负责IO相关的工作,包括与主库建立连接,然后在主库上启动一个专门的binary dump线程。 线程会不断的读取二进制日志中的事件发送给备库的IO线程,备库的IO线程会将事件记录在relay log中。
备用数据库中会打开一个名为 SQL 的线程。 该线程的作用是读取relay log中的DB操作事件,并在备库中执行,从而实现数据更新。
通常情况下,复制发生的主数据库服务器和备用数据库服务器中共有三个线程在工作。
上面我们已经理解的是复制? 为什么要复制? 如何复制? 这三个问题都涵盖了。 接下来,基于以上介绍,我们提出一些在实际应用中可能会出现的问题,来思考如何解决。 博主自问自答的方式-。 -
提问时间

问题一:虽然通过复制模型扩展slave可以提高读能力,但是不能提高写能力。 写到瓶颈怎么办?
答:我们首先会得出结论,这种复制模型对于写少读多的应用程序是非常有利的。 其次,遇到这种问题,我们可以对数据库进行数据库操作。 所谓分库就是把业务相关性比较高的表放在同一个数据库中。 比如之前的数据库有A、B、C、D四张表,A表和B表有比较大的关系,而C表和D表有比较大的关系,这样我们就把C表和表分开了D 成一个单独的数据库。 这样我们就可以把原来的单点写变成双点写或者多点写,从而减少原来主库的写负载。
问题2:因为复制有延迟,肯定会出现主库写了,从库还没有读的情况。 遇到这个问题怎么办?
答:MySQL支持不同的复制策略,基于不同的复制策略达到的效果也不同。 如果是异步复制,MySQL无法保证从库能立即实时读取到主库写入的数据。 这时候,我们就不得不权衡取舍,根据不同复制策略的优劣做出取舍。 所谓优劣,就是我们是否对从库中读取的实时性有那么高的要求。 如果是这样,我们可以考虑使用同步复制策略,但是这种策略相比异步复制策略会大大减少主库的响应时间。 和性能。 我们可以在应用程序的设计层面避免这个问题吗?
问题三:不同复制模式的优缺点是什么? 我们如何选择?
A:Statement-based replication其实就是把主库上执行过的SQL重新执行到从库上。 这样做的好处是实现起来简单,但也有缺点。 SQL在从库执行时,在主库执行的结果明显不同,注入此类问题可以类推。 第二个问题是这种复制必须是串行的。 为了保证串行执行,需要更多的锁。
基于行的复制时,二进制日志实际上记录的是数据本身,这样才能从库中获取到正确的数据。 这种方法的缺点是显而易见的。 数据必须存储在二进制日志文件中,这无疑增加了二进制日志文件。 大小,同时增加了IO线程负载和网络带宽消耗。 与基于语句的复制相比,基于行的复制还有一个优势是不需要重放查询,节省了大量的性能消耗。
无论哪种复制模式是完美的,如何选择日志都可以在了解它们的优缺点后进行权衡。
问题4:只有三个线程完成复制过程。 对于Master来说,写是并发的,有一个IO线程记录所有并发的数据变化事件。 这个IO线程会不会被耗尽? 当一个master对应多个slave时,会在master中调用多个IO线程,这无疑会增加master的资源开销。 如果出现事件堆积,即事件太多,来不及及时发出怎么办? 另外,slave端的IO线程和SQL线程也会有并发的data change事件对应主库,slave端会处理单线程的问题。 这个时候slave线程会不会被耗尽?
答:确实会出现以上问题。 上面的第一和第二个问题其实就是写负载的问题。 当事件过多时,从库的延迟会变大。 据说Slave单SQL线程的问题是有参数的。 打开并行操作,你可以确认这一点。
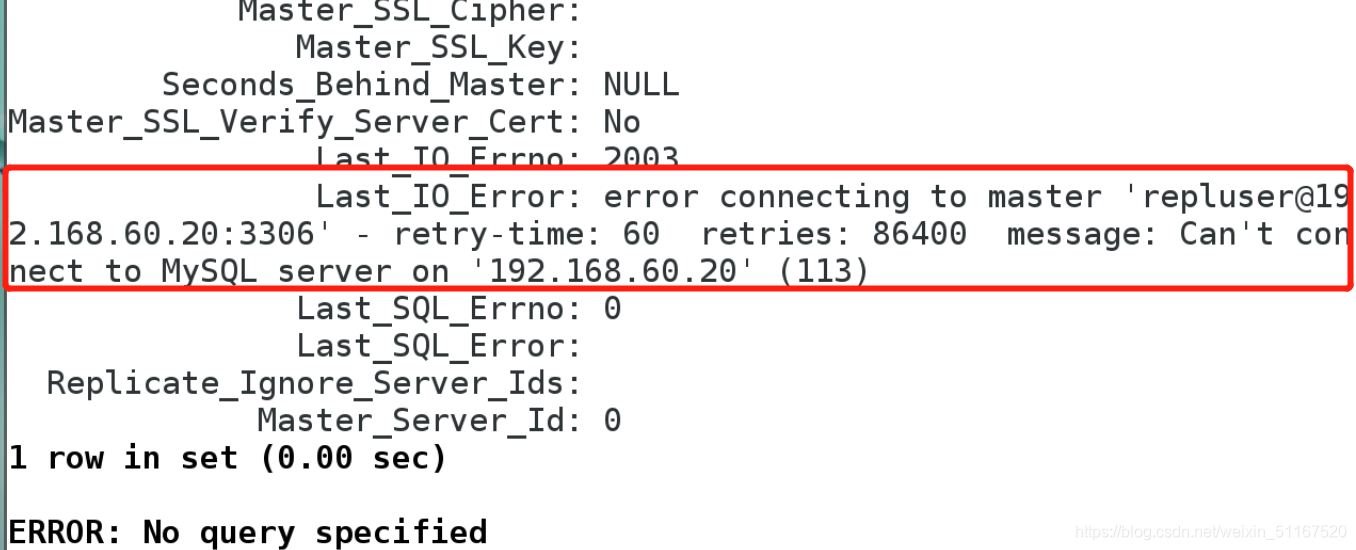
问题5:对于复制过程中可能出现的问题,主库在写入二进制日志文件后会同时保存二进制日志的偏移量,但是断电后,二进制日志文件就没有了刷新到磁盘。 主库重启后,尝试读取从库offset处的binary log,会读取失败。 如何解决这个问题呢?
答:首先,如果你开启了sync_binlog选项,同时设置innodb的innodb_flush_log_at_trx_commot=1,可以保证二进制日志文件写入磁盘,但是MyISAM引擎可能会导致数据损坏。 如果不启用该选项,可以设置从库的二进制偏移量作为下一个二进制日志文件的开始,但无法解决事件丢失的问题。
问题6:当从库意外关机或重启时,返回读取master.info文件,找到上次停止复制的位置。 这也会有问题。 如果master.info不正确,会导致复制数据不一致,遇到这个问题怎么办?
答:这个问题可以通过两种方式解决。 一是控制master.info在从库关机或非计划重启时同步到磁盘,这样下次启动时就不会读到错误的信息。 ,这有助于降低出错的可能性。 另外,很难找到正确的复制位置,我们也可以选择忽略错误。

请点击输入图片描述
请点击输入图片描述
 上一篇
上一篇 








