

神经网络是人工智能-bp人工神经网络模型
背景
对人类中枢神经系统的观察启发了人工神经网络这个概念。在人工神经网络中,简单的人工节点,称作神经元(neurons),连接在一起形成一个类似生物神经网络的网状结构。
人工神经网络目前没有一个统一的正式定义。不过,具有下列特点的统计模型可以被称作是“神经化”的:
具有一组可以被调节的权重,换言之,被学习算法调节的数值参数,并且
可以估计输入数据的非线性函数关系
这些可调节的权重可以被看做神经元之间的连接强度。
人工神经网络与生物神经网络的相似之处在于,它可以集体地、并行地计算函数的各个部分,而不需要描述每一个单元的特定任务。神经网络这个词一般指统计学、认知心理学和人工智能领域使用的模型,而控制中央神经系统的神经网络属于理论神经学和计算神经学。
在神经网络的现代软件实现中,被生物学启发的那种方法已经很大程度上被抛弃了神经网络是人工智能,取而代之的是基于统计学和信号处理的更加实用的方法。在一些软件系统中,神经网络或者神经网络的一部分(例如人工神经元)是大型系统中的一个部分。这些系统结合了适应性的和非适应性的元素。虽然这种系统使用的这种更加普遍的方法更适宜解决现实中的问题,但是这和传统的连接主义人工智能已经没有什么关联了。不过它们还有一些共同点:非线性、分布式、并行化,局部性计算以及适应性。从历史的角度讲,神经网络模型的应用标志着二十世纪八十年代后期从高度符号化的人工智能(以用条件规则表达知识的专家系统为代表)向低符号化的机器学习(以用动力系统的参数表达知识为代表)的转变。
历史
沃伦·麦卡洛克和沃尔特·皮茨(1943)基于数学和一种称为阈值逻辑的算法创造了一种神经网络的计算模型。这种模型使得神经网络的研究分裂为两种不同研究思路。一种主要关注大脑中的生物学过程,另一种主要关注神经网络在人工智能里的应用。
赫布型学习
二十世纪40年代后期,心理学家唐纳德·赫布根据神经可塑性的机制创造了一种对学习的假说,现在称作赫布型学习。赫布型学习被认为是一种典型的非监督式学习规则,它后来的变种是长期增强作用的早期模型。从1948年开始,研究人员将这种计算模型的思想应用到B型图灵机上。
法利和韦斯利·A·克拉克(1954)首次使用计算机,当时称作计算器,在MIT模拟了一个赫布网络。
弗兰克·罗森布拉特(1956)创造了感知机。这是一种模式识别算法,用简单的加减法实现了两层的计算机学习网络。罗森布拉特也用数学符号描述了基本感知机里没有的回路,例如异或回路。这种回路一直无法被神经网络处理,直到Paul Werbos(1975)创造了反向传播算法。
在马文·明斯基和西摩·帕尔特(1969)发表了一项关于机器学习的研究以后,神经网络的研究停滞不前。他们发现了神经网络的两个关键问题。第一是基本感知机无法处理异或回路。第二个重要的问题是电脑没有足够的能力来处理大型神经网络所需要的很长的计算时间。直到计算机具有更强的计算能力之前,神经网络的研究进展缓慢。
反向传播算法与复兴
后来出现的一个关键的进展是反向传播算法(Werbos 1975)。这个算法有效地解决了异或的问题,还有更普遍的训练多层神经网络的问题。
在二十世纪80年代中期,分布式并行处理(当时称作联结主义)流行起来。David E. Rumelhart和James McClelland(1986)的教材对于联结主义在计算机模拟神经活动中的应用提供了全面的论述。
神经网络传统上被认为是大脑中的神经活动的简化模型,虽然这个模型和大脑的生理结构之间的关联存在争议。人们不清楚人工神经网络能多大程度地反映大脑的功能。
支持向量机和其他更简单的方法(例如线性分类器)在机器学习领域的流行度逐渐超过了神经网络,但是在2000年代后期出现的深度学习重新激发了人们对神经网络的兴趣。
2006年之后的进展
人们用CMOS创造了用于生物物理模拟和神经形态计算的计算装置。最新的研究显示了用于大型主成分分析和卷积神经网络的纳米装置具有良好的前景。如果成功的话,这会创造出一种新的神经计算装置,因为它依赖于学习而不是编程,并且它从根本上就是模拟的而不是数字化的,虽然它的第一个实例可能是数字化的CMOS装置。
在2009到2012年之间,Jürgen Schmidhuber在Swiss AI Lab IDSIA的研究小组研发的递归神经网络和深前馈神经网络赢得了8项关于模式识别和机器学习的国际比赛。例如,Alex Graves et al.的双向、多维的LSTM赢得了2009年ICDAR的3项关于连笔字识别的比赛,而且之前并不知道关于将要学习的3种语言的信息。
IDSIA的Dan Ciresan和同事根据这个方法编写的基于GPU的实现赢得了多项模式识别的比赛,包括IJCNN 2011交通标志识别比赛等等。他们的神经网络也是第一个在重要的基准测试中(例如IJCNN 2012交通标志识别和NYU的扬·勒丘恩(Yann LeCun)的MNIST手写数字问题)能达到或超过人类水平的人工模式识别器。
类似1980年Kunihiko Fukushima发明的neocognitron和视觉标准结构(由David H. Hubel和Torsten Wiesel在初级视皮层中发现的那些简单而又复杂的细胞启发)那样有深度的、高度非线性的神经结构可以被多伦多大学杰夫·辛顿实验室的非监督式学习方法所训练。
神经元
神经元示意图:
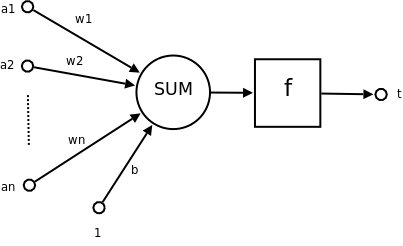
a1~an为输入向量的各个分量
w1~wn为神经元各个突触的权值
b为偏置
f为传递函数,通常为非线性函数。一般有traingd(),tansig(),hardlim()。以下默认为hardlim()
t为神经元输出
数学表示 t = f ( W ′ → → --> A → → --> + b ) {\displaystyle t=f({\vec {W"}}{\vec {A}}+b)}
W → → --> {\displaystyle {\vec {W}}} 为权向量 , W ′ → → --> {\displaystyle {\vec {W"}}} 为 W → → --> {\displaystyle {\vec {W}}} 的转置
A → → --> {\displaystyle {\vec {A}}} 为输入向量
b {\displaystyle b} 为偏置
f {\displaystyle f} 为传递函数
可见,一个神经元的功能是求得输入向量与权向量的内积后,经一个非线性传递函数得到一个标量结果。
单个神经元的作用:把一个n维向量空间用一个超平面分区成两部分(称之为判断边界),给定一个输入向量,神经元可以判断出这个向量位于超平面的哪一边。
该超平面的方程: W ′ → → --> p → → --> + b = 0 {\displaystyle {\vec {W"}}{\vec {p}}+b=0}
W → → --> {\displaystyle {\vec {W}}} 权向量
b {\displaystyle b} 偏置
p → → --> {\displaystyle {\vec {p}}} 超平面上的向量
神经元网络
单层神经元网络
是最基本的神经元网络形式,由有限个神经元构成,所有神经元的输入向量都是同一个向量。由于每一个神经元都会产生一个标量结果,所以单层神经元的输出是一个向量,向量的维数等于神经元的数目。
示意图:
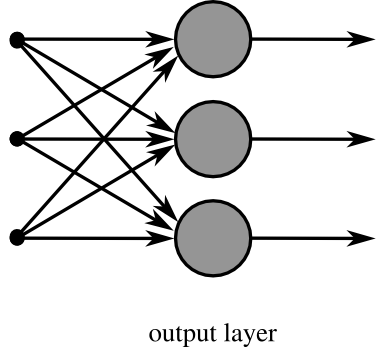
多层神经元网络
人工神经网络的实用性
人工神经网络是一个能够学习,能够总结归纳的系统,也就是说它能够通过已知数据的实验运用来学习和归纳总结。人工神经网络通过对局部情况的对照比较(而这些比较是基于不同情况下的自动学习和要实际解决问题的复杂性所决定的),它能够推理产生一个可以自动识别的系统。与之不同的基于符号系统下的学习方法,它们也具有推理功能,只是它们是创建在逻辑算法的基础上,也就是说它们之所以能够推理,基础是需要有一个推理算法则的集合。
人工神经元网络模型
通常来说,一个人工神经元网络是由一个多层神经元结构组成,每一层神经元拥有输入(它的输入是前一层神经元的输出)和输出,每一层(我们用符号记做)Layer(i)是由Ni(Ni代表在第i层上的N)个网络神经元组成,每个Ni上的网络神经元把对应在Ni-1上的神经元输出做为它的输入,我们把神经元和与之对应的神经元之间的连线用生物学的名称,叫做突触(英语:Synapse),在数学模型中每个突触有一个加权数值,我们称做权重,那么要计算第i层上的某个神经元所得到的势能等于每一个权重乘以第i-1层上对应的神经元的输出,然后全体求和得到了第i层上的某个神经元所得到的势能,然后势能数值通过该神经元上的激活函数(activation function,常是∑函数(英语:Sigmoid function)以控制输出大小,因为其可微分且连续,方便差量规则(英语:Delta rule)处理。求出该神经元的输出,注意的是该输出是一个非线性的数值,也就是说通过激励函数求的数值根据极限值来判断是否要激活该神经元,换句话说我们对一个神经元网络的输出是否线性不感兴趣。
基本结构
一种常见的多层结构的前馈网络(Multilayer Feedforward Network)由三部分组成,
输入层(Input layer),众多神经元(Neuron)接受大量非线形输入消息。输入的消息称为输入向量。
输出层(Output layer),消息在神经元链接中传输、分析、权衡,形成输出结果。输出的消息称为输出向量。
隐藏层(Hidden layer),简称“隐层”,是输入层和输出层之间众多神经元和链接组成的各个层面。隐层可以有多层,习惯上会用一层。隐层的节点(神经元)数目不定,但数目越多神经网络的非线性越显著,从而神经网络的强健性(robustness)(控制系统在一定结构、大小等的参数摄动下,维持某些性能的特性。)更显著。习惯上会选输入节点1.2至1.5倍的节点。
神经网络的类型已经演变出很多种,这种分层的结构也并不是对所有的神经网络都适用。
学习过程
通过训练样本的校正,对各个层的权重进行校正(learning)而创建模型的过程,称为自动学习过程(training algorithm)。具体的学习方法则因网络结构和模型不同而不同,常用反向传播算法(Backpropagation/倒传递/逆传播,以output利用一次微分Delta rule(英语:Delta rule)来修正weight)来验证。
参见:神经网络介绍
种类
人工神经网络分类为以下两种: 1.依学习策略(Algorithm)分类主要有:
监督式学习网络(Supervised Learning Network)为主
无监督式学习网络(Unsupervised Learning Network)
混合式学习网络(Hybrid Learning Network)
联想式学习网络(Associate Learning Network)
最适化学习网络(Optimization Application Network)
2.依网络架构(Connectionism)分类主要有:
前向式架构(Feed Forward Network)
回馈式架构(Recurrent Network)
强化式架构(Reinforcement Network)
理论性质
计算能力
多层感知器(MLP)是一个通用的函数逼近器,由Cybenko定理证明。然而,证明不是由所要求的神经元数量或权重来推断的。 Hava Siegelmann和Eduardo D. Sontag的工作证明了,一个具有有理数权重值的特定递归结构(与全精度实数权重值相对应)相当于一个具有有限数量的神经元和标准的线性关系的通用图灵机。 他们进一步表明,使用无理数权重值会产生一个超图灵机。
容量
人工神经网络模型有一个属性,称为“容量”,这大致相当于他们可以塑造任何函数的能力。它与可以被储存在网络中的信息的数量和复杂性相关。
收敛性
没有什么通常意义上的收敛,因为它取决于一些因素。首先,函数可能存在许多局部极小值。这取决于成本函数和模型。其次,使用优化方法在远离局部最小值时可能无法保证收敛。第三,对大量的数据或参数,一些方法变得不切实际。在一般情况下,我们发现,理论保证的收敛不能成为实际应用的一个可靠的指南。
综合统计
在目标是创建一个普遍系统的应用程序中,过度训练的问题出现了。这出现在回旋或过度具体的系统中当网络的容量大大超过所需的自由参数。为了避免这个问题,有两个方向:第一个是使用交叉验证和类似的技术来检查过度训练的存在和选择最佳参数如最小化泛化误差。二是使用某种形式的正规化。这是一个在概率化(贝叶斯)框架里出现的概念神经网络是人工智能,其中的正则化可以通过为简单模型选择一个较大的先验概率模型进行;而且在统计学习理论中,其目的是最大限度地减少了两个数量:“风险”和“结构风险”,相当于误差在训练集和由于过度拟合造成的预测误差。
参见
生物神经网络
人工智能
机器学习
感知机
 上一篇
上一篇 








