

人工智能硬件架构-gpu硬件架构
摩尔定律从2003年开始放缓。为了延续性能倍增、功耗减半,Intel CPU采用多核来实现。然而,到2015年以后,多核也达不到了。内核数每增加一倍,运算性能并不能成倍增长。因此,业界需要寻找新的方法来实现延续人工智能硬件架构,比如针对应用进行硬件加速。QPOednc
人工智能的硬件加速,如果想要做得好的话,需要具备三个条件:运算能力很强,数据传输高效,存储器带宽高。业界衡量性能的指标包括性能功耗比和性能价格比。QPOednc

QPOednc
Achronix Semiconductor公司市场营销副总裁Steve MensorQPOednc
QPOednc
硬件加速应用六大应用场景
日前,Achronix Semiconductor公司市场营销副总裁Steve Mensor告诉记者,硬件加速应用有几大类应用场景:QPOednc

1.云的加速。涉及压缩解压缩、区块链和安全等,需要很高的运算能力和功耗成本比。QPOednc
2.边缘计算。很多应用由于需要低延迟,不允许将数据传到数据中心处理,而需要在边缘处理,并且需要低功耗。QPOednc
3.存储。有些应用需要高效率,因而要求在存储器里进行数据处理。QPOednc
4.5G基础设施。5G网络中的BBU(基带处理单元)和RRU(射频拉远单元),其协议处理有很大不确定性,需要用FPGA来编程。QPOednc
QPOednc
5.传统的网络加速需要用FPGA,而现在网络中出现了新的智能网卡,要求在发给服务器之前进行加解密、压缩解压缩等各种处理。QPOednc
6.自动驾驶。涉及人工智能、数据运算和传感器融合等,需要具有可编程性。QPOednc
人工智能/机器学习应用为何要用FPGA?
FPGA在人工智能/机器学习(AI/ML)上扮演重要角色。AI涵盖各种应用和层面,工业、教育、政府、农业等各行各业都可以运用。个人电脑在1980年到2000年增长很快。从2000年开始(包括智能手机的出现),无线互联网增长更快。而在未来,据估计,随着5G的到来,AI的增长又将会更快。据估计,在半导体业务方面,到2024年,AI将占有约500亿美元市场。QPOednc
Mensor介绍,硬件加速从实现上看可以有几种不同选择:CPU、GPU、FPGA和ASIC。CPU最有灵活性,能够覆盖各种不同应用,但它的能力(效率)最弱。ASIC的成本、性能和功耗最好,但它不能改变。目前AI算法层出不穷,ASIC不能满足各种要求。QPOednc
若要同时具有可编程性和效率,则可以采用GPU和FPGA。在功耗和效率上,FPGA比GPU更强。尤其是在AI推理上,对于低精度场景,FPGA的性能功耗比比GPU大16倍。“GPU更适合用在服务器侧,而FPGA则更适合用在边缘侧。”Mensor补充说。FPGA适合做推理,GPU适合做训练。QPOednc
7nm eFPGA性能增强
日前,Acronix推出新的7nm架构IP——Speedcore 7t,在功耗、性能和裸片尺寸(PPA)上均有改进。QPOednc
从工艺上看,7nm比16nm快60%。同时,它针对AI/ML做了新的架构改进(第四代架构),对于AI/ML应用,性能比16nm增长3倍。此外,相比16nm,其功耗降低50%,裸片面积减少2/3。QPOednc
7nm相对16nm在架构上做了很大改变,例如算逻单元(ALU)增加一倍,布线布局做了改善,并且针对AI/ML运算增加了新的模块(详见下图)。ALU和MAX()针对AI/ML更有效率,其他四个则适用于所有应用,他补充说。QPOednc
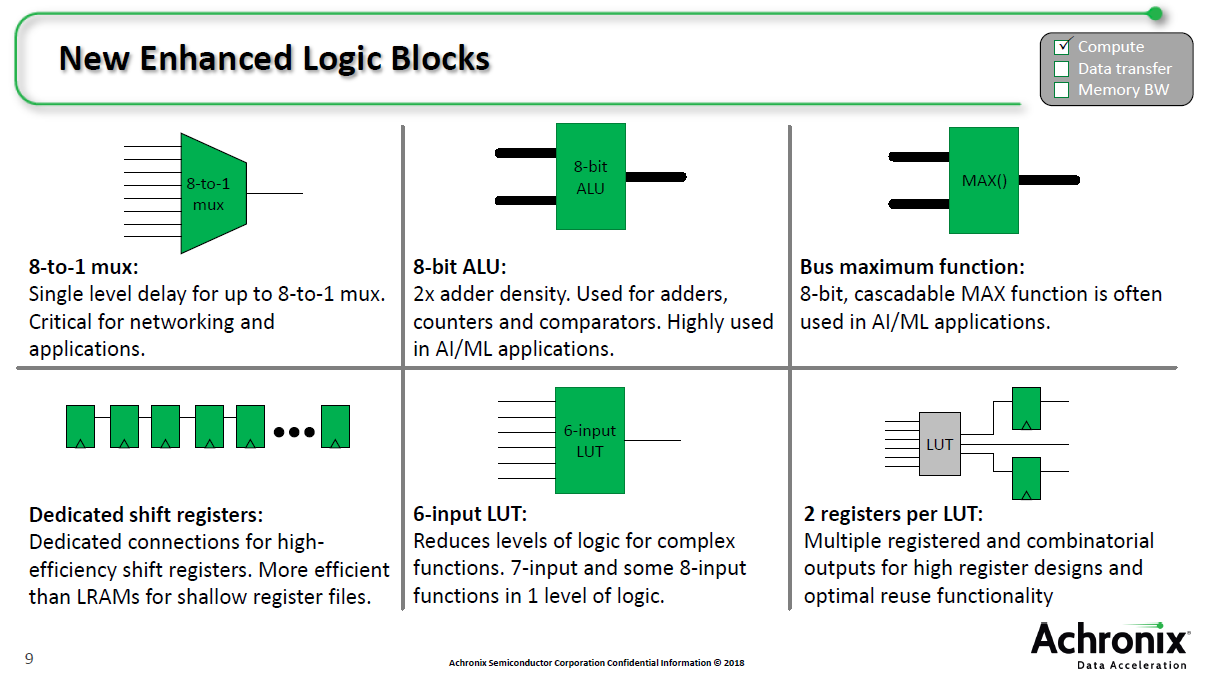

QPOednc
从走线架构来看,相对于传统架构,它增加了bus走线,这对很多应用都很有用,例如现在有的AI应用数据高达512位。Bus走线是在传统走线之上,是另外一层,没有占用传统LE(逻辑单元)和开关等等。尤其是在AI/ML方面更有效率,Mensor指出。QPOednc
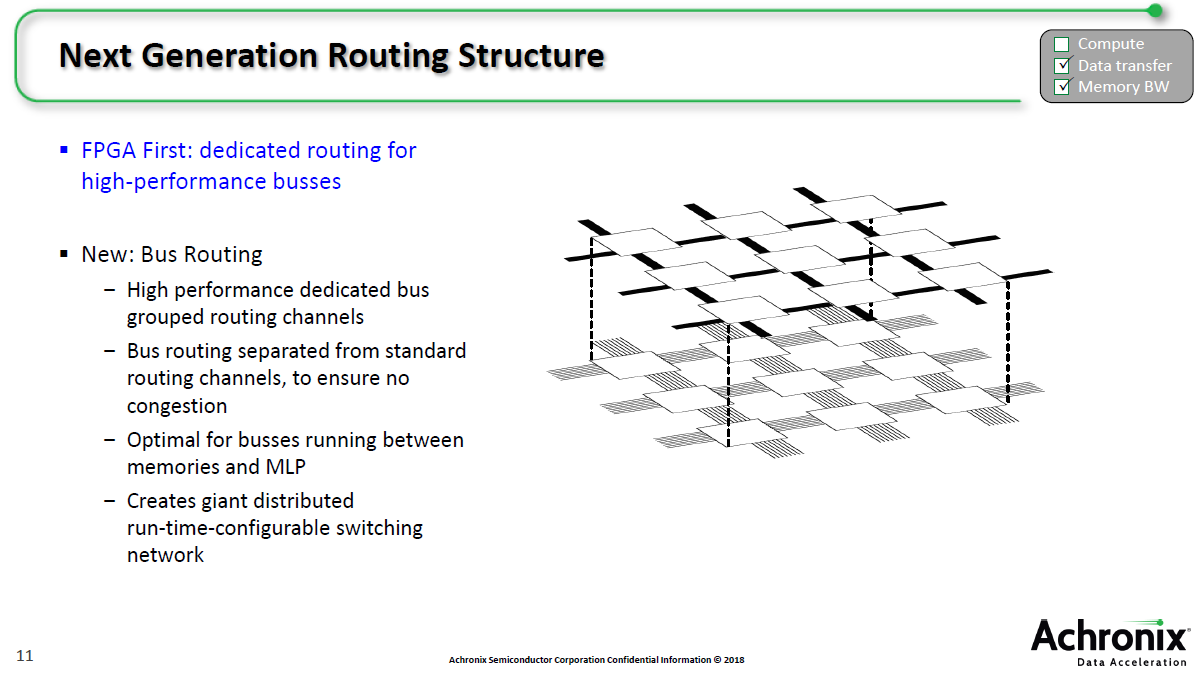
QPOednc
除了bus走线以外,它还增加了bus mux,例如4进1出(不固定,也可以是2或3个)。AI/ML应用可能有几个不同存储器输入,如果用传统方法来做,则可能消耗很多LUT/LE资源以及布线布局资源。而新的bus布线则不会占用到这些资源。此外,其性能比传统方法实现2倍增长。QPOednc
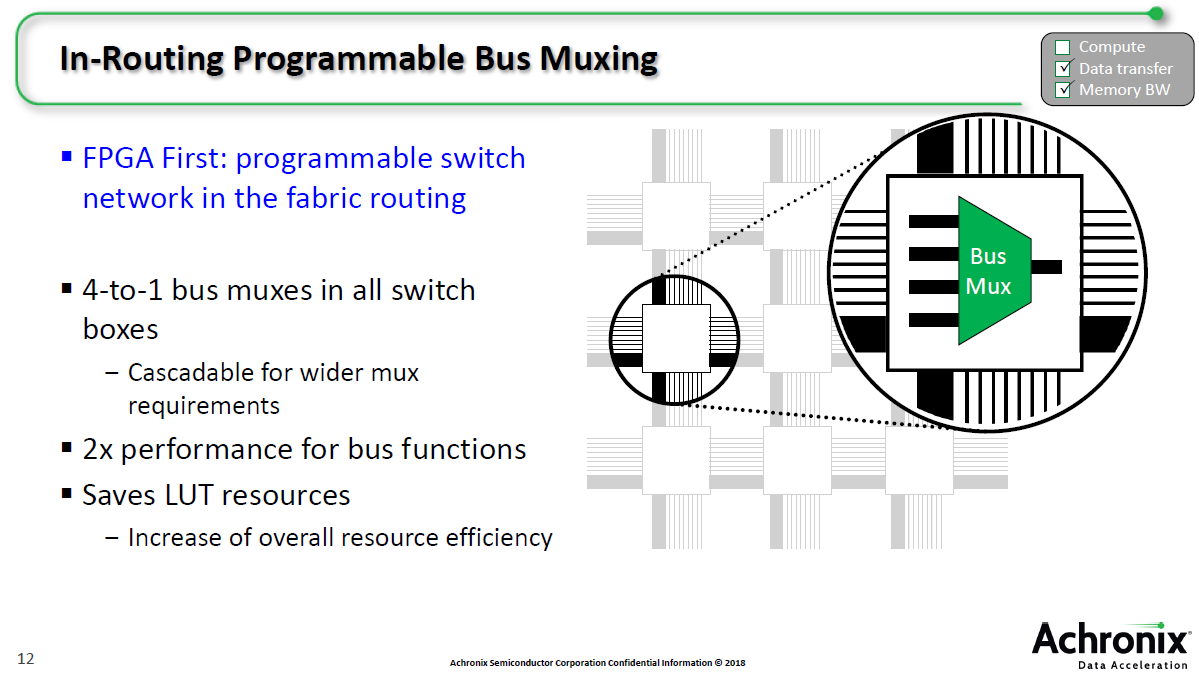
QPOednc
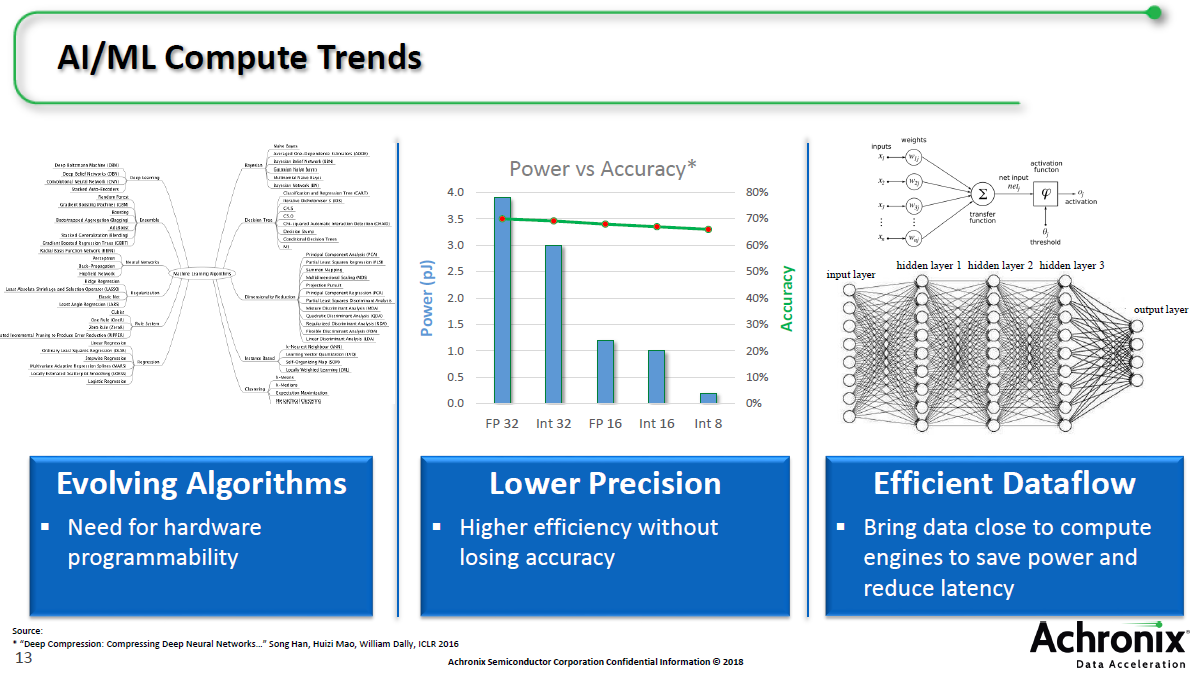
AI/ML计算趋势
下面来看AI/ML计算趋势。首先来看算法,例如CNN、DNN、RNN等,对于图像和语音等不同应用需要用到不同算法。然后是精度,Int 32相比Int 8,其功耗会高10倍。新的算法带来精度降低,而准确性却损失很小,是发展趋势。而Speedcore 7t IP对所有算法都提供支持,尤其是对小的算法来说很有效率。除了运算能力以外,AI/ML涉及大量的矩阵乘运算,在存储器和FPGA之间有大量的数据传输人工智能硬件架构,因此两者要靠得很近,从而提高效率。QPOednc
QPOednc
下一代DSP模块针对矩阵乘的优化
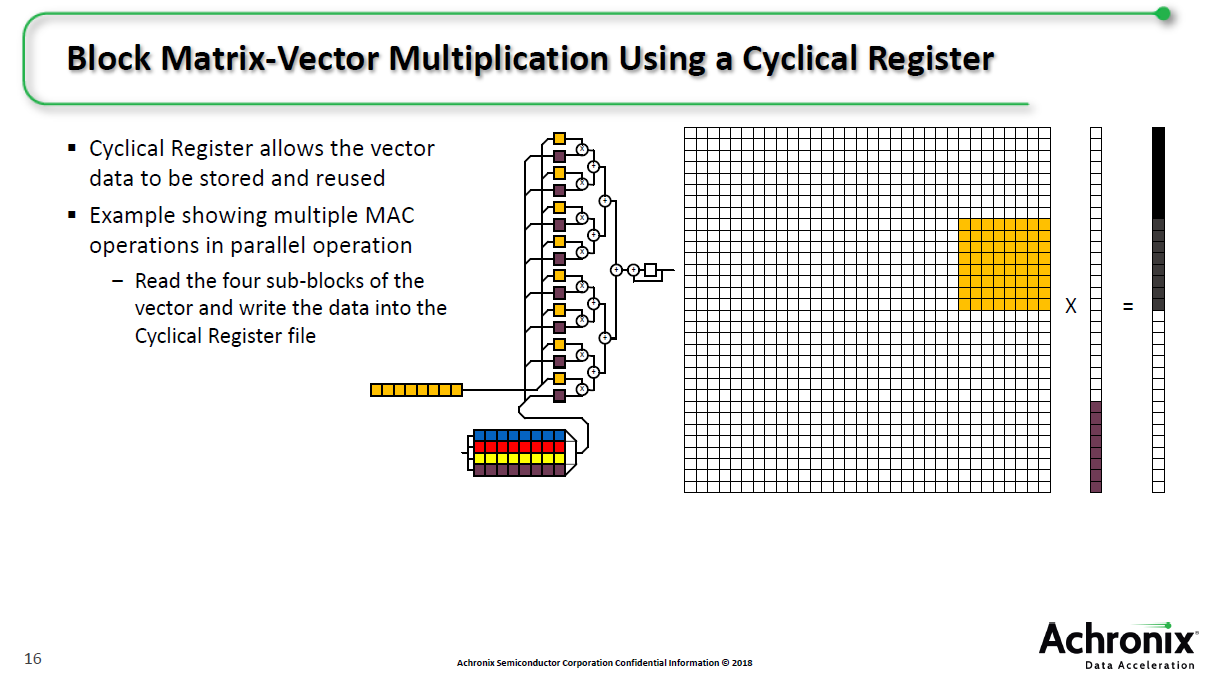
下一代DSP模块——MLP(机器学习处理器)——针对矩阵乘运算进行优化,可以支持多种不同精度,性能达750MHz,并且支持不同类型(浮点、定点)运算。一个MLP可以支持1个16*16、8个8*8、12个6*6或16个4*4,满足不同精度的乘方。QPOednc
传统上,做矩阵乘运算,一行一列相乘得到一个数据,但是数据很宽,需要经过多次运算才能得到一个数据。对于MLP来说,则可以采用块的方式做。对于1个时钟周期,可以实现6倍运算增长。QPOednc

QPOednc
MLP和存储器放在一起。传统架构去做矩阵乘,性能受制于DSP、MLP以及走线。现在把存储器和MLP放在旁边,数据传输很快,不需要经过LE。另外,MLP和MLP之间走线类似ASIC连线。要做更宽运算,这种走线与传统相比可以将性能提升不小。QPOednc
总的来说,这种架构对于AI/ML运算具有可编程性,可以根据性能、功耗和精度进行权衡。矩阵乘运算可以将参数放在MLP存储器中运行,采用级联方式可以一次性完成,获得几倍性能提升。MLP和存储器及MLP和MLP之间绑在一起,这样就不用经过LE,速度很快。另外,MLP可以支持不同精度(如4、6、8比特),非常灵活,而CPU只能支持某种比特乘法。另外,它支持多重取整和饱和,不需要在LE中再做另外一层运算。QPOednc
除了用MLP做乘法以外,也可以用LUT来做。传统用LUT做8*8运算,需要36个6输入LUT。现在用新的架构来做,如果是6输入LUT,只需要用到一半,即18个LUT即可。甚至精度更低一点则会更有效率。QPOednc
此外,Speedcore IP资源可以定制。Acronix提供Speedcore Builder Tool工具供用户进行参数选择。一旦确定需要多少资源,一个半月即可实现IP交付。这个架构现在是针对7nm所做,在2019年年中还会过渡到16nm。QPOednc
总结
摩尔定律现已打破。未来性能增长需要依赖架构上的改变,即需要利用可编程的硬件加速器来实现性能增长。QPOednc
对于AI/ML应用,需要有高运算能力的运算单元、高效高速数据传输,以及高存储带宽。QPOednc
Speedcore 7t在第四代架构中做了很多AI/ML优化。基本性能提高60%,AI/ML性能提高3倍,功耗减半,面积缩减到1/3等。可以使AI/ML应用设计很有效率,在运算能力和功耗等方面都有很大改进。QPOednc
 上一篇
上一篇 








