

什么是数据库管理系统-在人工管理阶段 数据是
作为中文全文搜索技术的开拓者,天瑞思信息技术有限公司一直致力于高性能搜索引擎的研发。 早期开发的全文检索系统TRS数据库服务器获得国家科技进步二等奖。 随着大数据时代的到来,TRS创新研发了以检索为核心的TRS海北大数据管理系统,一经推出便获得了市场的高度认可。 今天,经过多次版本升级,海贝发布了TRS海贝大数据管理系统V9.0。 该系统吸收了TRS在信息检索和NLP领域多年的技术积累。 不仅高效安全,还集成了很多开源检索系统所不具备的企业级功能,可有效降低用户的系统建设成本、开发成本和运营成本。 维修费用。
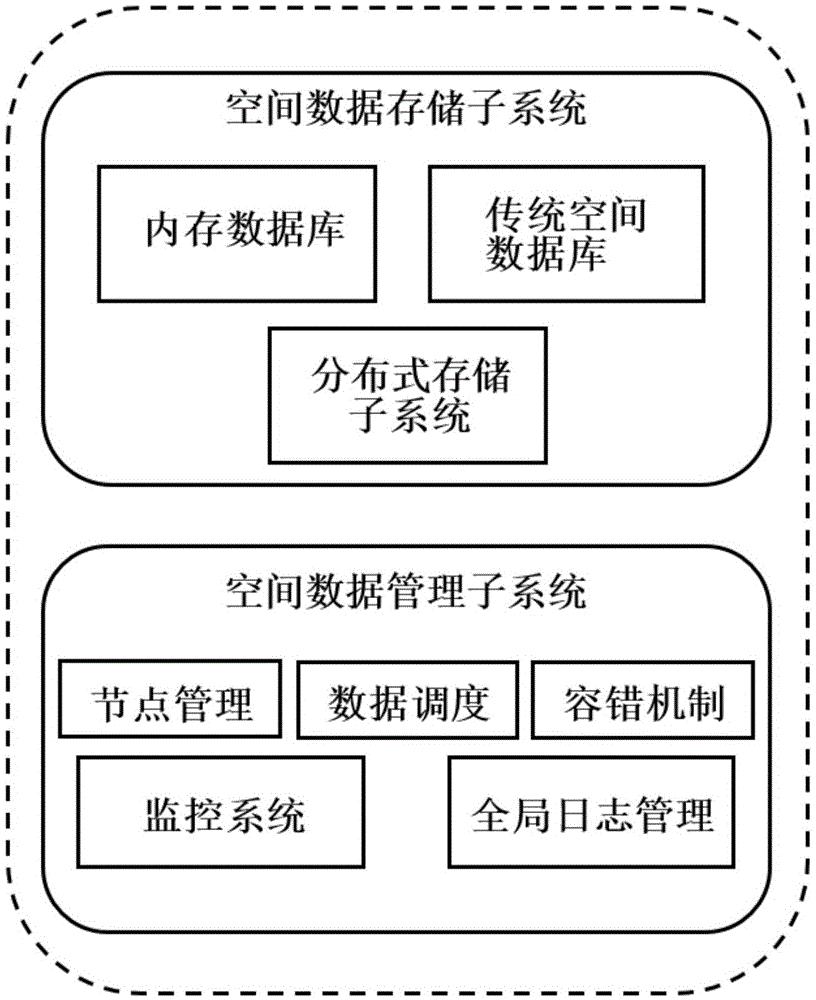
在数字经济时代,数据成为组织数字化转型成功的关键。 然而,随着大数据的蓬勃发展,我们面临着以下挑战: 非结构化数据呈爆发式增长。 目前,非结构化数据已占数据总量的90%,并保持高速增长。 或者来不及处理,处于闲置状态,价值不明。 随着数据资产越来越受到重视,对非结构化数据处理的实时性和系统扩展性的要求也越来越高。 因此可以对非结构化数据进行统一处理,利用集群解决弹性扩展问题。 数据平台建设已成大势所趋。 服务器硬件不断升级。 目前服务器硬件更新换代快,主要体现在CPU主频的不断提升和核心数量的增加; 内存价格持续下降,单机内存容量不断提升; 高性能SSD存储逐渐成为检索系统的标配。 数据库作为数据处理的关键部分,如何设计才能充分发挥硬件的性能? 新技术不断涌现面对各种新技术层出不穷的现状,例如:压缩算法:LZ4和Snappy,开源大数据技术:HDFS、MapReduce、Hbase……以及虚拟化、内存计算,如何整合这些技术提高软件运行效率? 丰富多样的数据类型 互联网上的数据种类繁多,不仅包括传统的格式化数据,还包括来自互联网的网络日志、视频、图片、地理位置等。 如何整合这些数据,打破数据孤岛? 数据安全是重中之重 过去几年,数据库服务器被黑客入侵,导致数据泄露或删除。 随着大数据的持续快速增长,对数据物理安全的要求越来越高,从而对数据的多副本和容灾机制提出了更高的要求,迫切需要解决数据安全的机密性问题. 面对以上挑战,我们可以发现,随着数字化、智能化时代的到来,数据存储并不是大数据发展的最终目标。 数据存储是为了更好的进行数据检索和数据分析什么是数据库管理系统,充分挖掘非结构化数据。 数据的价值。 基于此,TRS海北大数据管理系统V9发布,安全、高效、专业的搜索引擎。


单一分词实现跨语言检索 分词是检索系统的核心技术,虽然ES、Solr等开源检索系统也为大多数语言提供了不同的分词器。 而海贝内置的TRS分词器不仅可以支持中文、日文、韩文等块文本,还可以处理英文、法文、德文等拉丁文,以及藏文、蒙文等少数民族语言。 , 和维吾尔语。 它真的可以做到。 单一分词器处理所有语言,大大简化了系统的开发和运维。 这里我们以一个专利项目为例,该项目在全球收集了2.5亿件专利,包括中国专利、英国专利、日本专利和其他多国专利。 如果使用Solr或ElasticSearch等开源项目来构建,需要对每种语言分别进行处理、存储和检索。 那么无论是数据处理、应用开发还是后期运维,随着语言的增多,工作量都会成倍增加。 而采用海贝大数据管理系统的知识产权大数据及智能服务系统,仅需一个数据库即可应对所有语种。 自主可控的创新技术保障数据安全海贝从设计之初就非常重视数据安全。 系统采用多副本机制解决数据可用性问题,通过数据校验和WAL技术解决数据完整性问题。 管理机制、HTTPS、加密存储等机制解决了数据访问和数据存储的保密问题。 海贝还具有其他同类产品所不具备的独特的安全特性,例如用户隔离:系统支持对用户数据进行物理隔离和逻辑隔离,既可以解决多租户之间的访问安全,又可以防止多租户之间的相互影响用户。 提高系统可用性。

海贝作为自主可控的本地化加密数据引擎,支持数据和索引的完全加密,支持国产加密卡,提供金融级数据安全保障。 先进的性能实现最高效的大数据管理 目前,大部分数据分析都是通过各种查询和统计来实现的,也就是说,只要能做到快速查询和统计,90%的数据都可以满足。 以上数据分析业务。 海北以全文检索技术为核心构建,不仅可以实现全字段索引,还支持任意维度的组合查询。 数据查询和分析效率远高于其他大数据管理系统。 同时,海北引入了内存索引、列存储、索引分片等技术,进一步提升数据存储、检索、分析的效率。 海贝内置分时归档视图,不仅可以实现冷热数据的自动分区,还支持多种存储混合使用,提供高效的检索服务; 通过镜像数据库,用户可以通过简单的配置实现读写分离、数据库大小和访问隔离等,大大减少数据处理和查询之间的CPU、内存、IO等冲突,避免检索滞后的问题由数据存储引起的; 通过构建超大规模集群,降低系统架构资源消耗; 通过对各类服务器硬件的配套支持,可以充分发挥硬件的优良性能。 专业的非结构化数据和跨数据类型检索 海北大数据管理系统不仅吸收了在信息检索和NLP领域的多年积累,还集成了很多开源检索系统所不具备的企业级功能,可以有效减少用户的系统建设成本、开发成本和运维成本。

此外,在检索能力方面,通过研发团队的不断努力,海北不再是一个简单的文本检索系统。 除了常规的数值、日期、文本类型、地理位置信息等,海贝还支持IP地址检索、二进制检索、图像特征检索等多种数据类型的检索。 智能深度学习引擎提升网络空间治理能力。 随着网络审查日趋严格,一些不法分子常常将一些敏感词转化为同音字或同义词进行发布,或者以图片的形式发布违法文章,企图逃避监管。 针对这种情况,海贝集成了深度学习引擎,可以对图片中的文字进行OCR识别,还可以提取图片或文字的特征数据,通过基因编码存储在海贝数据库中,成功实现图像相似度检索功能。 并具有拼音搜索、同义词搜索等功能,让不法分子无处遁形。 产品聚合,生态连接更多可能 海贝可以与TRS的各类产品进行深度应用集成,打造强大的数据服务能力。 例如在数据导入方面什么是数据库管理系统,与TRS ETL对接,与TRS CKM相结合,是数据处理和流转的有力工具; 在数据呈现方面,与TRS WAS对接,可实现数据快速发布、RESTFUL接口、权限管理和流量控制; 全新的数据监控系统,可以进行数据监控、进程监控、服务监控、日志分析、安装部署等; 在数据分析方面,对接TRS水晶球分析师、TRS网检大数据分析平台、TRS海融智能媒体平台,形成行业应用解决方案,为用户提供便捷、高效的服务。
目前,TRS海北大数据管理系统已广泛应用于安防大数据、媒体大数据、政务大数据等多个细分行业。 公安部、新华社、市场监督管理局、海关总署、专利局、商标局等一系列重量级客户都选择了海贝产品; 企业信用信息公示系统、专利检索系统等国家主要基础数据库均建立在TRS海北大数据管理系统之上。 某网络安全项目:数据量巨大,数据类型丰富,单集群每天新增数据超过60亿条。 本项目采用海贝大数据管理系统进行网络数据安全管理。 十个节点到几百个节点; 数据量巨大,单集群每天新增数据超过60亿条,每天处理数据超过20T,记录总数超过万亿,存储数据总量达到PB级; 项目分布广泛,已在全国多个省市开展。 经过一段时间的项目运行,在多个同类产品的对比中,用户对海贝大数据管理系统赞不绝口。 某项目:超大规模集群,大幅降低资源消耗在某项目系统建设中,单个集群的服务器数量达到了600台。众所周知,在分布式系统中,一个集群中的机器越多单个集群,系统需要更多的工作来协调机器之间的通信。 通过架构调整和系统优化,我们大大降低了这部分的资源消耗,使超大规模集群成为可能。 信用中国项目:大量并发访问,日搜索量超10亿。 “信用中国”网站由国家发展和改革委员会、中国人民银行指导,国家信息中心主办。 是政府表彰诚信、惩戒失信的总窗口。 网站提供全国(亿级以上)企业信用信息、信用代码及相关文章的公开查询服务。 2018年底,“信用中国”搜索服务迁移至TRS海北大数据管理平台。 在信用中国项目中,海北单集群日搜索量超过10亿。 其中单台服务器每秒并发检索超过1K。
 上一篇
上一篇 








