

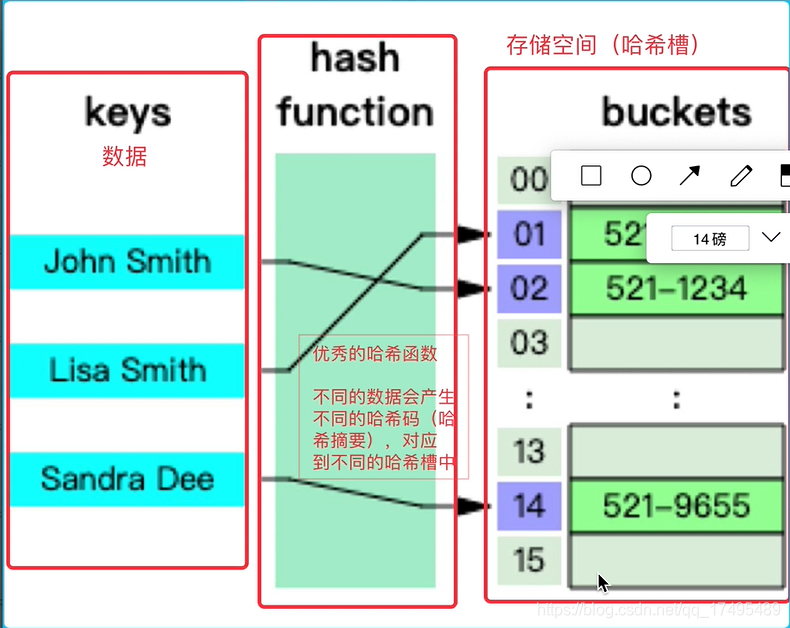
数据库count 1-mysql count(1) count(*)区别
发布时间:2023-02-08 22:41 浏览次数:次 作者:佚名
在数据库的使用中数据库count 1,Count()函数用于统计数据表的记录数,返回符合指定条件的行数。
三个Count()函数count(1),count(*),count(列名)区别1,count(1),count(*)
当数据表的数据量很大时,使用count(1)比count(*)分析数据表需要更多的时间。 从执行计划来看,count(1)和count(*)的效果是一样的,但是count(1)的实际执行时间比较少(1w以内的数据量)。 如果count(1)是聚簇索引,id,肯定比count(1)快,但差别很小。 因为count(*)会自动优化赋值给某个字段,所以没必要用count(1),而count(*)sql会帮你完成优化,所以count(1)基本没区别) 和计数 (*)!

2. count(1), count(列名)

两者的主要区别在于:count(1)统计数据表中所有记录的条数,包括字段为null的记录; count(列名) 统计该字段在表中出现的次数,当该字段为null时将忽略,不统计空记录。

3. count(1), count(*), count(列名)
在执行效果方面:
在执行效率方面:
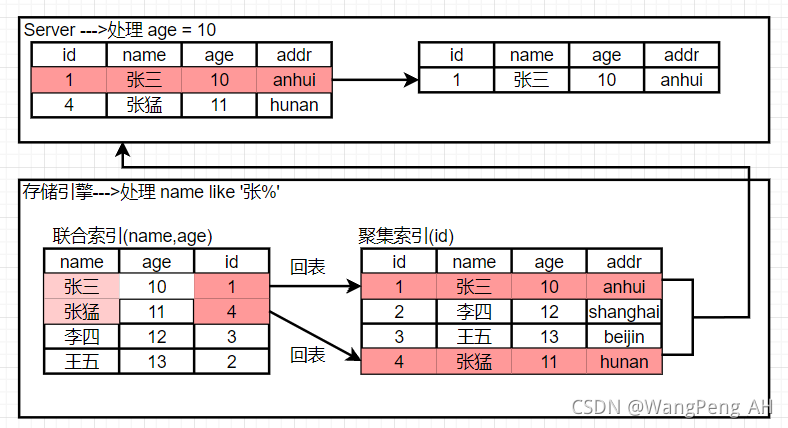
count(primary key) 不一定比 count(rest indexes) 快:
索引是一个B+树结构,以块为单位存储。 假设块大小为1K数据库count 1,主键索引大小为4B,有一个字段A,索引大小为2B。 同一个block可以存储256个主键索引,但是可以存储512个字段A的索引。假设总数据为2K,则表示主键索引占用8个block,而A字段索引占用4个block。 使用主键索引进行统计时,需要经历更多的块,更多的IO次数,效率比A字段索引慢。
Count() 函数总结
 上一篇
上一篇 








